本文主要是介绍牛奶SEO软件包:集百度网址URL下拉框采集、指数、权重、收录批量查询、文章伪原创一体,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
做SEO的人多少会用到各种查询工具,
今天小编就来分享一些SEO常用工具包:
1、网址批量采集:

多线程换IP一分钟采集3000条,速度超快【突破百度验证码】
实测效率:
电脑配置(四核8G,win10系统,线程:50)
一分钟采集3218条网址,挂机24小时能采集百万条数据,
可以说,只要你的关键词数量足够多,采集的网址你就用不完,
秒杀市面上的独一单线程、不防封工具
2、搜索指数批量查询:

多线程换IP查询【突破百度验证码】
都知道百度现在限制越来越严格,动不动就出现无法破解的验证码,
而这个工具应运而生,能过验证码批量查询
支持宽带拨号和代理API换IP,
直接导入关键词点击开始,
查询结果在右边输出,
格式: 关键词——PC指数 / 移动指数
3、下拉框联想词采集:
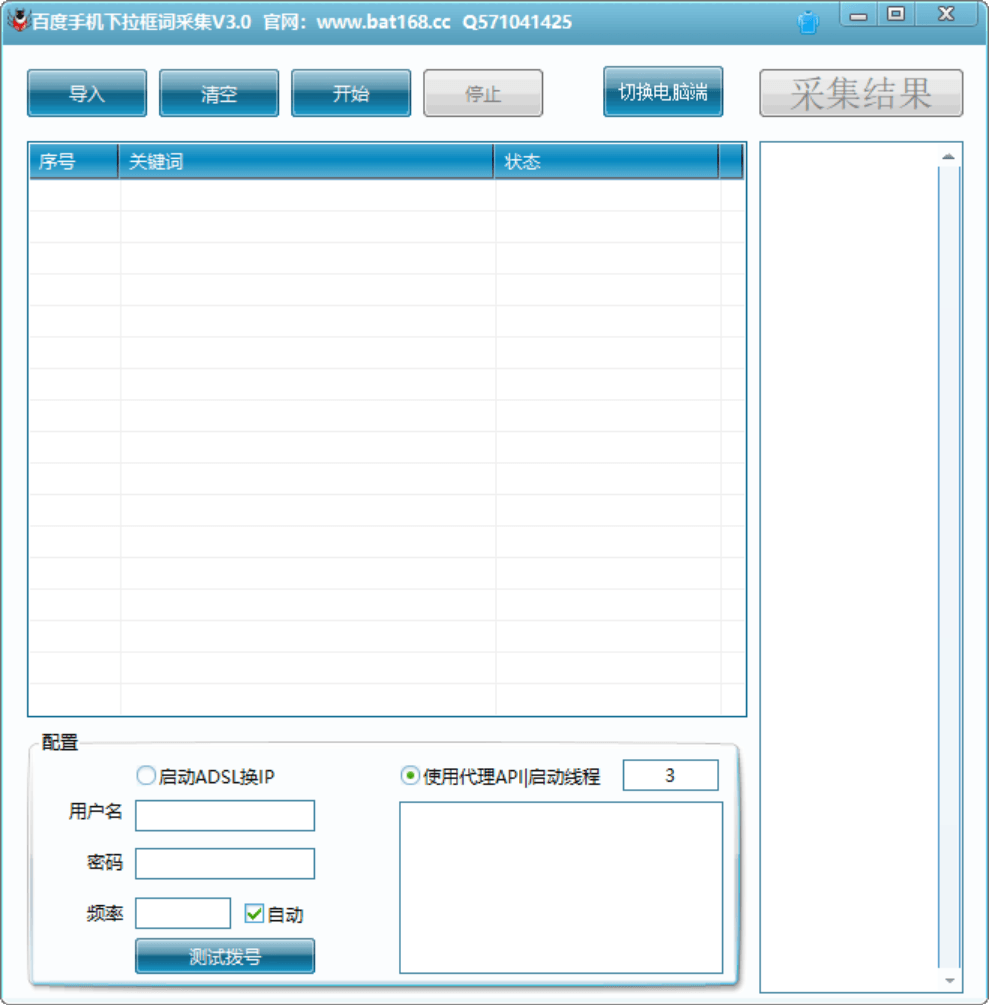
百度、搜狗、神马PC、移动端搜索下拉框采集,是SEO人获取海量长尾词的重要途径。
4、权重批量查询

站群人士必备的权重批量查询工具,包括电脑、移动端的权重,海量网站不用一一去手动查询了
5、网站收录批量查询:

同样是站群人士的最爱,批量查询收录量,实时监测网站的抓取效果
6、AI人工智能文章批量伪原创

独创AI云人工智能文章里伪原创,语句通顺(非同义词转换),好比请人在线重编,原创率80%多,秒杀某奶盘等同义词替换伪原创类工具
注:百度、搜狗、神马、360,SEO工具包还有很多,这里不一一列举
...........
这篇关于牛奶SEO软件包:集百度网址URL下拉框采集、指数、权重、收录批量查询、文章伪原创一体的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








