本文主要是介绍ArcGIS批量计算shp面积并导出shp数据总面积(建模法),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在处理shp数据时, 又是我们需要知道许多个shp字段的批量计算,例如计算shp的总面积、面积平均值等,但是单个查看shp文件的属性进行汇总过于繁琐,因此可以借助建模批处理来计算。
首先准备数据:一个含有多个shp的文件夹。
点击如下图所示的按钮建立一个新的模型。
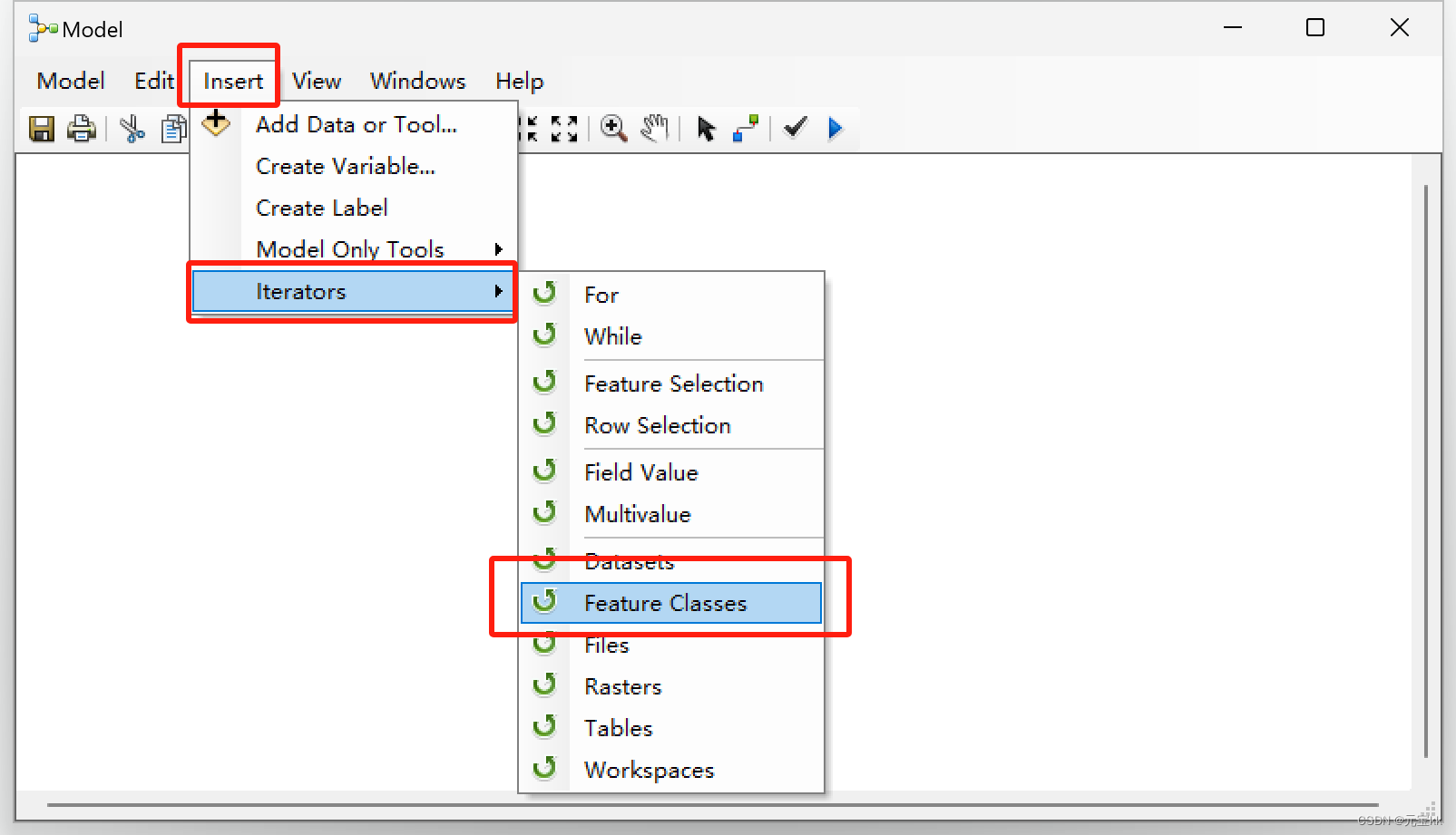
