本文主要是介绍顶配版SAM:由分割一切迈向感知一切,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 0. 前言
- 1. 论文地址
- 1.1 项目&代码
- 1.2 模型地址
- 1.3 Demo
- 2. 模型介绍
- 2.1 亮点
- 2.2 方法
- 3. 量化结果、可视化展示
- Reference
0. 前言
现有的视觉分割基础模型,如 SAM 及其变体,集中优势在形状、边缘等初级定位感知,或依赖外部模型完成更高级的语义理解任务。然而,迈向更高效的视觉感知则需要在单个模型中实现全面的视觉理解,以助力于更广泛的应用场景,如自动驾驶、安防监控、遥感以及医学图像分析等。
近日,智源研究院视觉团队推出以视觉感知为中心的基础模型 TAP (Tokenize Anything via Prompting), 利用视觉提示同时完成任意区域的分割、识别与描述任务。将基于提示的分割一切基础模型 (SAM) 升级为标记一切基础模型 (TAP),高效地在单一视觉模型中实现对任意区域的空间理解和语义理解。相关的模型、代码均已开源,并提供了 Demo 试用,更多技术细节请参考 TAP 论文。

1. 论文地址
https://arxiv.org/abs/2312.09128
1.1 项目&代码
https://github.com/baaivision/tokenize-anything
1.2 模型地址
https://huggingface.co/BAAI/tokenize-anything
1.3 Demo
https://huggingface.co/spaces/BAAI/tokenize-anything
2. 模型介绍
2.1 亮点
通用能力:TAP 是一个统一的可提示视觉基础模型,根据视觉提示(点、框、涂鸦)对任意区域内的目标同时进行分割、识别以及描述,最终汇聚成一组可用于综合评估区域内容的输出结果。
