本文主要是介绍YOLOv8改进 | 2023注意力篇 | iRMB倒置残差块注意力机制(轻量化注意力机制),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、本文介绍
本文给家大家带来的改进机制是iRMB,其是在论文Rethinking Mobile Block for Efficient Attention-based Models种提出,论文提出了一个新的主干网络EMO(后面我也会教大家如何使用该主干,本文先教大家使用该文中提出的注意力机制)。其主要思想是将轻量级的CNN架构与基于注意力的模型结构相结合(有点类似ACmix),我将iRMB和C2f结合,然后也将其用在了检测头种进行尝试,三种结果进行对比,针对的作用也不相同,但是无论那种实验均有一定涨点效果,同时该注意力机制属于是比较轻量化的参数量比较小,训练速度也很快,后面我会将各种添加方法教给大家,让大家在自己的模型中进行复现。
推荐指数:⭐⭐⭐⭐⭐
涨点效果:⭐⭐⭐⭐⭐
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备
训练结果对比图->

目录
一、本文介绍
二、iRMB的框架原理
2.1 iRMB结构
2.2 倒置残差块
2.3 元移动块(Meta-Mobile Block)
三、iRMB的核心代码
四、手把手教你添加iRMB和C2f_iRMB机制
4.1 步骤一
4.2 步骤二
4.3 步骤三
五、iRMB和C2f_iRMB的yaml文件和运行记录
5.1 yaml版本一(推荐)
5.2 yaml版本二
5.3 yaml版本三
5.4 推荐iRMB可添加的位置
5.5 iRMB的训练过程截图
五、本文总结
二、iRMB的框架原理

官方论文地址:官方论文地址点击即可跳转
官方代码地址:官方代码地址点击即可跳转

iRMB(Inverted Residual Mobile Block)的主要思想是将轻量级的CNN架构与基于注意力的模型结构相结合(有点类似ACmix),以创建高效的移动网络。iRMB通过重新考虑倒置残差块(IRB)和Transformer的有效组件,实现了一种统一的视角,从而扩展了CNN的IRB到基于注意力的模型。iRMB的设计目标是在保持模型轻量级的同时,实现对计算资源的有效利用和高准确率。这一方法通过在下游任务上的广泛实验得到验证,展示出其在轻量级模型领域的优越性能。
iRMB的主要创新点在于以下三点:
1. 结合CNN的轻量级特性和Transformer的动态模型能力,创新提出了iRMB结构,适用于移动设备上的密集预测任务。
2. 使用倒置残差块设计,扩展了传统CNN的IRB到基于注意力的模型,增强了模型处理长距离信息的能力。
3. 提出了元移动块(Meta-Mobile Block),通过不同的扩展比率和高效操作符,实现了模型的模块化设计,使得模型更加灵活和高效。
2.1 iRMB结构
iRMB 结构的主要创新点是它结合了卷积神经网络(CNN)的轻量级特性和 Transformer 模型的动态处理能力。这种结构特别适用于移动设备上的密集预测任务,因为它旨在在计算能力有限的环境中提供高效的性能。iRMB 通过其倒置残差设计改进了信息流的处理,允许在保持模型轻量的同时捕捉和利用长距离依赖,这对于图像分类、对象检测和语义分割等任务至关重要。这种设计使得模型在资源受限的设备上也能高效运行,同时保持或提高预测准确性。
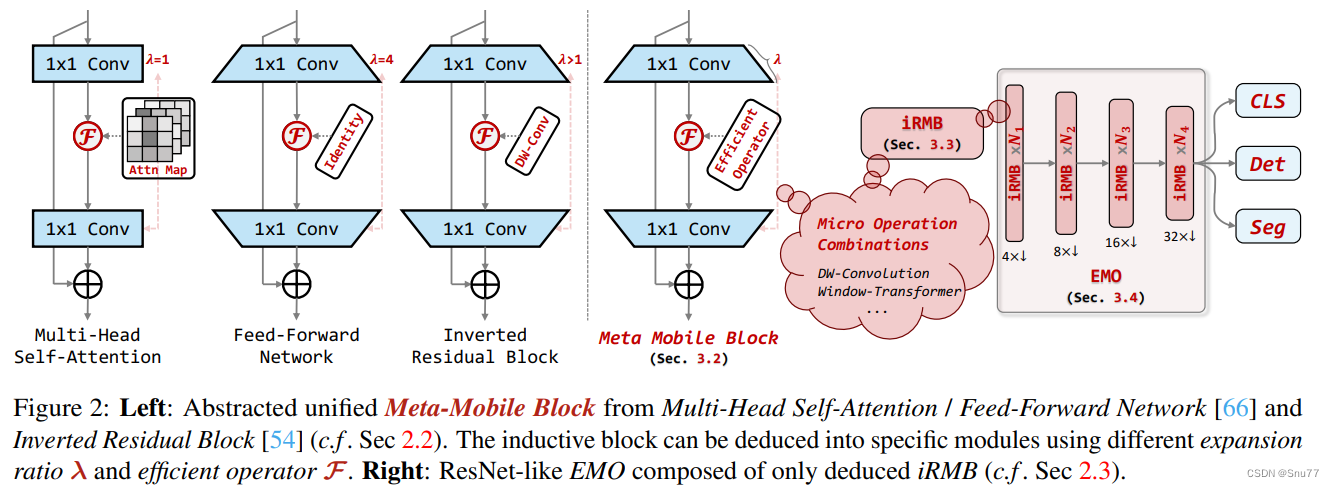
上面的图片来自与论文的图片2展示了iRMB(Inverted Residual Mobile Block)的设计理念和结构。左侧是从多头自注意力和前馈网络中抽象出的统一元移动块(Meta-Mobile Block),它将不同扩展比率和高效操作符结合起来,形成特定的模块。右侧是基于iRMB构建的类似ResNet的高效模型(EMO),它仅由推导出的iRMB组成,并用于各种下游任务,如分类(CLS)、检测(Det)和分割(Seg)。这种设计实现了模型的轻量化,同时保持了良好的性能和效率。
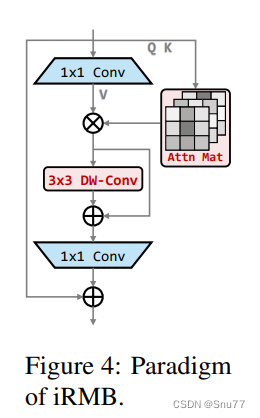
这幅图展示了iRMB(Inverted Residual Mobile Block)的结构范式。iRMB是一种混合网络模块,它结合了深度可分离卷积(3x3 DW-Conv)和自注意力机制。1x1卷积用于通道数的压缩和扩张,以此优化计算效率。深度可分离卷积(DW-Conv)用于捕捉空间特征,而注意力机制则用于捕获特征间的全局依赖关系。
2.2 倒置残差块
在iRMB设计中,使用倒置残差块(IRB)的概念被扩展到了基于注意力的模型中。这使得模型能够更有效地处理长距离信息,这是因为自注意力机制能够捕获输入数据中不同部分之间的全局依赖关系。传统的CNN通常只能捕捉到局部特征,而通过引入注意力机制,iRMB能够在提取特征时考虑到整个输入空间,增强了模型对复杂数据模式的理解能力,特别是在处理视觉和序列数据时。这种结合了传统CNN的轻量化和Transformer的长距离建模能力的设计,为在资源受限的环境中实现高效的深度学习模型提供了新的可能性(文章中并没有关于IRB的结构图)。