加入迭代器,Insert——Iterators——Feature Classes
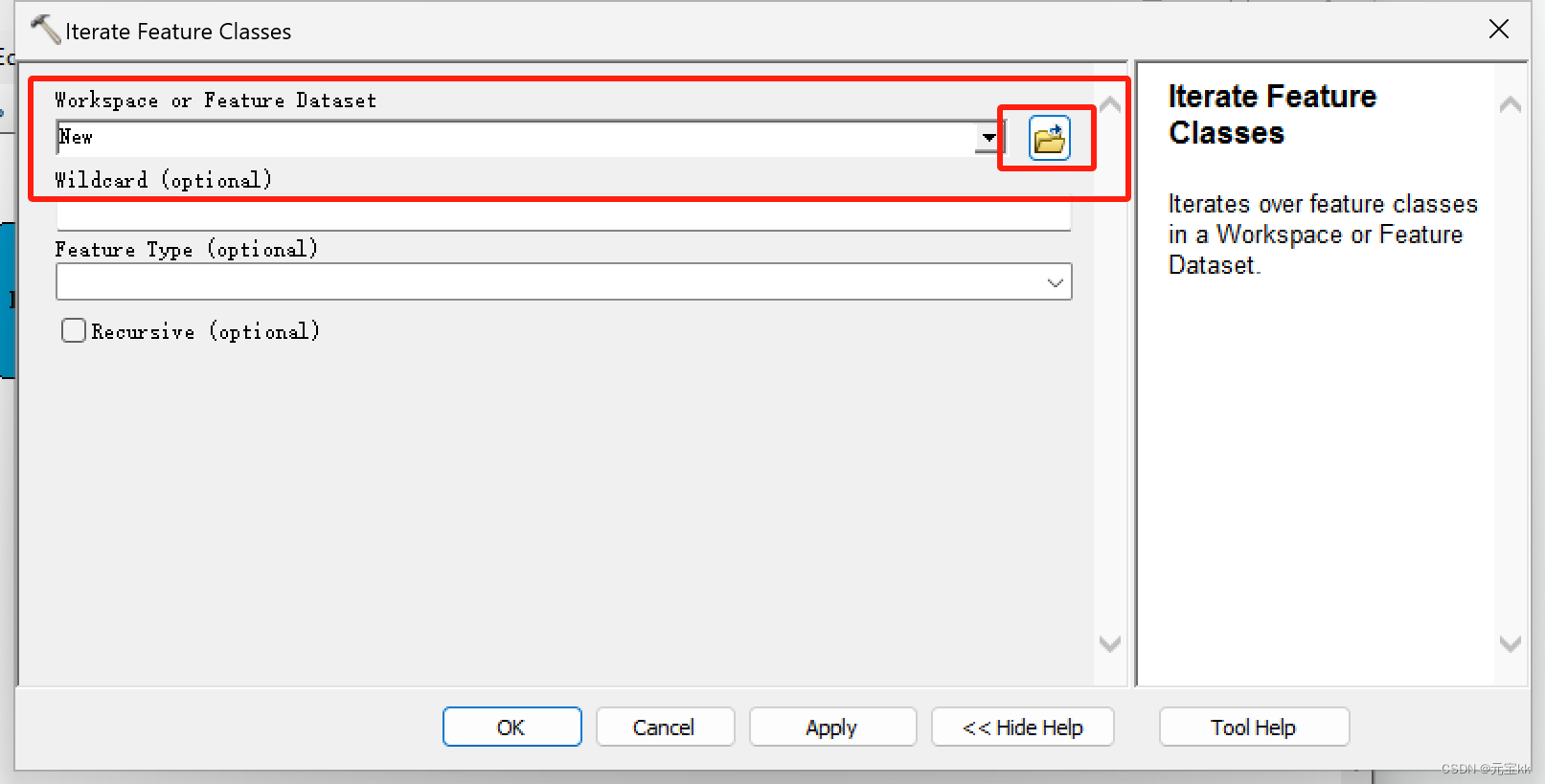
双击Iterate Feature Classes,在弹出的窗口中Workspace or Featwre Iataset下选择对应的shp文件夹。
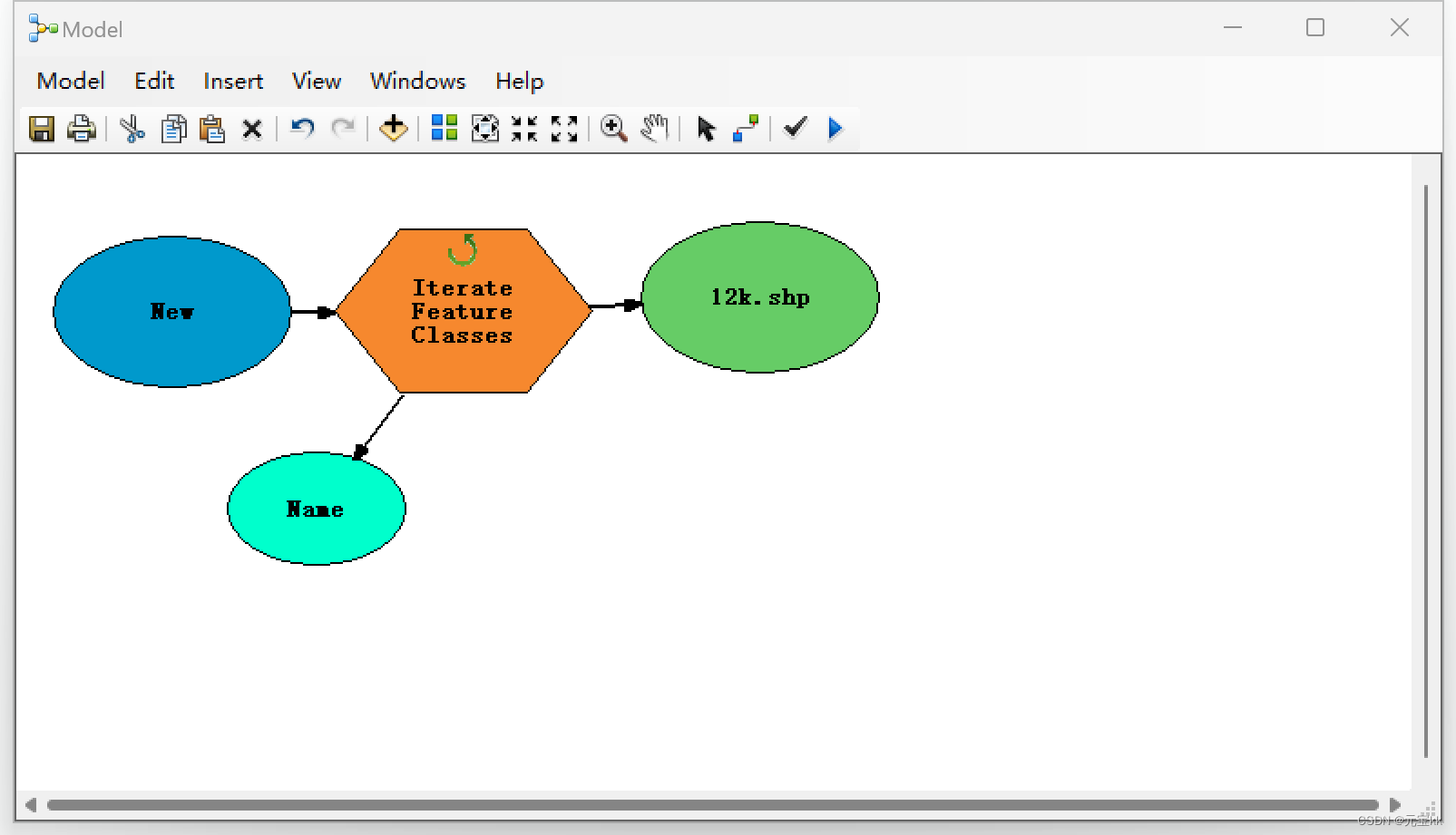
若shp文件没有面积字段,则需添加字段,并计算面积。
ArcToolbox——Data Management Tools——Fields——Add Field