通用表征:TAP 将任意区域中的内容表示为紧凑的掩码标记和语义标记,掩码标记负责空间理解,语义标记则负责语义理解。因此,TAP 模型可以替代 SAM,CLIP 作为下游应用的新基础模型。
通用预训练:TAP 利用大量无语义的分割掩码,直接从通用 CLIP 模型中汲取开放世界知识。这种预训练新范式避免了使用与任意数据集相关的有偏差人工标注,缓解了物体在开放语义下的定义冲突与不完备问题。
2.2 方法
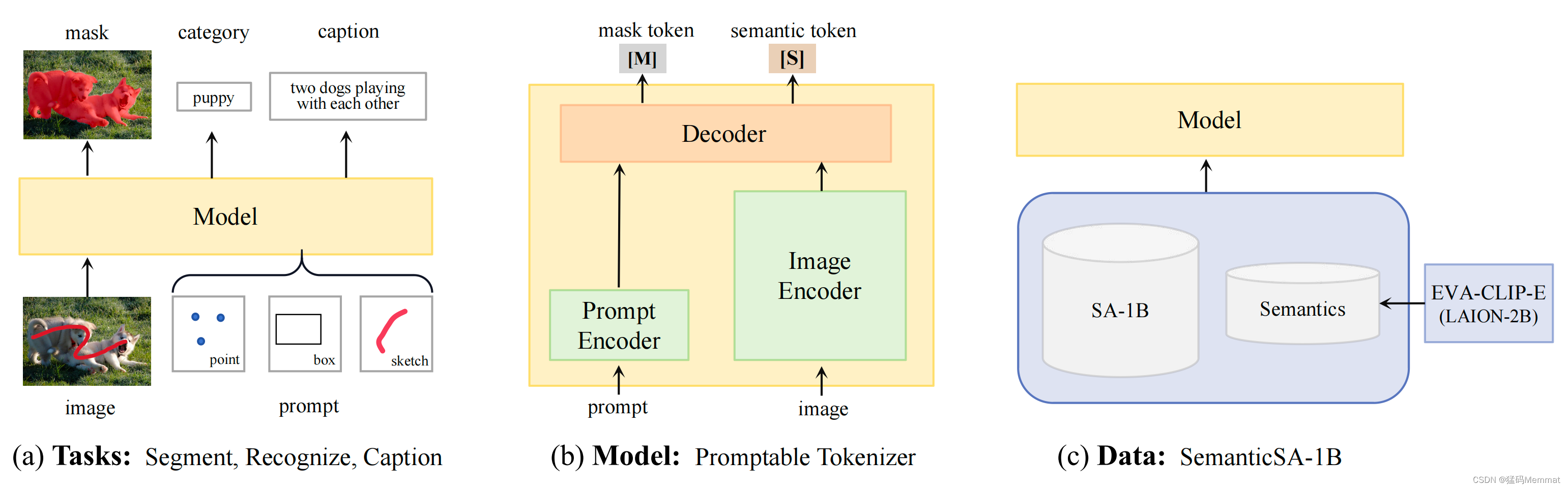
模型架构:为了实现一个统一的模型,TAP 在 SAM 架构的基础上,将掩码解码器升级为通用的图像解码器,同时输出掩码标记与语义标记(图b)。掩码标记负责预测分割掩码,语义标记则用于预测对应的语义标签和文本描述。
数据获取:训练一个多能力的视觉基础模型需要多样化标注的大规模数据集。然而,目前尚无公开的可同时用于分割与区域识别的大规模数据源。SA-1B 构建了 11 亿高质量掩码标注,用于训练分割基础模型,如 SAM。LAION-2B 收集了 20 亿图像-文本对,用于训练图文对齐模型,如 CLIP。
为了解决分割-文本对齐数据缺乏的问题,TAP 引入了 SemanticSA-1B 数据集(图c)。该数据集将来自 LAION-2B 的语义隐式地集成到 SA-1B 的分割数据中。具体而言,TAP 利用在 LAION-2B 数据集上训练的具有 50 亿参数的 EVA-CLIP 模型,预测 SA-1B 中的每一个分割区域在一个概念词汇上的分布。该分布提供信息最大化的语义监督, 避免模型在偏差过大的伪标签上训练。
模型训练:TAP 模型在 256 块寒武纪 MLU370 加速器上进行预训练,并行优化可提示分割与概念预测两个任务。给定一张图片及一个视觉提示,TAP 模型将感兴趣区域表示为一个掩码标记和一个语义标记。基于语义标记,扩展一个 MLP 预测器可实现开放词汇分类任务。同时,扩展一个轻量化的自回归文本解码器即可实现文本生成任务。