2.3 元移动块(Meta-Mobile Block)
元移动块(Meta-Mobile Block),它通过不同的扩展比率和高效操作符实现模块化设计。这种方法使得模型可以根据需要调整其容量,而无需重新设计整个网络。元移动块的核心理念是通过可插拔的方式,将不同的操作如卷积、自注意力等集成到一个统一的框架中,从而提高模型的效率和灵活性。这允许模型在复杂性和计算效率之间进行更好的权衡,特别适用于那些需要在有限资源下运行的应用。
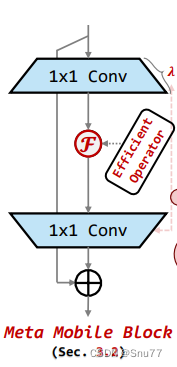
图中展示的是Meta Mobile Block的设计。在这个构件中,1x1的卷积层被用来改变特征图的通道数,从而控制网络的容量。中间的“Efficient Operator”是一个高效的运算符,可以是自注意力机制或其他任何高效的层或操作。这种设计使得Meta Mobile Block能够灵活地适应不同的任务需求,并保持高效的计算性能。通过这样的模块化,网络能够在不同的环境和任务中进行快速调整和优化。
三、iRMB的核心代码
该代码的使用方式我们看章节四来进行使用,其中包含C2f_iRMB和iRMB本体注意力机制。
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from functools import partial
from einops import rearrange
from timm.models._efficientnet_blocks import SqueezeExcite
from timm.models.layers import DropPathinplace = Trueclass LayerNorm2d(nn.Module):def __init__(self, normalized_shape, eps=1e-6, elementwise_affine=True):super().__init__()self.norm = nn.LayerNorm(normalized_shape, eps, elementwise_affine)def forward(self, x):x = rearrange(x, 'b c h w -> b h w c').contiguous()x = self.norm(x)x = rearrange(x, 'b h w c -> b c h w').contiguous()return xdef get_norm(norm_layer='in_1d'):eps = 1e-6norm_dict = {'none': nn.Identity,'in_1d': partial(nn.InstanceNorm1d, eps=eps),'in_2d': partial(nn.InstanceNorm2d, eps=eps),'in_3d': partial(nn.InstanceNorm3d, eps=eps),'bn_1d': partial(nn.BatchNorm1d, eps=eps),'bn_2d': partial(nn.BatchNorm2d, eps=eps),# 'bn_2d': partial(nn.SyncBatchNorm, eps=eps),'bn_3d': partial(nn.BatchNorm3d, eps=eps),'gn': partial(nn.GroupNorm, eps=eps),'ln_1d': partial(nn.LayerNorm, eps=eps),'ln_2d': partial(LayerNorm2d, eps=eps),}return norm_dict[norm_layer]def get_act(act_layer='relu'):act_dict = {'none': nn.Identity,'relu': nn.ReLU,'relu6': nn.ReLU6,'silu': nn.SiLU}return act_dict[act_layer]class ConvNormAct(nn.Module):def __init__(self, dim_in, dim_out, kernel_size, stride=1, dilation=1, groups=1, bias=False,skip=False, norm_layer='bn_2d', act_layer='relu', inplace=True, drop_path_rate=0.):super(ConvNormAct, self).