ArcToolbox——Data Management Tools——Fields——Calculate Field
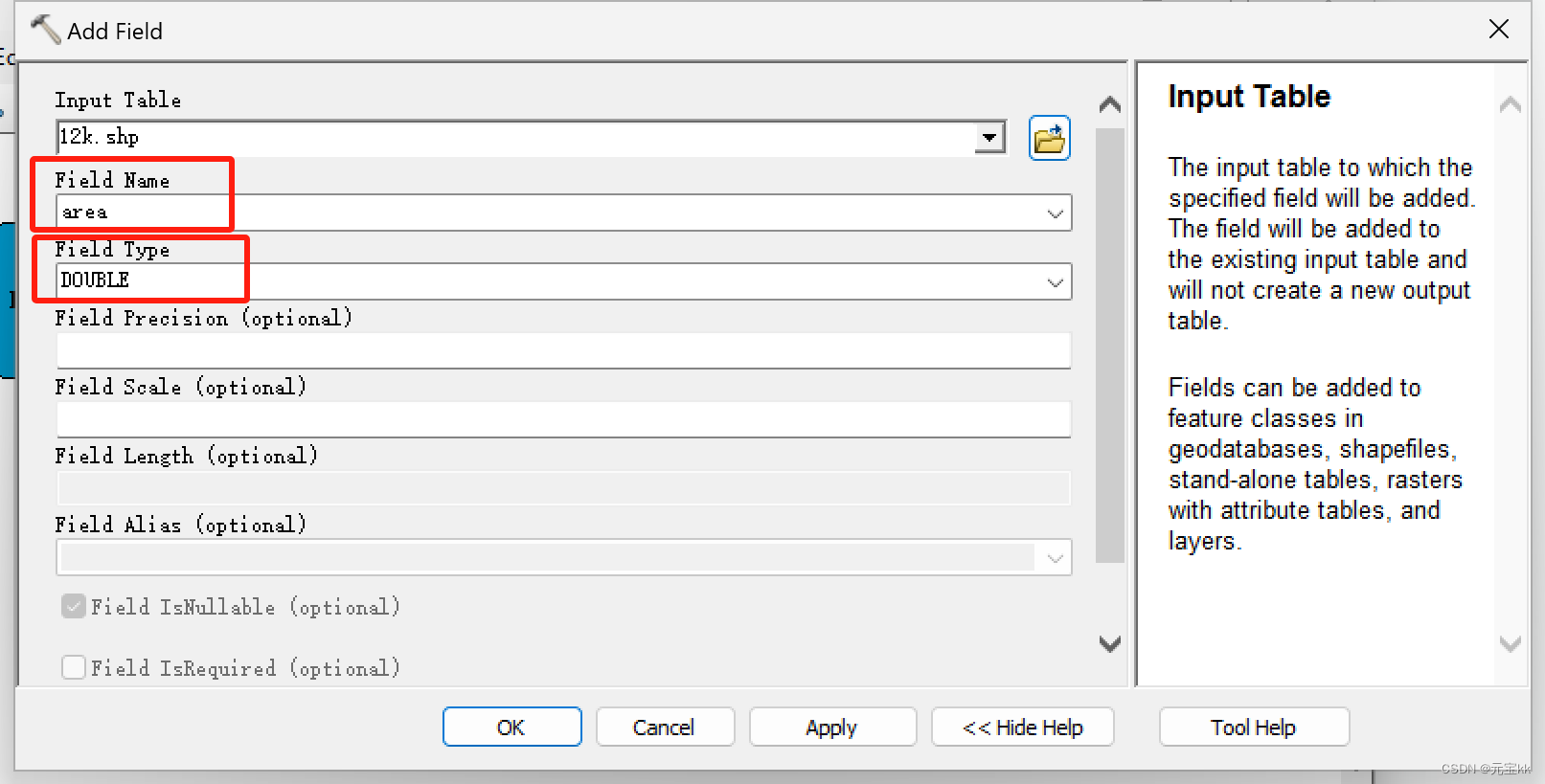
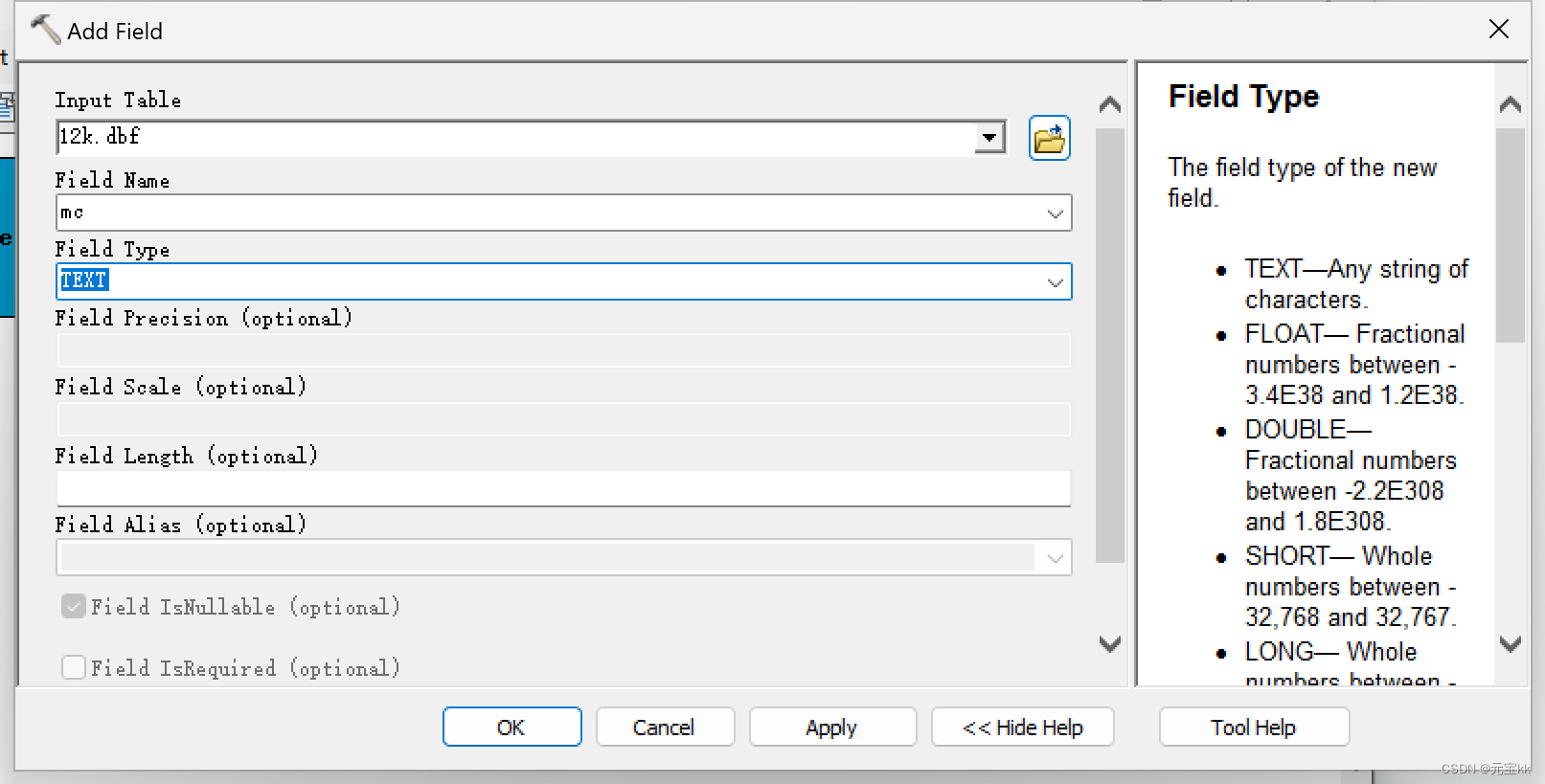
将两个工具拖入模型中,Input Table中选择迭代的shp文件,Field Name 设置为你想命名的名字,Field Type 选择DOUBLE。
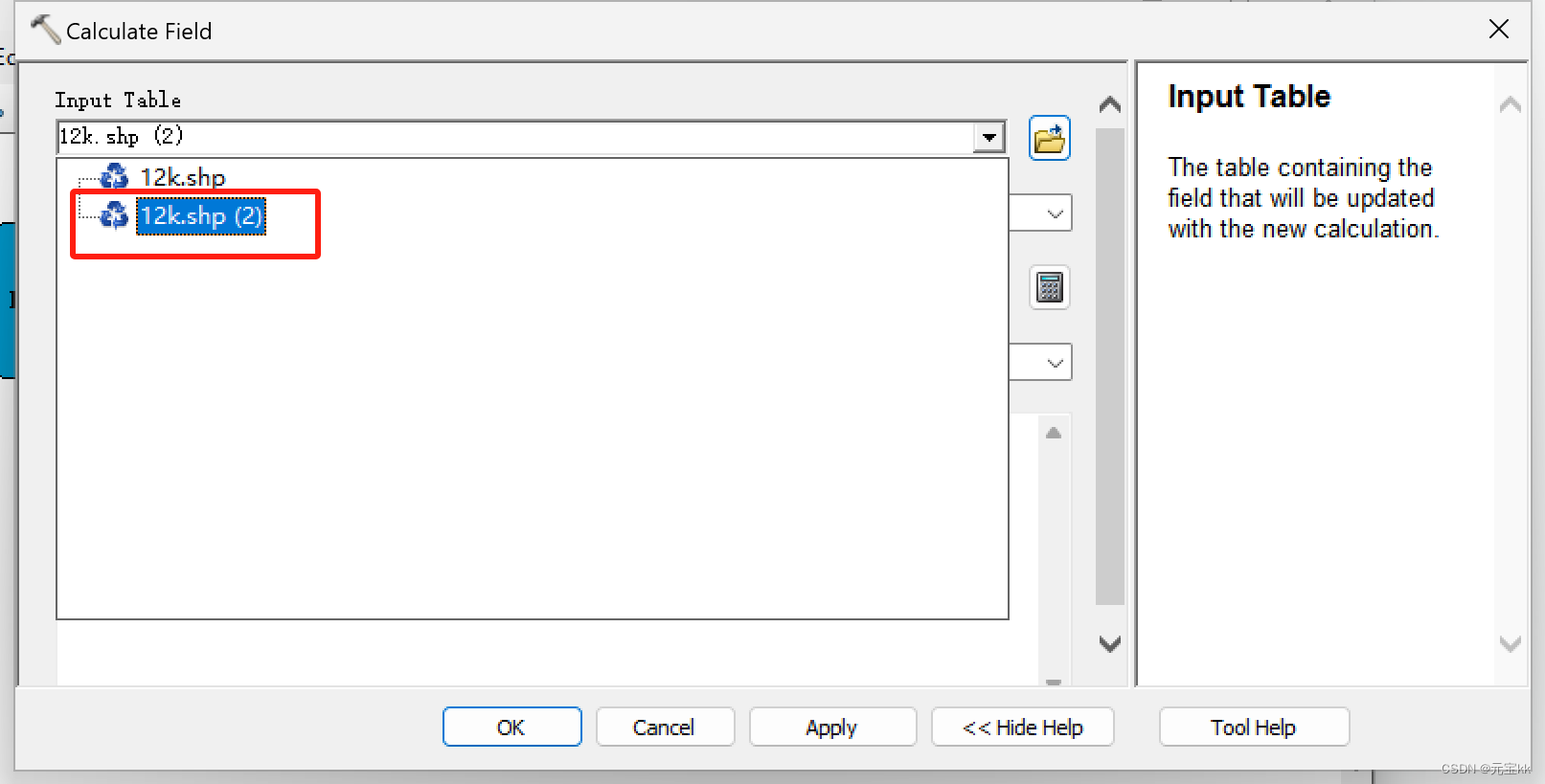
将Calculate Field拖入模型中,其中这里的迭代文件要选择添加过字段的新shp文件,Field