本文主要是介绍[最优化导论]C6 集合约束和无约束优化问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
集合约束和无约束优化问题
集合约束和无约束优化的基本形式为:
m i n i m i z e f ( x ) s u b j e c t t o x ∈ Ω \begin{aligned} minimize f(\mathbf{x}) \\ subject\ \ to\ \ \mathbf{x}\in\Omega\end{aligned} minimizef(x)subject to x∈Ω
目标就是在约束集 Ω \Omega Ω中找出最好的决策变量 x \mathbf{x} x,如果 Ω = R n \Omega=\mathbb{R}^n Ω=Rn,则问题就会转化为无约束优化问题。
用数学化的形式定义一下局部最小点就是:
如果存在一个 ε > 0 \varepsilon>0 ε>0,对于所有满足 ∣ ∣ x − x ∗ ∣ ∣ < ε ||\mathbf{x}-\mathbf{x}^*||<\varepsilon ∣∣x−x∗∣∣<ε的向量 x \mathbf{x} x,不等式 f ( x ) ≥ f ( x ∗ ) f(\mathbf{x}) \geq f(\mathbf{x}^*) f(x)≥f(x∗)都成立,则称 x ∗ \mathbf{x}^* x∗是函数 f f f在定义域中的一个局部最小点。
说的简单点就是如果在 x ∗ \mathbf{x}^* x∗一个邻域内的函数值都比在这个点大,则这个点就是局部最小点。
如果把上述的 ≥ \geq ≥换成 > > >,局部最小点也就成严格局部最小点。
优化问题的极小点可能位于约束集 Ω \Omega Ω的内部,也可能位于边界上。处于边界上的极小点需要满足一定条件之后才能成为真正的极小点。
举个例子:对于 f ( x ) = x 3 f(x)=x^3 f(x)=x3的函数,毫无疑问该函数是单调递增的,但一阶导数和二阶导数在原点的值为0,显然x=0并不是极小值点,由此可以看出成为局部最小点需要满足一些必要条件和充分条件,在多维空间中也是如此。
n元实值函数求导问题回顾:
导数矩阵(雅克比矩阵)为: D f ( x 0 ) = [ ∂ f ∂ x 1 ( x 0 ) ⋯ ∂ f ∂ x n ( x 0 ) ] Df(x_0)=[\frac{\partial f}{\partial x_1}(x_0) \cdots \frac{\partial f}{\partial x_n}(x_0)] Df(x0)=[∂x1∂f(x0)⋯∂xn∂f(x0)]
如果函数f为一个向量,并且它的作用是将n维空间转化为m为空间,则对应的矩阵为:
D f ( x 0 ) = [ ∂ f ∂ x 1 ( x 0 ) ⋯ ∂ f ∂ x n ( x 0 ) ] = [ ∂ f 1 ∂ x 1 ( x 0 ) ⋯ ∂ f 1 ∂ x n ( x 0 ) ⋯ ⋯ ∂ f m ∂ x 1 ( x 0 ) ⋯ ∂ f m ∂ x n ( x 0 ) ] Df(x_0)=[\frac{\partial f}{\partial x_1}(x_0) \cdots \frac{\partial f}{\partial x_n}(x_0)]=\begin{bmatrix} \frac{\partial f_1}{\partial x_1}(x_0) &\cdots & \frac{\partial f_1}{\partial x_n}(x_0)\\ \cdots & & \cdots \\ \frac{\partial f_m}{\partial x_1}(x_0) &\cdots & \frac{\partial f_m}{\partial x_n}(x_0) \end{bmatrix} Df(x0)=[∂x1∂f(x0)⋯∂xn∂f(x0)]=⎣⎡∂x1∂f1(x0)⋯∂x1∂fm(x0)⋯⋯∂xn∂f1(x0)⋯∂xn∂fm(x0)⎦⎤