__init__()self.has_skip = skip and dim_in == dim_outpadding = math.ceil((kernel_size - stride) / 2)self.conv = nn.Conv2d(dim_in, dim_out, kernel_size, stride, padding, dilation, groups, bias)self.norm = get_norm(norm_layer)(dim_out)self.act = get_act(act_layer)(inplace=inplace)self.drop_path = DropPath(drop_path_rate) if drop_path_rate else nn.Identity()def forward(self, x):shortcut = xx = self.conv(x)x = self.norm(x)x = self.act(x)if self.has_skip:x = self.drop_path(x) + shortcutreturn xclass iRMB(nn.Module):def __init__(self, dim_in, dim_out, norm_in=True, has_skip=True, exp_ratio=1.0, norm_layer='bn_2d',act_layer='relu', v_proj=True, dw_ks=3, stride=1, dilation=1, se_ratio=0.0, dim_head=8, window_size=7,attn_s=True, qkv_bias=False, attn_drop=0., drop=0., drop_path=0., v_group=False, attn_pre=False):super().__init__()self.norm = get_norm(norm_layer)(dim_in) if norm_in else nn.Identity()dim_mid = int(dim_in * exp_ratio)self.has_skip = (dim_in == dim_out and stride == 1) and has_skipself.attn_s = attn_sif self.attn_s:assert dim_in % dim_head == 0, 'dim should be divisible by num_heads'self.dim_head = dim_headself.window_size = window_sizeself.num_head = dim_in // dim_headself.scale = self.dim_head ** -0.5self.attn_pre = attn_preself.qk = ConvNormAct(dim_in, int(dim_in * 2), kernel_size=1, bias=qkv_bias, norm_layer='none',act_layer='none')self.v = ConvNormAct(dim_in, dim_mid, kernel_size=1, groups=self.num_head if v_group else 1, bias=qkv_bias,norm_layer='none', act_layer=act_layer, inplace=inplace)self.attn_drop = nn.Dropout(attn_drop)else:if v_proj:self.v = ConvNormAct(dim_in, dim_mid, kernel_size=1, bias=qkv_bias, norm_layer='none',act_layer=act_layer, inplace=inplace)else:self.v = nn.Identity()self.conv_local = ConvNormAct(dim_mid, dim_mid, kernel_size=dw_ks, stride=stride, dilation=dilation,groups=dim_mid, norm_layer='bn_2d', act_layer='silu', inplace=inplace)self.se = SqueezeExcite(dim_mid, rd_ratio=se_ratio, act_layer=get_act(act_layer)) if se_ratio > 0.0 else nn.Identity()self.proj_drop = nn.Dropout(drop)self.proj = ConvNormAct(dim_mid, dim_out, kernel_size=1, norm_layer='none', act_layer='none', inplace=inplace)self.drop_path = DropPath(drop_path) if drop_path else nn.Identity()def forward(self, x):shortcut = xx = self.norm(x)B, C, H, W = x.shapeif self.attn_s:# paddingif self.window_size <= 0:window_size_W, window_size_H = W, Helse:window_size_W, window_size_H = self.window_size, self.window_sizepad_l, pad_t = 0, 0pad_r = (window_size_W - W % window_size_W) % window_size_Wpad_b = (window_size_H - H % window_size_H) % window_size_Hx = F.pad(x, (pad_l, pad_r, pad_t, pad_b, 0, 0,))n1, n2 = (H + pad_b) // window_size_H, (W + pad_r) // window_size_Wx = rearrange(x, 'b c (h1 n1) (w1 n2) -> (b n1 n2) c h1 w1', n1=n1, n2=n2).contiguous()# attentionb, c, h, w = x.shapeqk = self.qk(x)qk = rearrange(qk, 'b (qk heads dim_head) h w -> qk b heads (h w) dim_head', qk=2, heads=self.num_head,dim_head=self.dim_head).contiguous()q, k = qk[0], qk[1]attn_spa = (q @ k.transpose(-2, -1)) * self.scaleattn_spa = attn_spa.softmax(dim=-1)attn_spa = self.attn_drop(attn_spa)if self.attn_pre:x = rearrange(x, 'b (heads dim_head) h w -> b heads (h w) dim_head', heads=self.num_head).contiguous()x_spa = attn_spa @ xx_spa = rearrange(x_spa, 'b heads (h w) dim_head -> b (heads dim_head) h w', heads=self.num_head, h=h,w=w).contiguous()x_spa = self.v(x_spa)else:v = self.v(x)v = rearrange(v, 'b (heads dim_head) h w -> b heads (h w) dim_head', heads=self.num_head).contiguous()x_spa = attn_spa @ vx_spa = rearrange(x_spa, 'b heads (h w) dim_head -> b (heads dim_head) h w', heads=self.num_head, h=h,w=w).contiguous()# unpaddingx = rearrange(x_spa, '(b n1 n2) c h1 w1 -> b c (h1 n1) (w1 n2)', n1=n1, n2=n2).contiguous()if pad_r > 0 or pad_b > 0:x = x[:, :, :H, :W].contiguous()else:x = self.v(x)x = x + self.se(self.conv_local(x)) if self.has_skip else self.se(self.conv_local(x))x = self.proj_drop(x)x = self.proj(x)x = (shortcut + self.drop_path(x)) if self.has_skip else xreturn xdef autopad(k, p=None, d=1): # kernel, padding, dilation"""Pad to 'same' shape outputs."""if d > 1:k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-sizeif p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass Conv(nn.Module):"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""default_act = nn.SiLU() # default activationdef __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):"""Initialize Conv layer with given arguments including activation."""super().