Name选择新加的字段名字,Expression填写为!Shape.Area!,Expression Type 选择PYTHON。这里如果你要计算别的几何内容,也可以有别的计算公式,详情参考链接
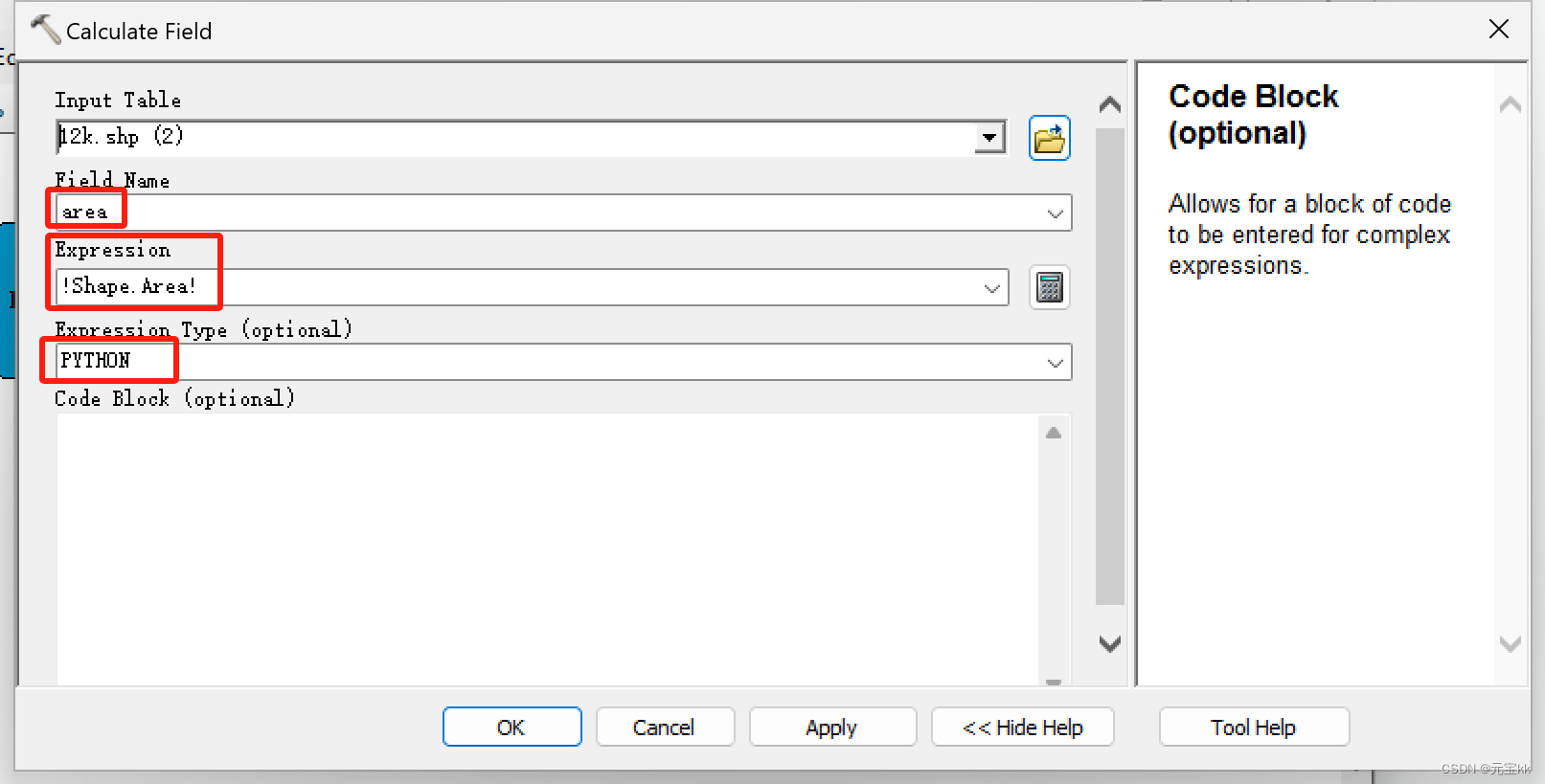
此时已经有面积内容项了,可以进行下一步批量导出shp总面积了。
利用分析工具中的统计工具。路径如下:

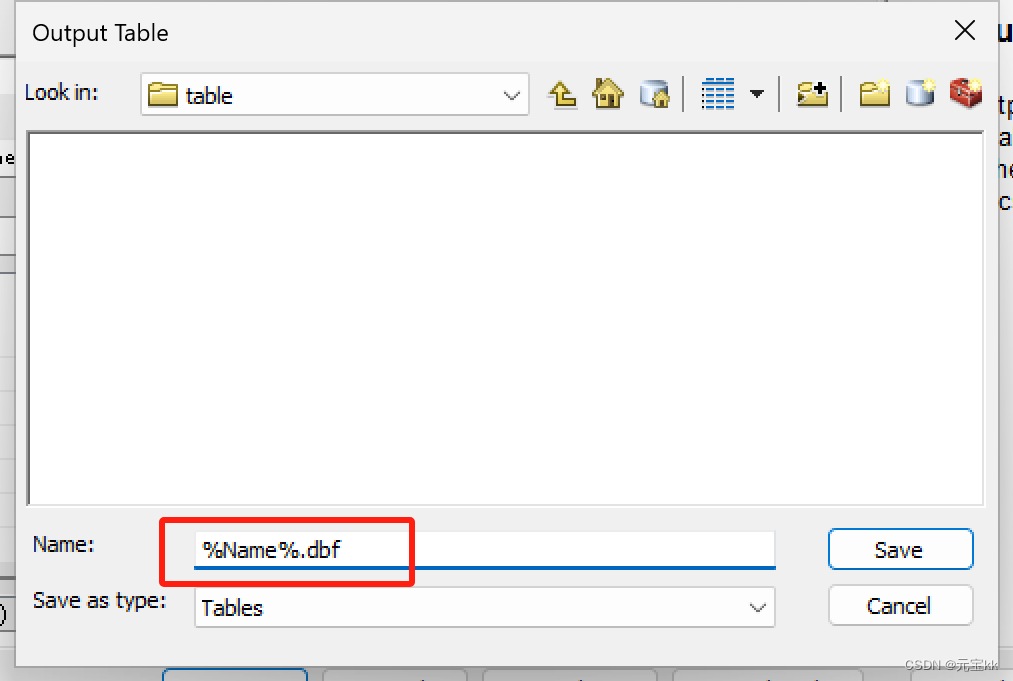
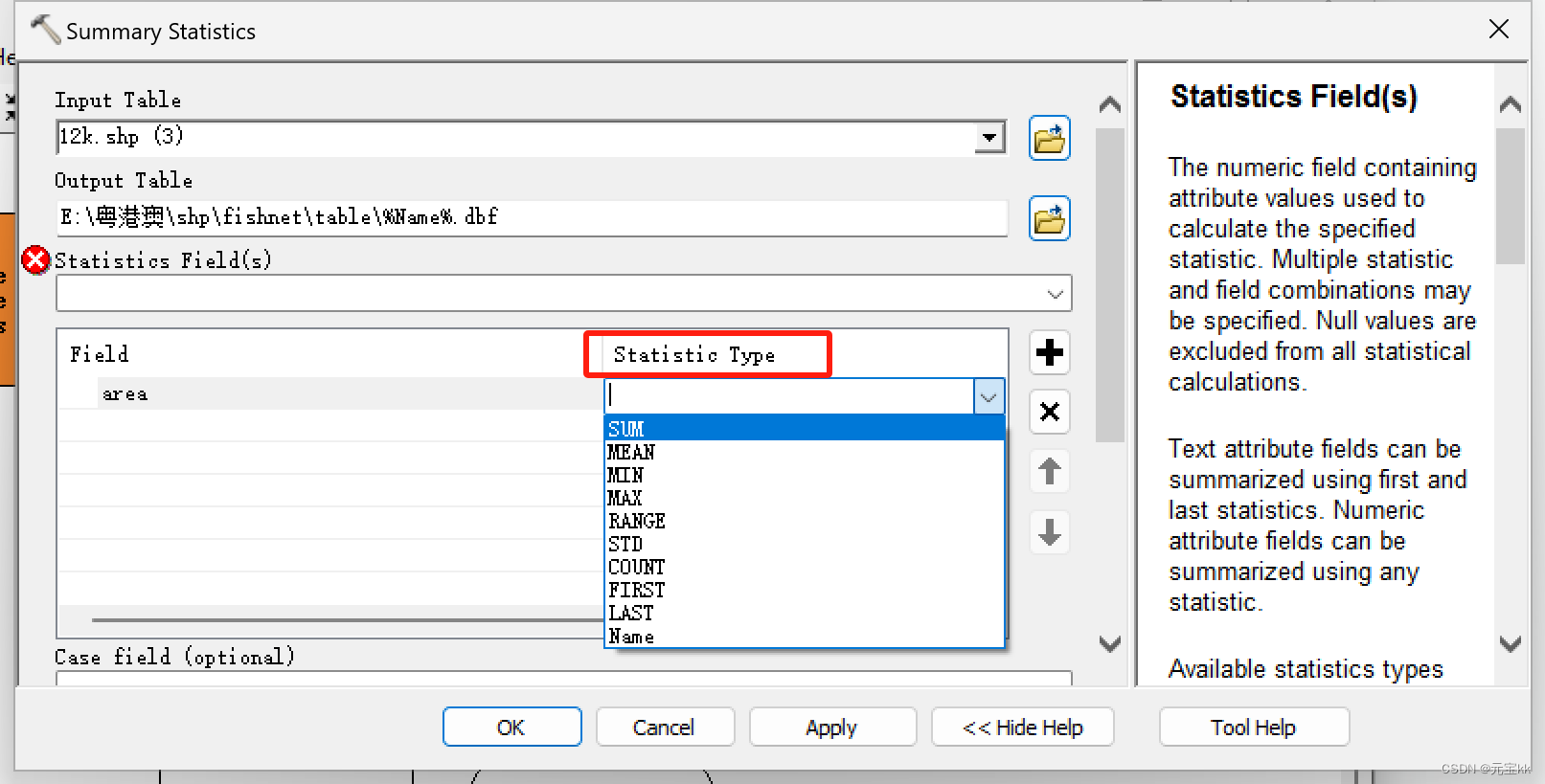
