本文主要是介绍图像增强论文阅读笔记——DALE : Dark Region-Aware Low-light Image Enhancement,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
DALE : Dark Region-Aware Low-light Image Enhancement
- 1. 介绍
- 2. 提出的方法
1. 介绍
本文提出了一种新的微光图像增强方法,即暗区感知微光图像增强(dark region-aware微光图像增强,DALE),该方法通过所提出的视觉注意模块准确识别暗区,增强暗区亮度。该方法利用超像素进行视觉注意估计,无需复杂的过程。因此,该方法可以保持原始图像的颜色、色调和亮度,并防止图像中正常照明区域的饱和和扭曲。实验结果表明,该方法能够通过视觉注意准确识别暗区,在定性和定量方面都优于目前最先进的方法。
本文构造了一个新的数据集,它可以用来学习视觉注意图。然后,该方法增强了暗区亮度,通过视觉注意图可以识别暗区。我们合成不同照明超像素,生成局部照明图像数据集,如图1(b)所示。因此,我们的方法可以比现有的基于深度学习的方法产生更精确的微光增强图像。图1©显示了一个估计的视觉注意图,其中暗区被准确识别并使用大值描述。
本文的贡献如下:
- 提出了一个新的注意力模块来识别黑暗区域。
- 提出了一种新的利用视觉注意图的弱光增强方法DELA。我们的方法可以在保持其他区域亮度的同时,强烈增强暗区亮度。
- 提供了一个局部照明的图像数据集,所有实验都使用了该数据集。这个数据集将公开提供,以重新训练传统的弱光增强方法并提高其准确性。
2. 提出的方法
该网络结构由视觉注意网络(VAN)、增强网络(EN)和残留块(RB)组成。
本文提出的微光增强网络由暗区域注意网络和增强网络两部分组成,如图所示。暗区域注意网络生成的注意图可以识别暗区,而增强网络输出的是弱光增强图像。

视觉注意网络(VAN): 提出的VAN采用U-Net结构(即编解码器)作为骨干网。第一个卷积层的kernel大小为3 × 3, stride为1。
编码器有三个卷积层、残差块和两个下采样层。
残差块由大小为1 × 1的核的卷积层ReLUs和压缩激励块[9]组成,这些卷积层具有不同的膨胀因子(即3、2、1)。
解码器有三个卷积层、残差块和两个上采样层。残差块使用不同的膨胀因子(即1、2、3)。
Enhancement Network (EN): 该网络利用估计的暗区域视觉注意图提高了微光图像的亮度。该算法以弱光图像和视觉注意图的拼接为输入。与VAN类似,所有的卷积层都有一个stride为1的内核3×3 size。三个残差块使用3到1的不同膨胀因子,将所有残差块串联起来进行信息融合。
视觉注意网络(VAN)损失函数:
- l2 损失(估计的暗区注意力图VA(Ilocal) 和真实图IVAGT)
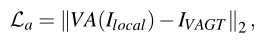
光照估计方法: 提出了一种基于超像素的局部光照合成方法,我们对每个超像素应用随机不同的照明水平,并合成低光和正常照明区域。此外,由于超像素可以描述物体的形状,所以该方法可以根据物体边界合成局部光照。利用超像素进行局部光照合成的公式如下:
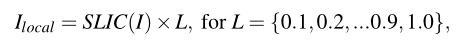
式中,SLIC函数输出图像 I 的超像素。L为光照权重。
当L = 1.0时,保持原来的亮度。
如果L = 0.1,对应的超像素会明显变暗。
这些合成数据被用来训练黑暗感知的注意力网络
超像素和SLIC不太了解的可以看这篇博客
视觉注意力图: 本文是一种针对图像暗区进行微光图像增强的视觉注意方法(即暗区域注意网络)。为了对所提出的暗区域注意网络进行监督训练,我们合成ground-truth注意图IVA,如下所示:
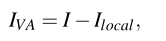
式中的 I 和 Ilocal分别表示原始图像和局部光照图像。
局部光照和各种形式的超像素使得所提出的注意网络能够在训练过程中学习各种类型的明暗区域。
下图是我的测试结果

暗区域增强网络:
这篇关于图像增强论文阅读笔记——DALE : Dark Region-Aware Low-light Image Enhancement的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







