本文主要是介绍一种精确的基于DHT的p2p网络搜索算法与网络拓扑模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一种精确的基于DHT的p2p网络搜索算法与网络拓扑模型
关键字:p2p,搜索,DHT,网络拓扑
提要:本文对通行的DHT算法进行了修改,使之可以进行精确的查找,如关键字之间的逻辑运算等等,并在此基础上提出一个基于中央地址服务器的星型P2P拓扑结构模型。
版权声明:本文由SkyMountain发表,引用地址为http://blog.csdn.net/skymountain/。作者保留一切版权,转载务必注明出处,否则视作侵权。
一、目前的p2p搜索算法研究状况及其缺点
目前对于p2p系统的自动搜索算法研究已经成为p2p研究的一个热点。最初的p2p系统,如Napster,采用的是中心服务器式的搜索算法,在这样的系统中,中央搜索服务器很容易就成为系统性能的瓶颈和不稳定的根源。其后的一些系统,如Gnutella,采用的是分布式的搜索算法,查找按照简单洪泛(flooding)的方式进行。查找命令首先传播到用户的所有相邻结点,然后再传播到相邻节点的相邻节点,直到达到预先确定的层次为止。这样的查找算法无疑会造成巨大的带宽和资源浪费。
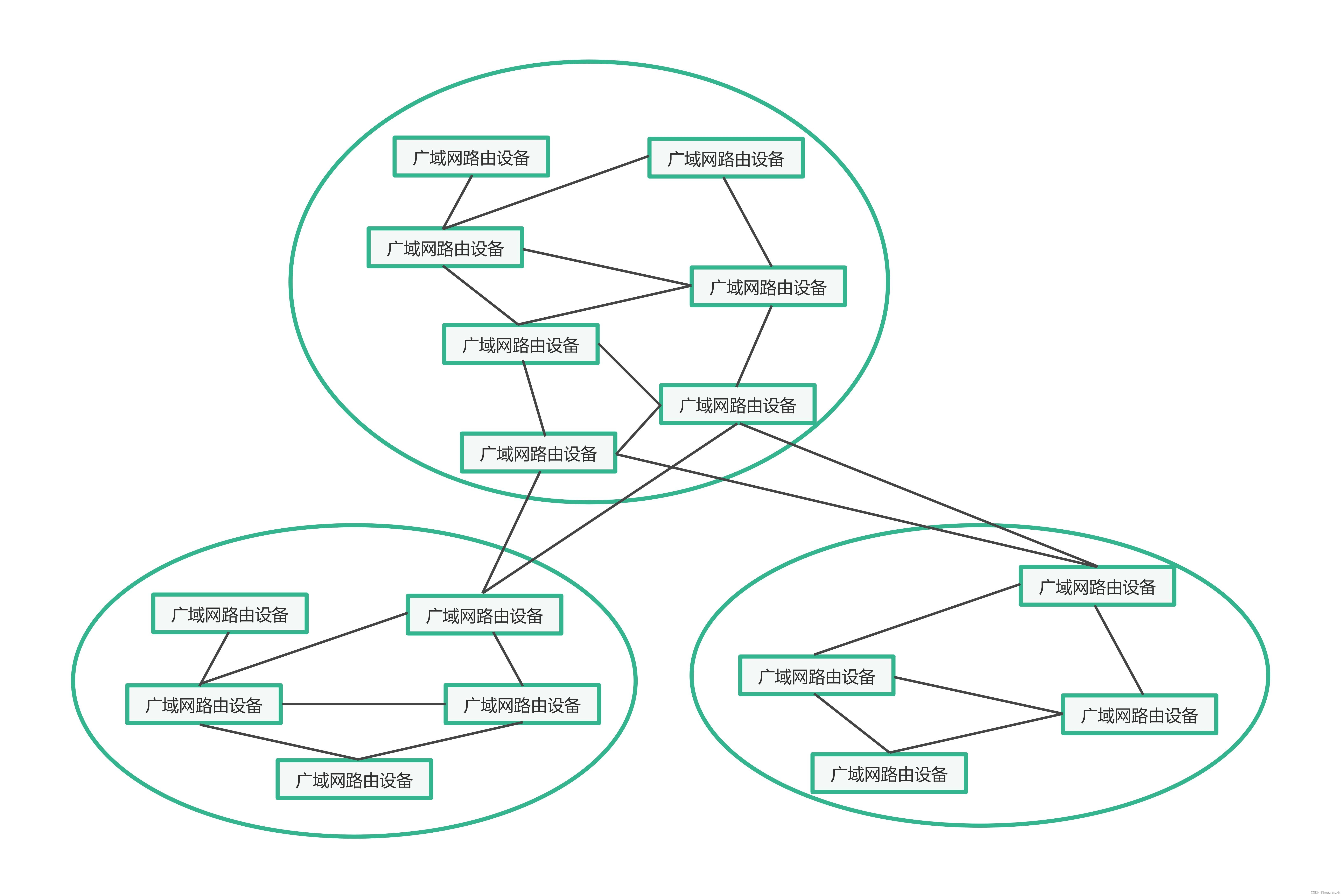
现在的分布式p2p系统普遍采取的是DHT(Distributed Hash Table,分布式哈希表)搜索方法。该方法的思想是:每一份资源都由一组关键字进行标识。系统对其中的每一个关键字进行hash,根据hash的结果决定此关键字对应的那条信息由哪个用户负责储存。用户搜索的时候,用同样的算法计算出每个关键字的hash,再根据hash知道该关键字对应信息的储存位置,从而能够迅速定位资源的位置。下面举例说明。
例如某份文件名为“雪狼湖.mp3“。当用户共享此文件时,客户端把“雪狼湖.mp3“这个字符串进行分词,结果可能是"雪","狼","湖","mp3"(其中点号已经被自动去掉)四个词。我们假设上面几个词的hash结果分别为15,26,37,48。DHT一般规定系统中第一个id号比
这篇关于一种精确的基于DHT的p2p网络搜索算法与网络拓扑模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!