将统计工具拖入模型中,Input Table中选择已计算好面积字段的shp文件,输出路径灵活修改一下,新手就用%Name%.bdf就可以了,这里要注意的是一定要加.dbf后缀,统计字段选择你要统计的字段项,这里我是area。
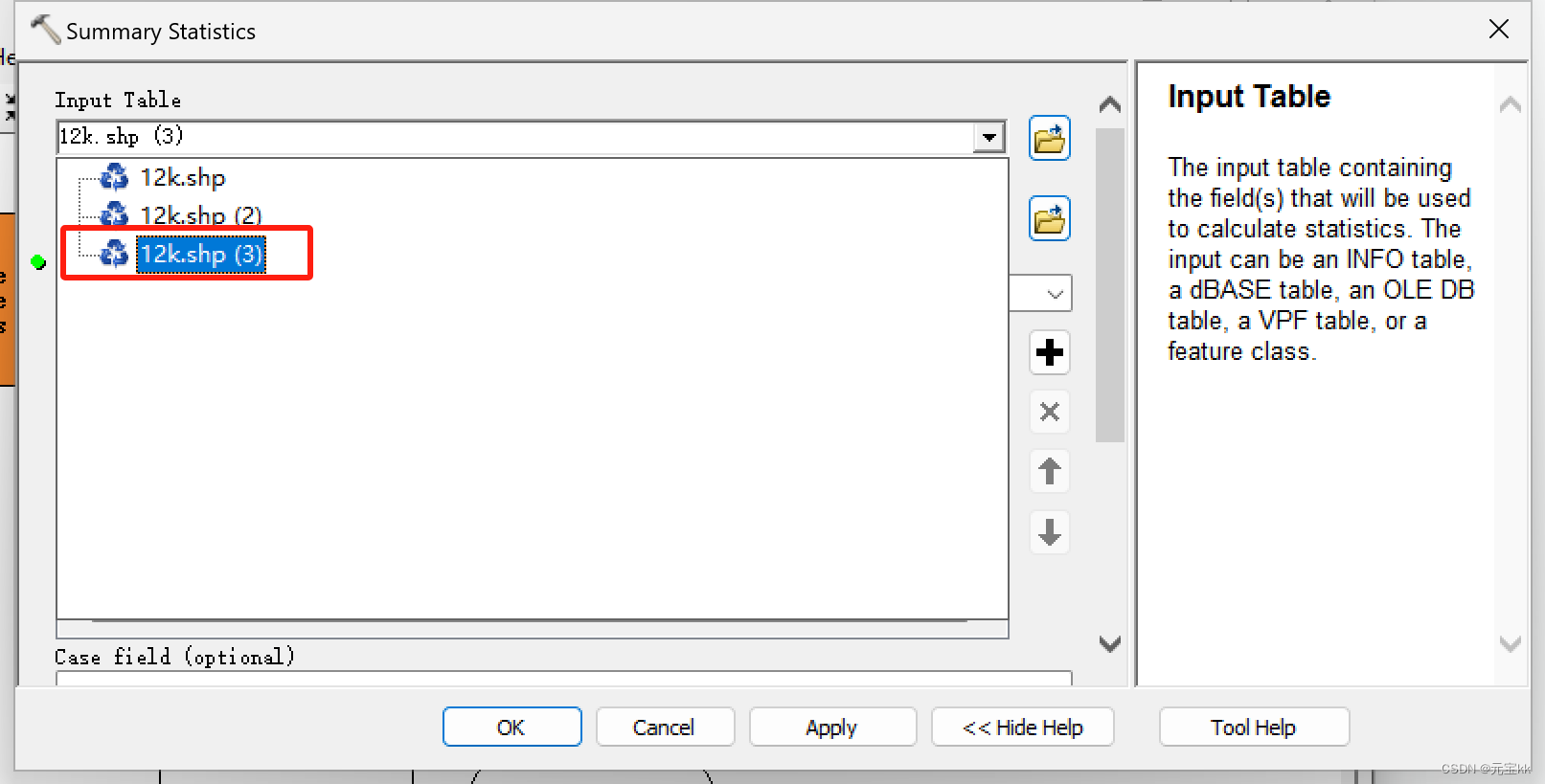

选完字段项以后会弹出一个警告或者红色报错,类似于下图所示的情况,这是由于Statistic Type没有选择。
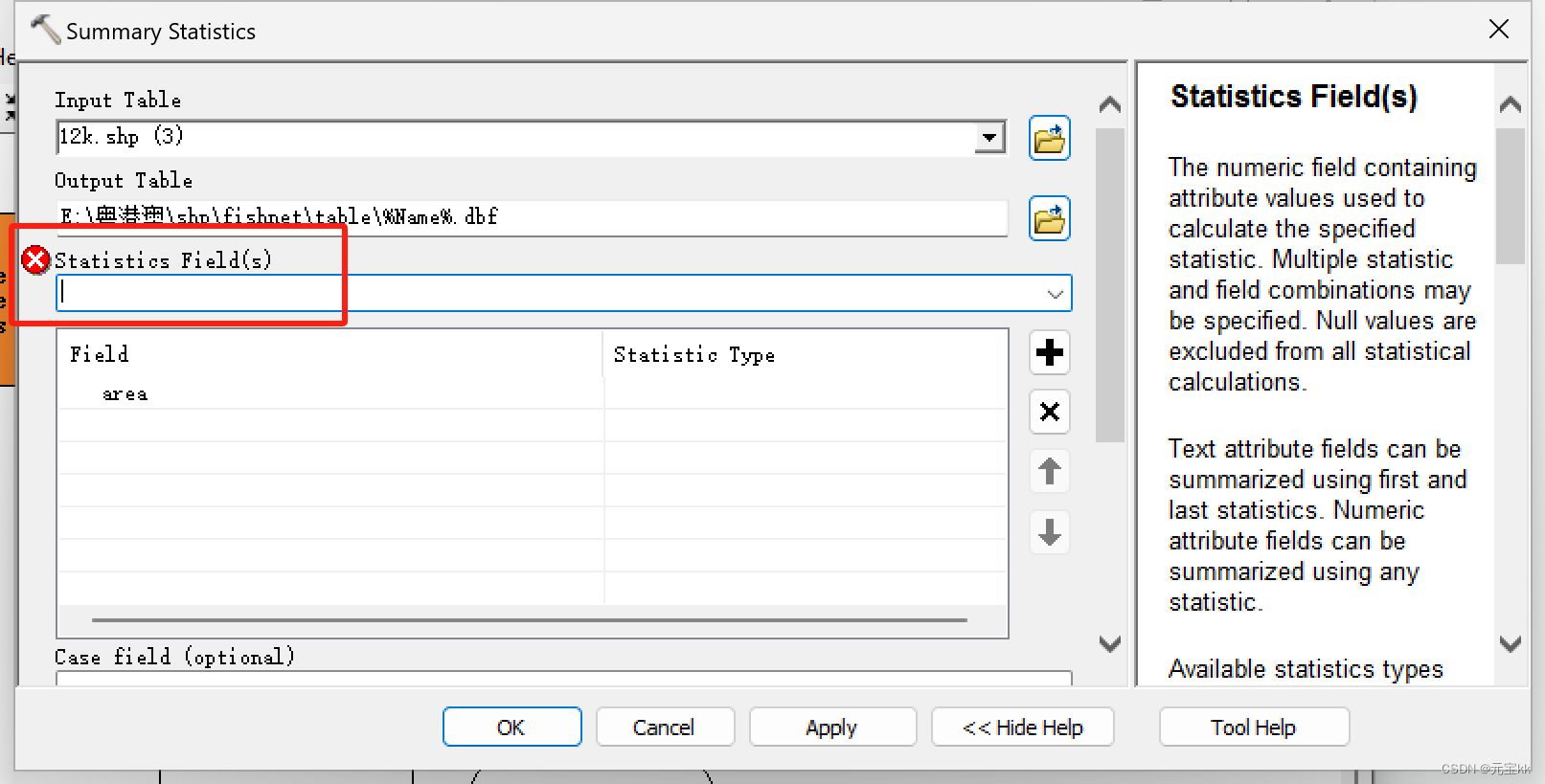
点一下就会出现下拉菜单了,我这里选择了SUM。