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):"""Apply convolution, batch normalization and activation to input tensor."""return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):"""Perform transposed convolution of 2D data."""return self.act(self.conv(x))class Bottleneck(nn.Module):"""Standard bottleneck."""def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, andexpansion."""super().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, k[0], 1)self.cv2 = Conv(c_, c2, k[1], 1, g=g)self.add = shortcut and c1 == c2self.iRMB = iRMB(c2, c2)def forward(self, x):"""'forward()' applies the YOLO FPN to input data."""return x + self.iRMB(self.cv2(self.cv1(x))) if self.add else self.iRMB(self.cv2(self.cv1(x)))class C2f_iRMB(nn.Module):"""Faster Implementation of CSP Bottleneck with 2 convolutions."""def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,expansion."""super().__init__()self.c = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, 2 * self.c, 1, 1)self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))def forward(self, x):"""Forward pass through C2f layer."""y = list(self.cv1(x).chunk(2, 1))y.extend(m(y[-1]) for m in self.m)return self.cv2(torch.cat(y, 1))def forward_split(self, x):"""Forward pass using split() instead of chunk()."""y = list(self.cv1(x).split((self.c, self.c), 1))y.extend(m(y[-1]) for m in self.m)return self.cv2(torch.cat(y, 1))if __name__ == "__main__":# Generating Sample imageimage_size = (1, 64, 640, 640)image = torch.rand(*image_size)# Modelmodel = iRMB(64, 64)out = model(image)print(len(out))四、手把手教你添加iRMB和C2f_iRMB机制
4.1 步骤一
首先我们找到如下的目录'ultralytics/nn/modules',然后在这个目录下创建一个py文件,名字可以根据你自己的习惯起,然后将iRMB和C2f_iRMB的核心代码复制进去。
4.2 步骤二
之后我们找到'ultralytics/nn/tasks.py'文件,在其中注册我们的iRMB和C2f_iRMB模块。
首先我们需要在文件的开头导入我们的iRMB和C2f_iRMB模块,如下图所示->
4.3 步骤三
我们找到parse_model这个方法,可以用搜索(Ctrl + F)也可以自己手动找,大概在六百多行吧。 我们找到如下的地方,然后将iRMB和C2f_iRMB添加进去即可,模仿我添加即可。
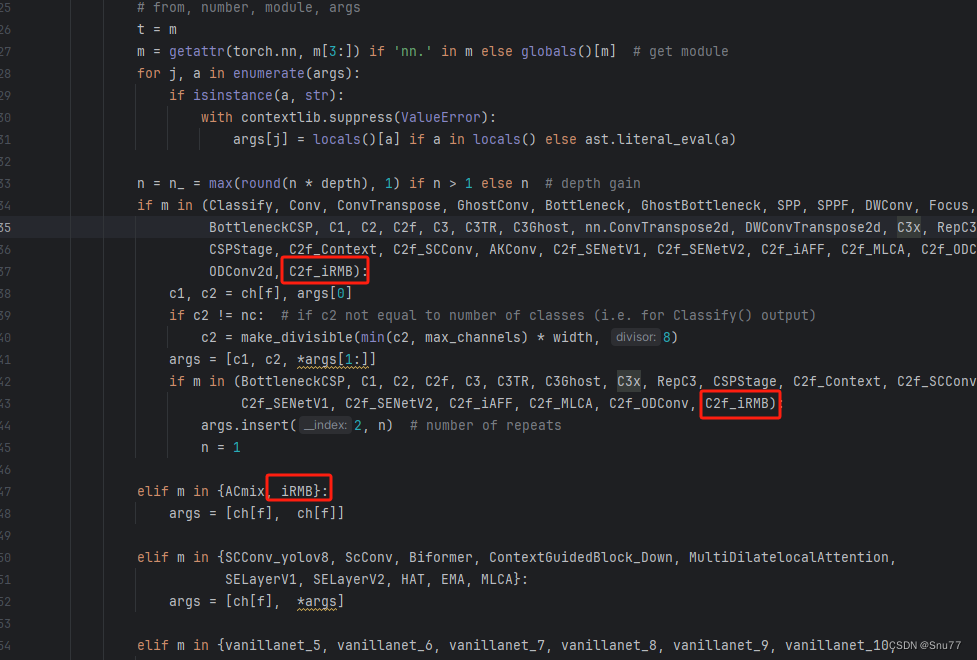
elif m in {iRMB}:args = [ch[f], ch[f]]
到此我们就注册成功了。
五、iRMB和C2f_iRMB的yaml文件和运行记录
下面推荐几个版本的yaml文件给大家,大家可以复制进行训练,但是组合用很多具体那种最有效果都不一定,针对不同的数据集效果也不一样,我下面推荐了几种我自己认为可能有效果的配合方式,你也可以自己进行组合。