3. 量化结果、可视化展示
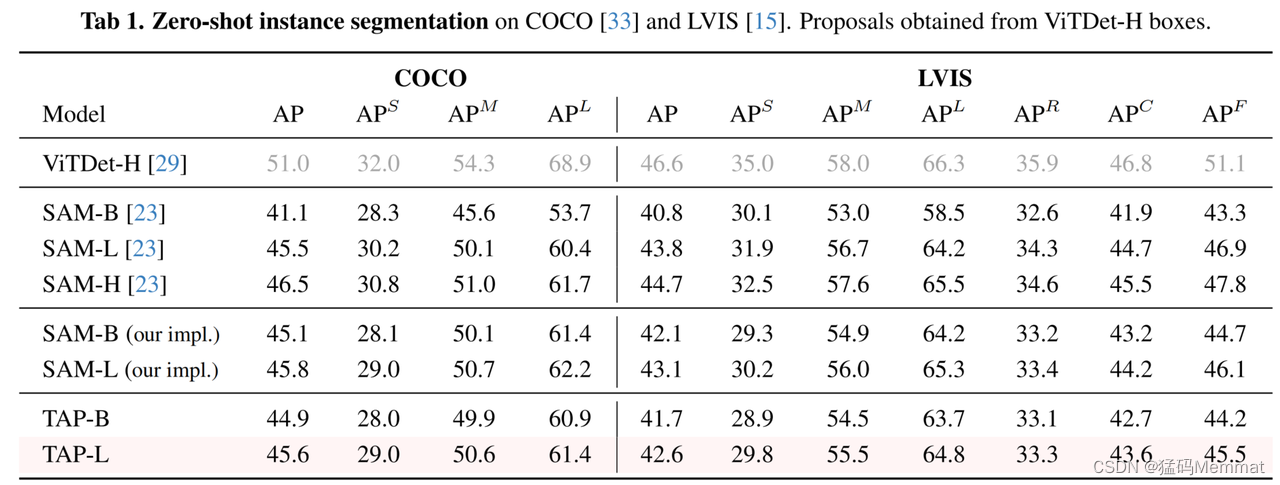
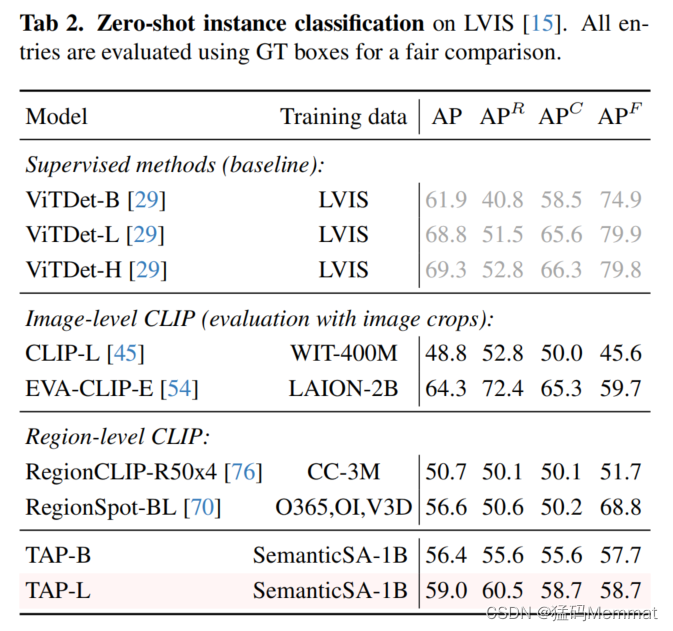
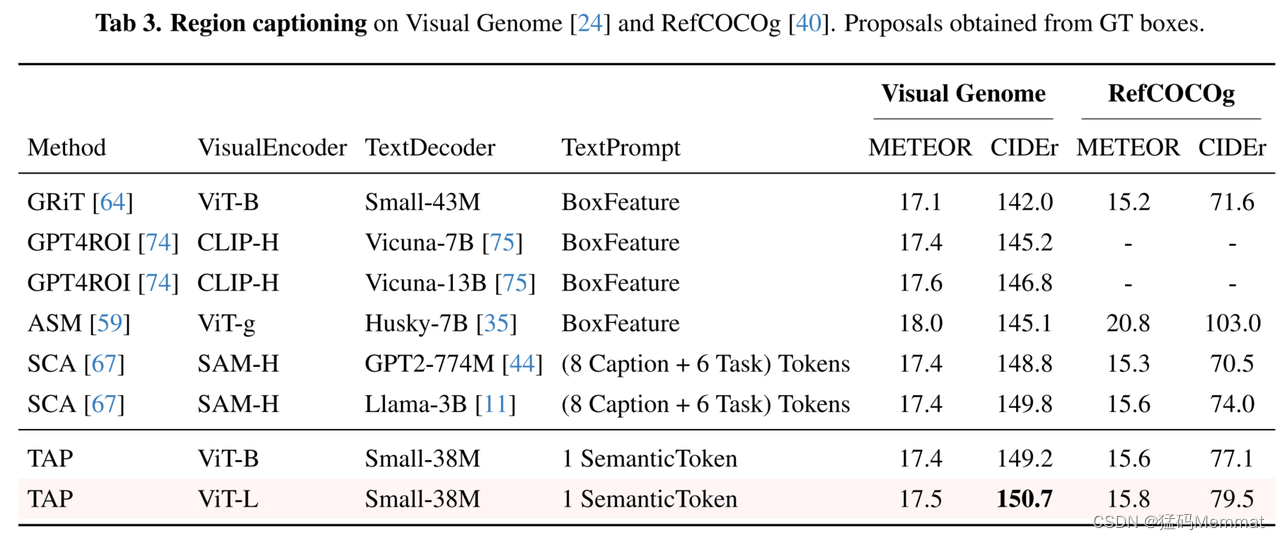
简单点击或涂鸦图片中感兴趣的目标,TAP 即可自动生成目标区域的分割掩码、类别标签、以及对应的文本描述,实现了一个模型同时完成任意的分割、分类和图像描述。


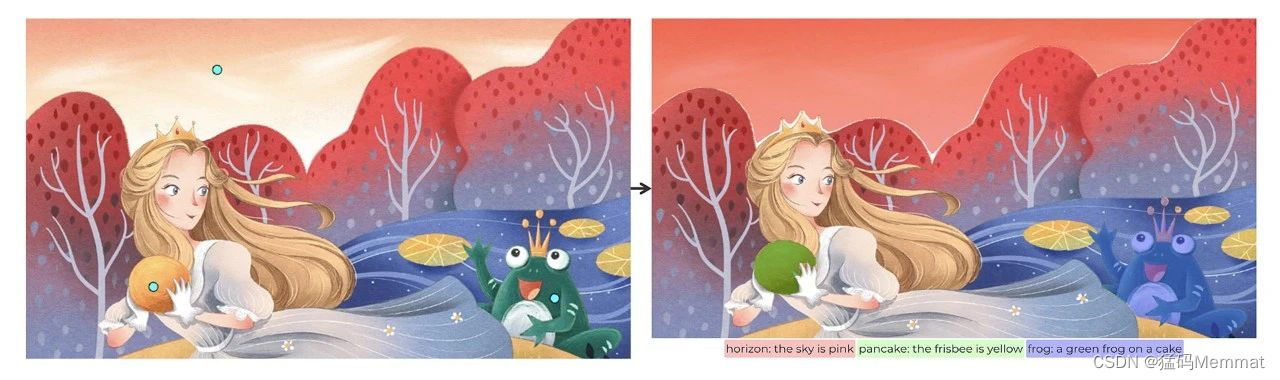


对于需要全景理解的场景,采用密集网格点作为提示,模型即可对场景内所有的目标进行分割、识别以及描述。


Reference
[1] Alexander Kirillov, et al. Segment anything. ICCV, 2023.
[2] Alec Radford, et al. Learning Transferable Visual Models from Natural Language Supervision. ICML, 2021.
[3] Sun, et al. EVA-CLIP: Improved Training Techniques for CLIP at Scale. arXiv:2303.15389, 2023.
[4] Schuhmann, et al. LAION-5B: An Open Large-scale Dataset for Training Next Generation Image-Text Models. arXiv:2210.08402, 2023.
这篇关于顶配版SAM:由分割一切迈向感知一切的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