其他保持默认就好了,模型构建完后如下图所示。
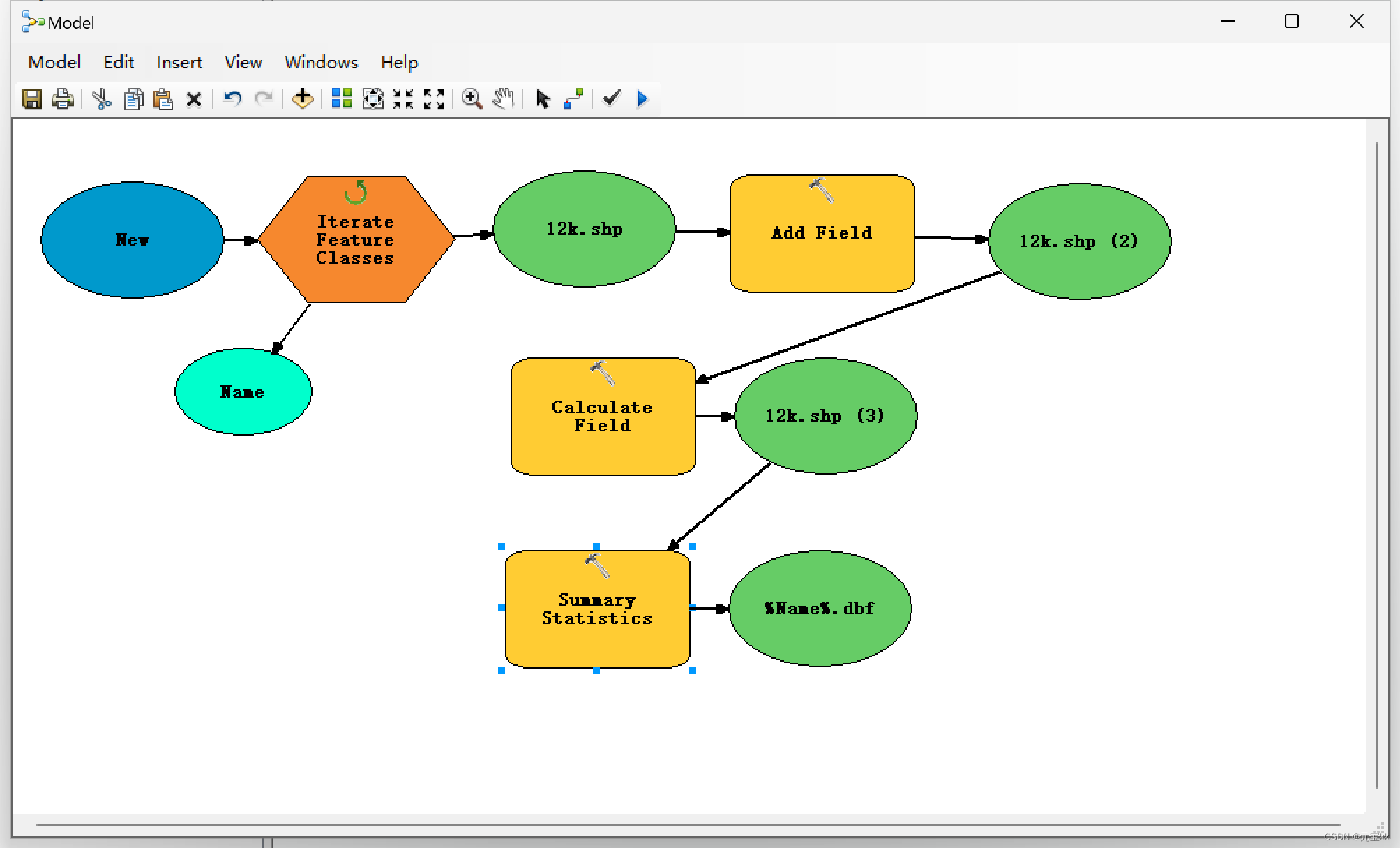
运行结束后,有几个shp就会出现几个表。
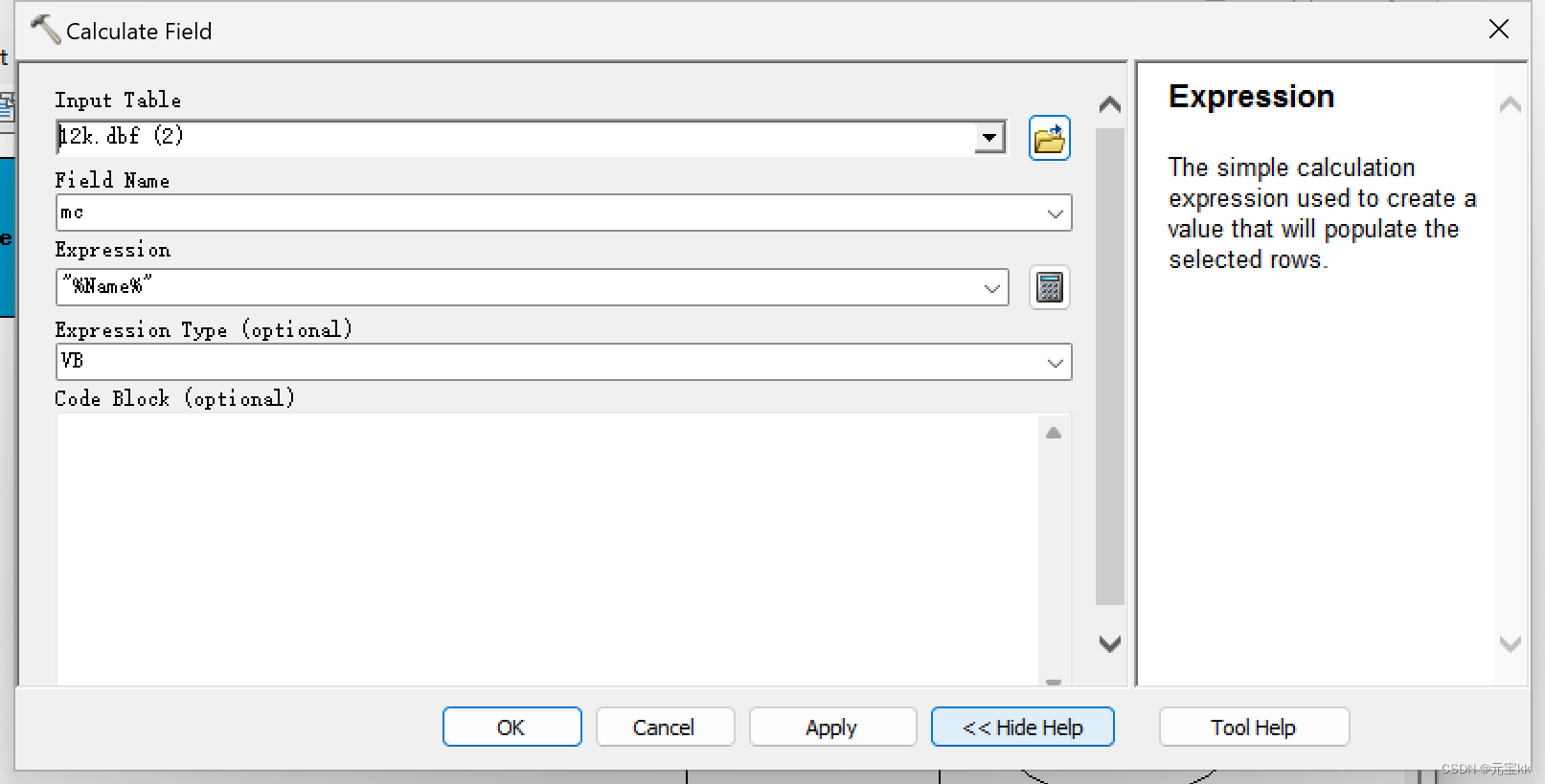
这时如果只想要表的名字和输出的总面积构成一个表时,可以再添加一个字段,字段类型为text,然后再计算字段,这里Expression中要填的变为"%Name%",Expression Type为VB。
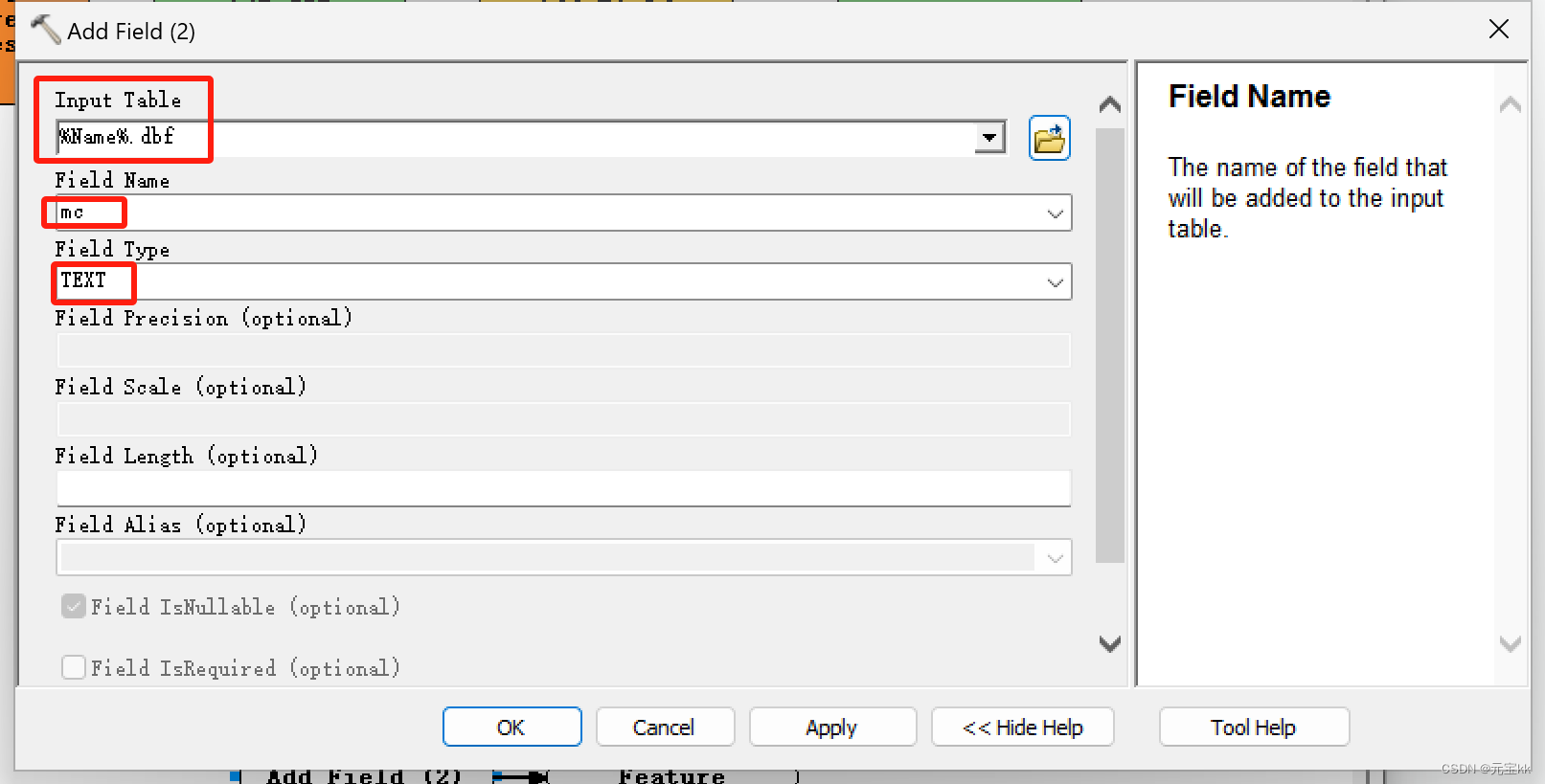
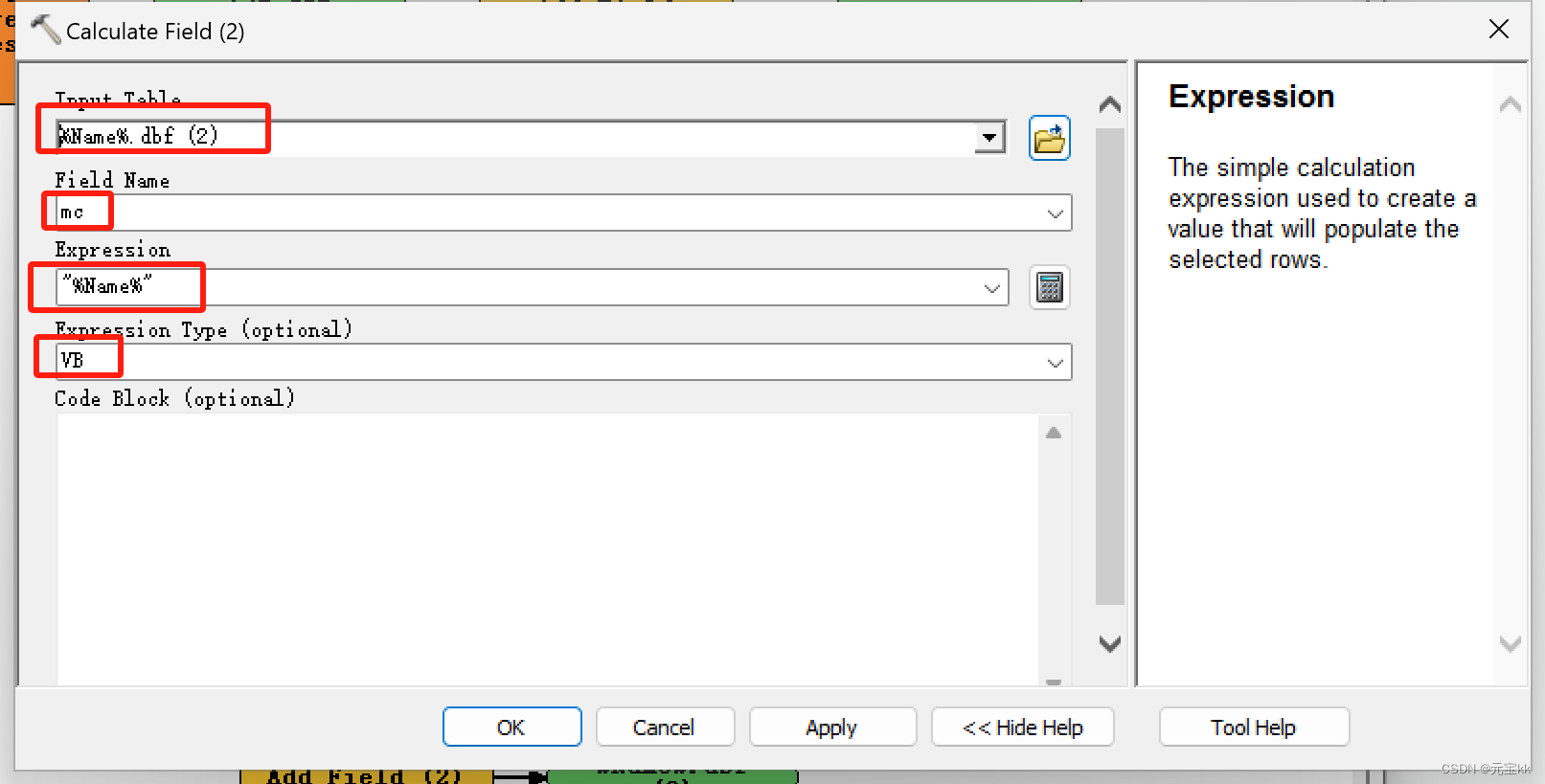