5.1 yaml版本一(推荐)
下面的添加是我实验结果的版本,这个不一定是有效果的但是是我做过实验的版本。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOP# YOLOv8.0 backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f_iRMB, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f_iRMB, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f_iRMB, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f_iRMB, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)5.2 yaml版本二
添加的版本二具体那种适合你需要大家自己多做实验来尝试。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOP# YOLOv8.0 backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f_iRMB, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f_iRMB, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f_iRMB, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f_iRMB, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f_iRMB, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f_iRMB, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f_iRMB, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f_iRMB, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)5.3 yaml版本三
下面我在三个目标检测层输出侧添加了三个该注意力机制,大家可以根据自身的检测目标任务进行修改。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOP# YOLOv8.0 backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, iRMB, []] # 16- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 19 (P4/16-medium)- [-1, 1, iRMB, []] # 20- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 23 (P5/32-large)- [-1, 1, iRMB, []] # 24- [[16, 20, 24], 1, Detect, [nc]] # Detect(P3, P4, P5)5.4 推荐iRMB可添加的位置
在YOLOv8种我们的可以改进的位置有很多,不同添加的位置效果也不同,所以我下面推荐几个添加的位,置大家可以进行参考,当然不一定要按照我推荐的地方添加。
残差连接中:在残差网络的残差连接中加入注意力机制或者替换其中的卷积。
Neck部分:YOLOv8的Neck部分负责特征融合,这里添加注意力机制可以帮助模型更有效地融合不同层次的特征,让模型更关注那些有用的特征。
Backbone:可以替换中干网络中的卷积部分
能添加的位置很多,一篇文章很难全部介绍到,后期我会发文件里面集成上百种的改进机制,然后还有许多融合模块,给大家。
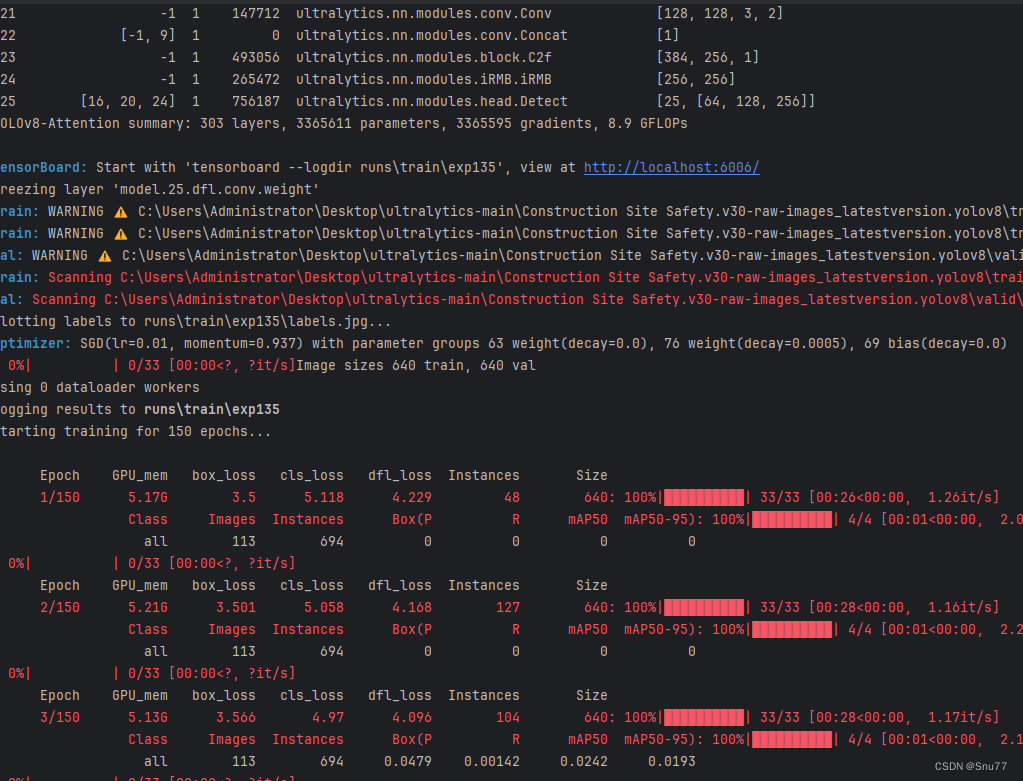
5.5 iRMB的训练过程截图
大家可以看下面的运行结果和添加的位置所以不存在我发的代码不全或者运行不了的问题大家有问题也可以在评论区评论我看到都会为大家解答(我知道的)。
五、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv8改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备

这篇关于YOLOv8改进 | 2023注意力篇 | iRMB倒置残差块注意力机制(轻量化注意力机制)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