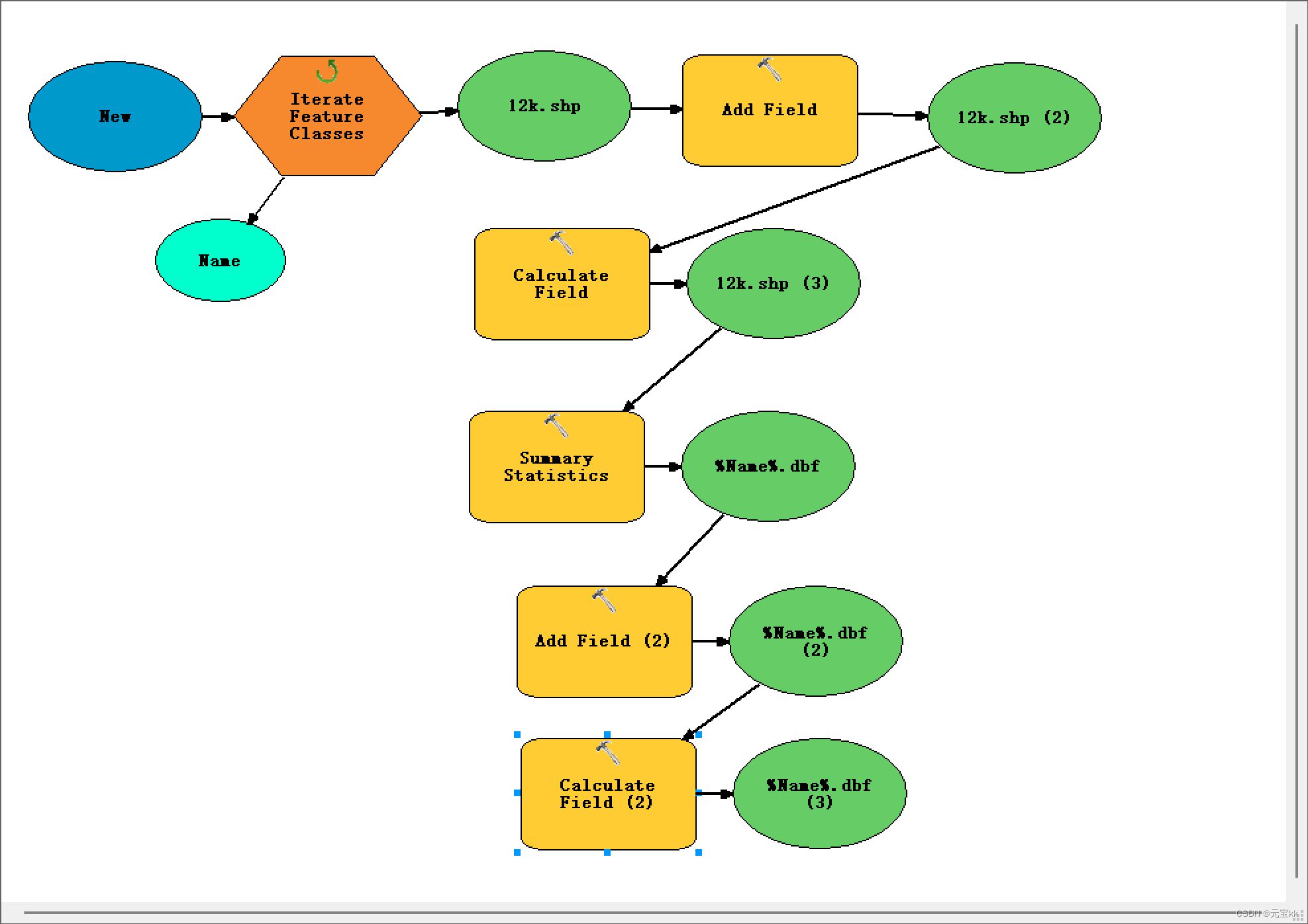
有的电脑可能带不动模型,那就可以在上一个模型计算完毕后再重新形成一个模型,与之前创建方式一样,不过迭代类型从要素类变为了表,工作空间变为了表的文件夹。加进添加字段和计算字段。
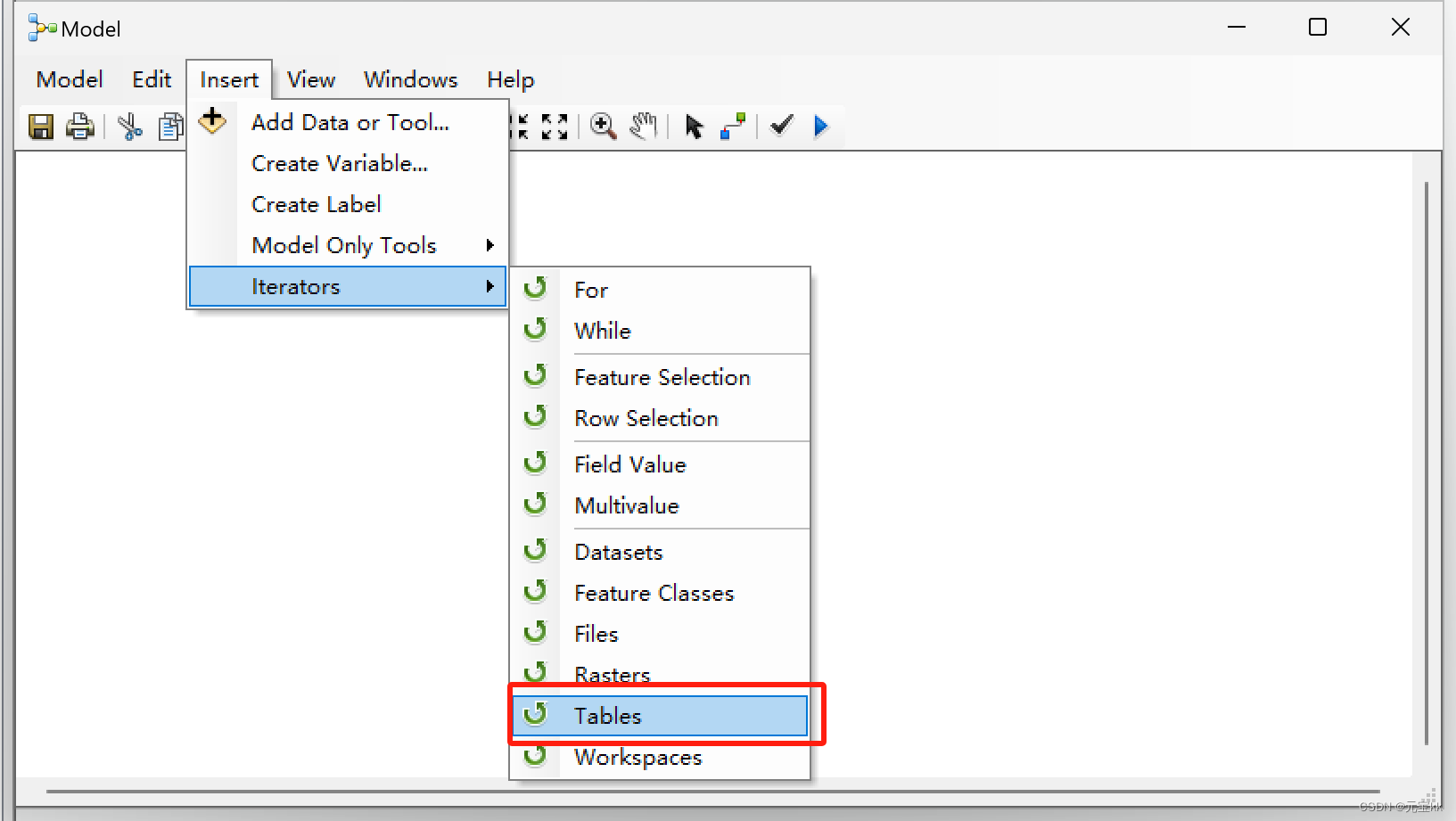
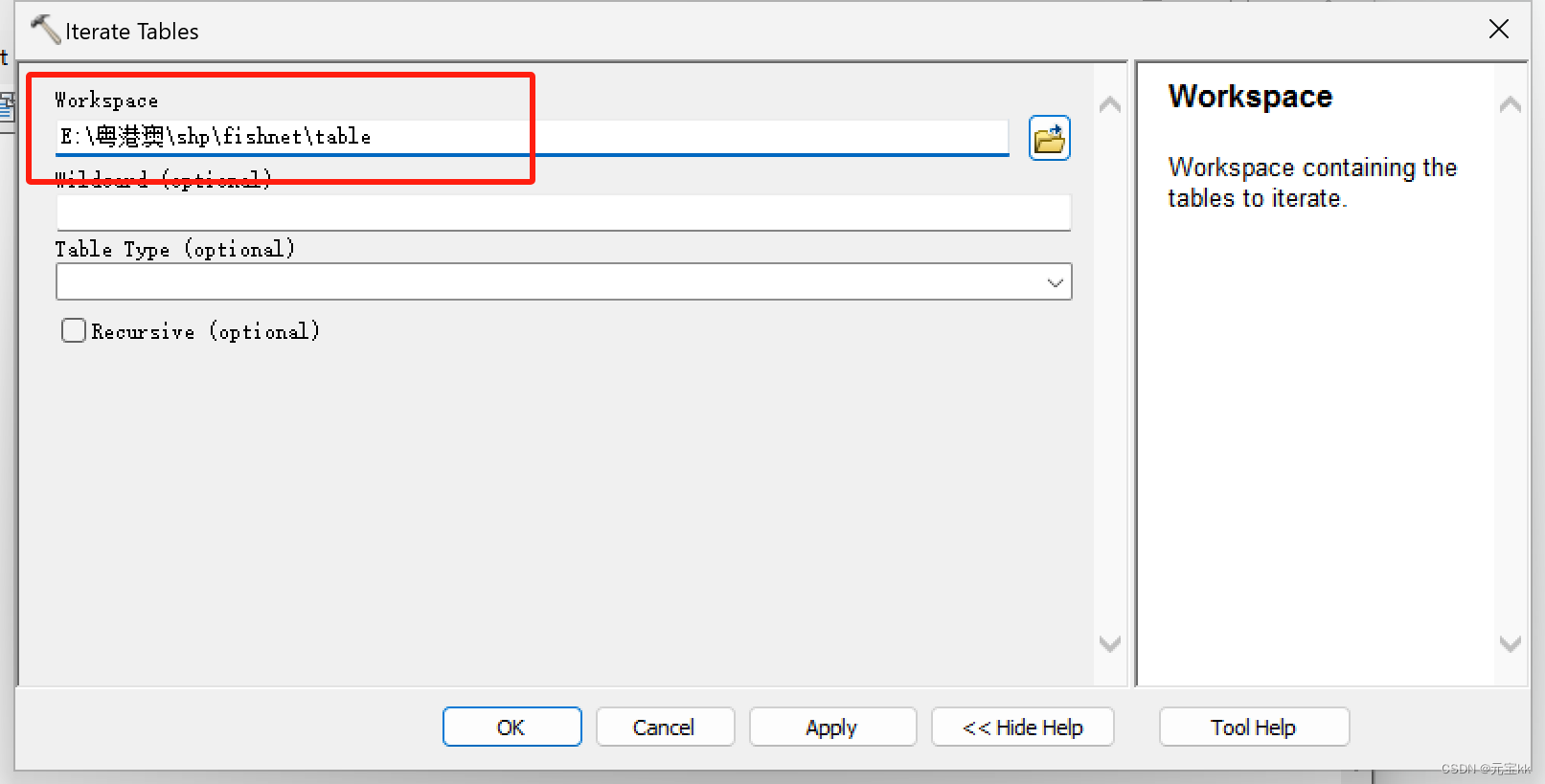
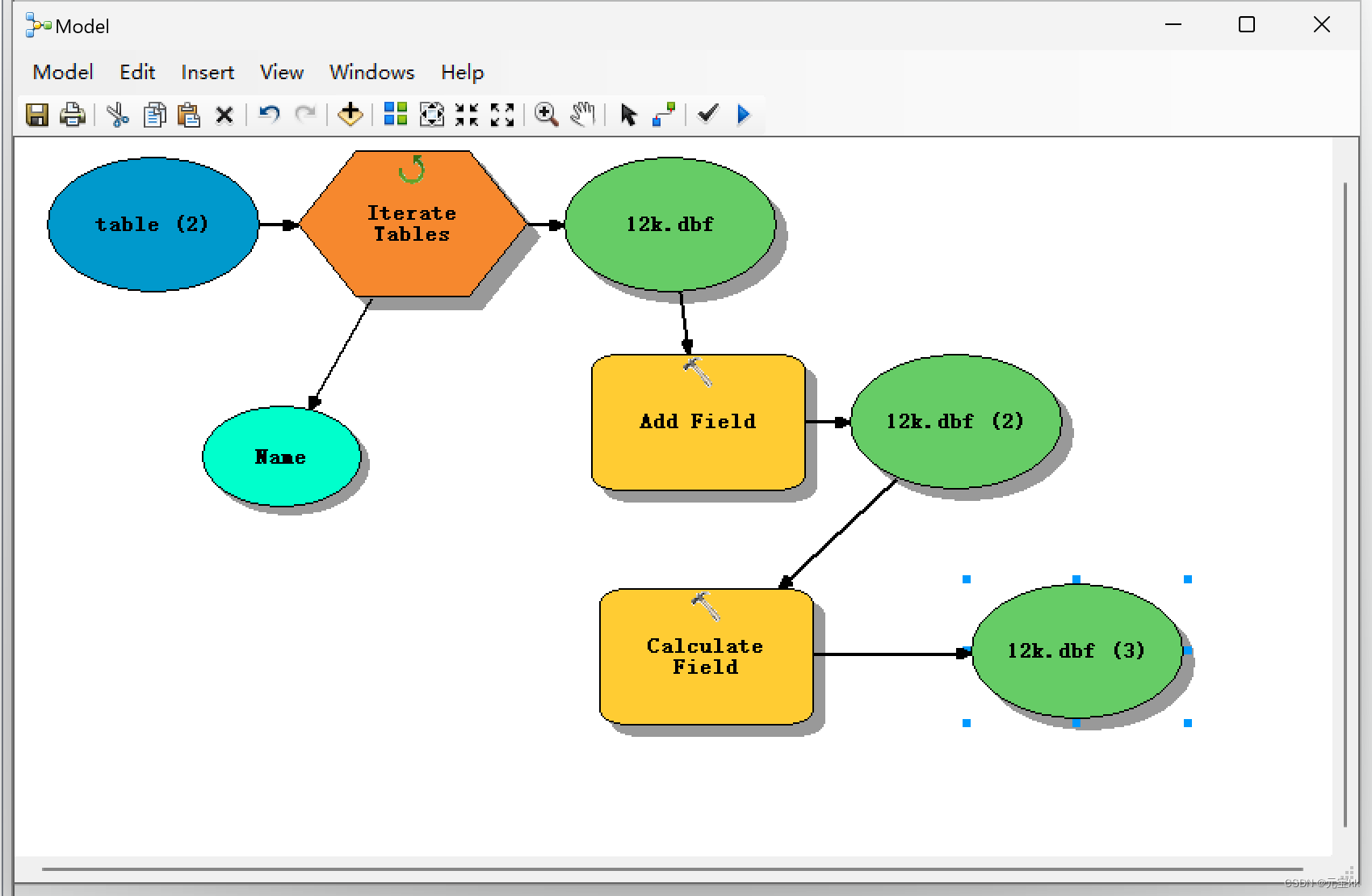
运行模型,结束后将多个表合并在一起。这里运用到的工具为merge
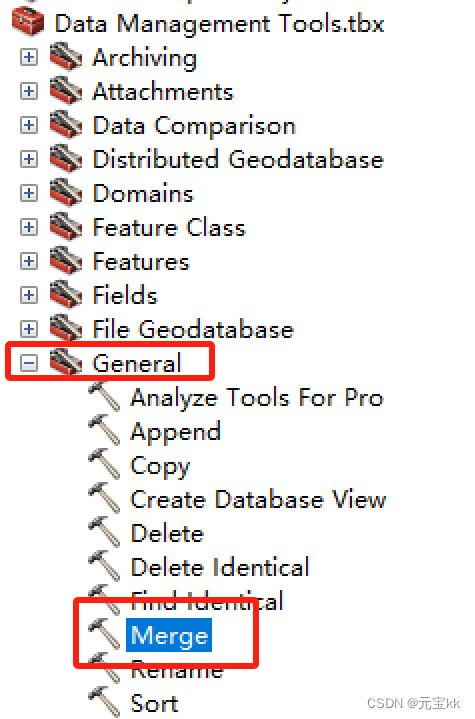
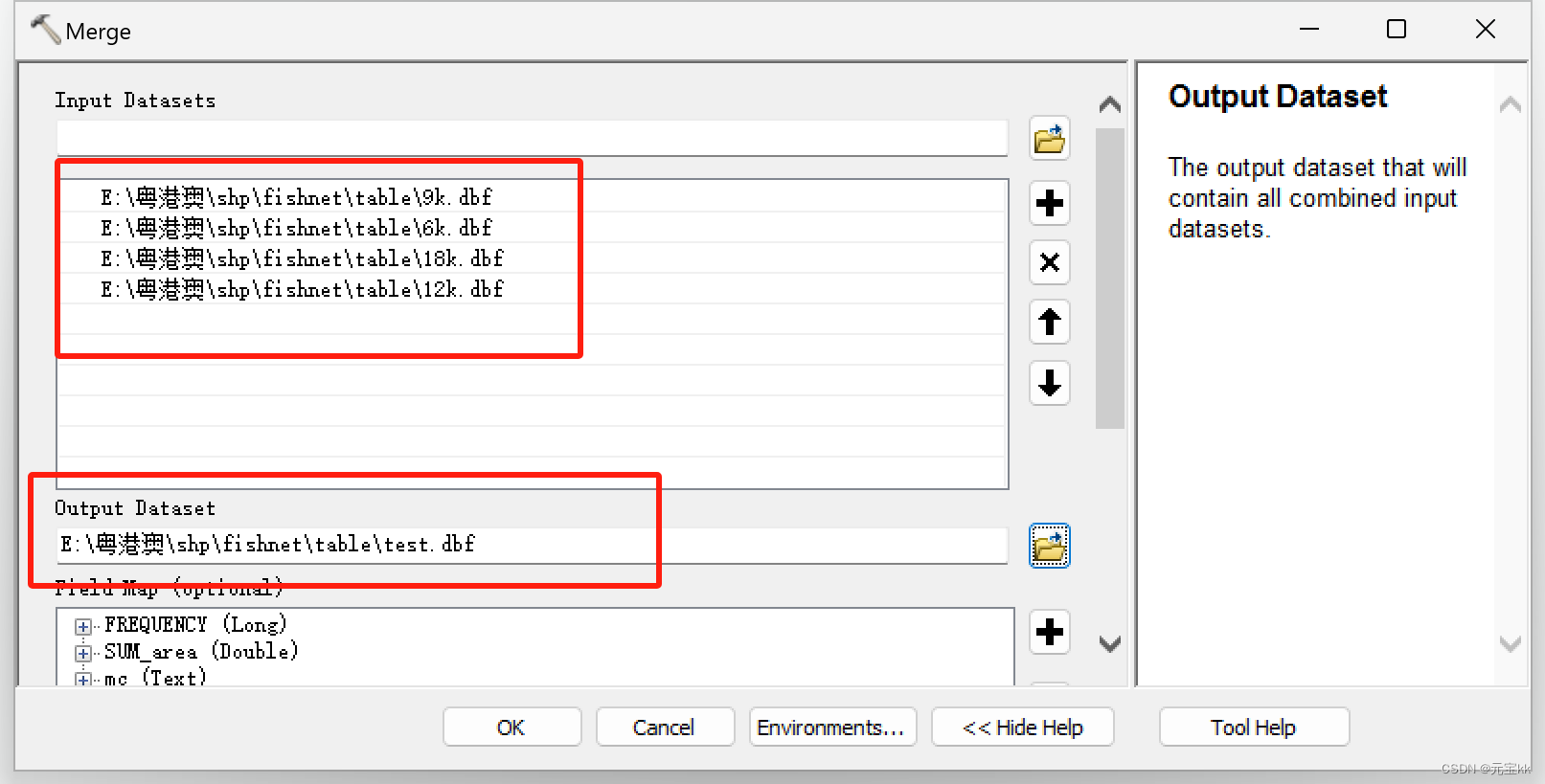
这里输出文件时要添加.dbf后缀,类型选择table
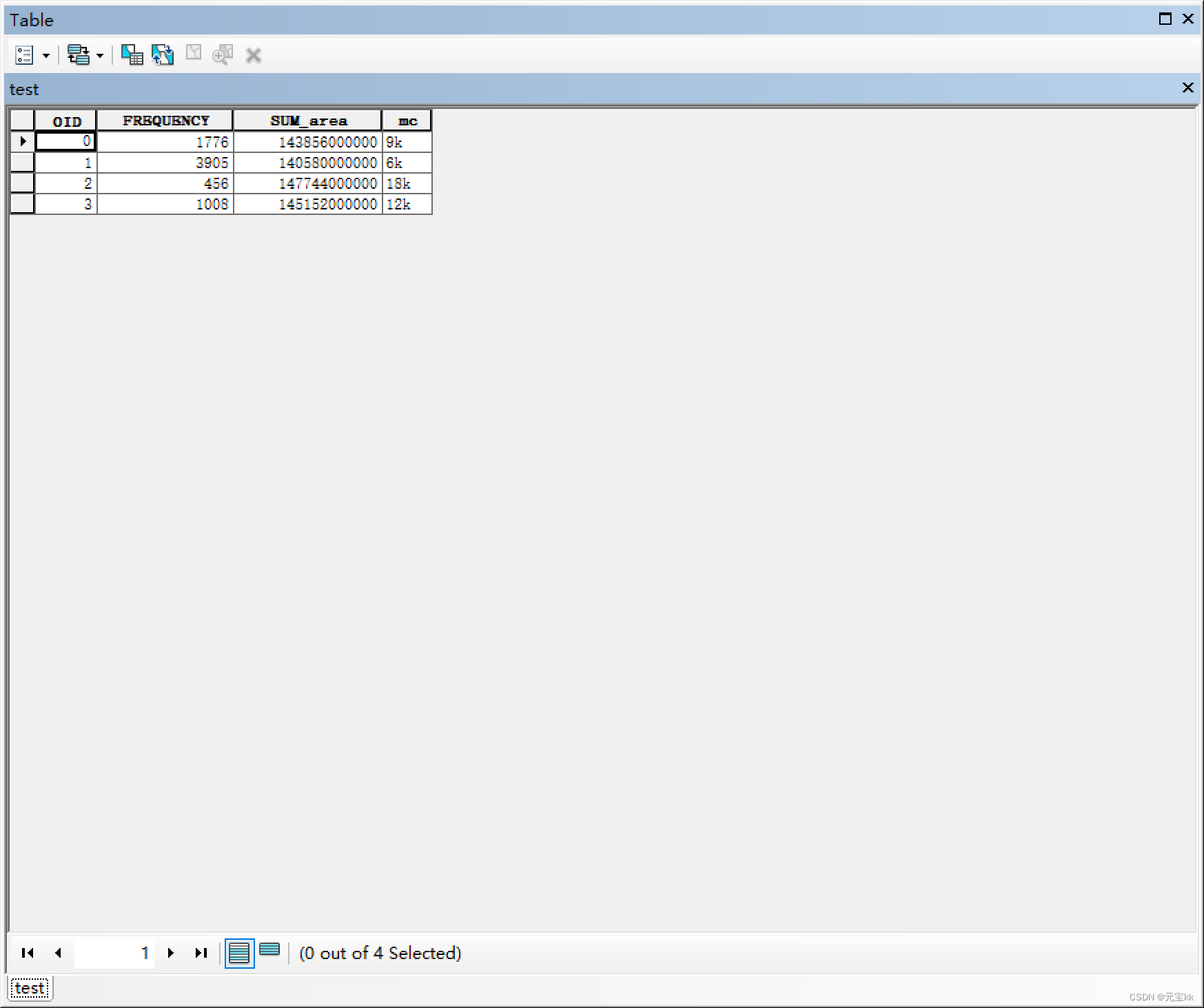
最终结果如图所示,可以导进excel查看
这篇关于ArcGIS批量计算shp面积并导出shp数据总面积(建模法)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