如果二次可微,则对应的黑塞矩阵为:
F ( x ) ≜ D 2 f = [ ∂ 2 f ∂ x 1 2 ∂ 2 f ∂ x 2 ∂ x 1 ⋯ ∂ 2 f ∂ x n ∂ x 1 ∂ 2 f ∂ x 1 ∂ x 2 ∂ 2 f ∂ x 2 2 ⋯ ∂ 2 f ∂ x n ∂ x 2 ⋮ ⋮ ⋱ ⋮ ∂ 2 f ∂ x 1 ∂ x n ∂ 2 f ∂ x 2 ∂ x n ⋯ ∂ 2 f ∂ x n 2 ] \mathbf{F(x)}\triangleq D^2f=\begin{bmatrix} \frac{\partial^2 f}{\partial x_1^2} &\frac{\partial^2 f}{\partial x_2\partial x_1} & \cdots & \frac{\partial^2 f}{\partial x_n\partial x_1}\\ \frac{\partial^2 f}{\partial x_1\partial x_2} & \frac{\partial^2 f}{\partial x_2 ^2}& \cdots & \frac{\partial^2 f}{\partial x_n\partial x_2}\\ \vdots &\vdots & \ddots &\vdots\\ \frac{\partial^2 f}{\partial x_1\partial x_n} & \frac{\partial^2 f}{\partial x_2\partial x_n}& \cdots & \frac{\partial^2 f}{\partial x_n ^2} \end{bmatrix} F(x)≜D2f=⎣⎢⎢⎢⎢⎢⎡∂x12∂2f∂x1∂x2∂2f⋮∂x1∂xn∂2f∂x2∂x1∂2f∂x22∂2f⋮∂x2∂xn∂2f⋯⋯⋱⋯∂xn∂x1∂2f∂xn∂x2∂2f⋮∂xn2∂2f⎦⎥⎥⎥⎥⎥⎤
1.一阶必要条件
首先来看这样一种情况,

在上图中,如果x向量往d2方向走一小步,就会走出约束集合;而往d1方向走一小步还在约束集内,所以d1为可行方向。对应的,d2为不可行方向。
设在约束集内的可行方向为 d \mathbf{d} d,函数对应的梯度为 ▽ f ( x ) \bigtriangledown f(\mathbf{x}) ▽f(x)为函数梯度,则沿着可行方向的方向倒数为梯度与单位可行方向向量的内积。
对应的一阶必要条件为:
f f f在约束集 Ω \Omega Ω上一阶连续可微,如果 x ∗ \mathbf{x}^* x∗是函数 f f f在约束集 Ω \Omega Ω上局部极小点,则需要满足处于 x ∗ \mathbf{x}^* x∗的任意可行方向上,都有:
d T ▽ f ( x ) ≥ 0 \mathbf{d}^T\bigtriangledown f(\mathbf{x})\geq 0 dT▽f(x)≥0
成立。
例如在下图中,x1并不能满足一阶必要条件,而x2可以。所以x1不是局部极小点。
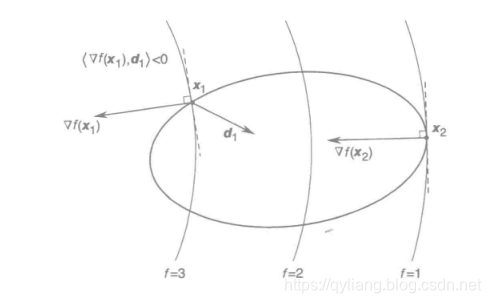
推论
如果 x ∗ \mathbf{x}^* x∗是位于约束集内部的点,则需要满足的一阶必要条件为:
▽ f ( x ∗ ) = 0 \bigtriangledown f(\mathbf{x}^*)=0 ▽f(x∗)=0
即需要满足梯度为0向量,相当于在一元函数中函数的导数为0是必要条件。
2. 二阶必要条件
一阶必要条件并不能确保某个点为局部最小点,局部最小点还需要满足的二阶必要条件为:
Ω \Omega Ω上二阶连续可微,满足一阶必要条件的情况下,还需满足:
d T F ( x ∗ ) d ≥ 0 \mathbf{d}^T\mathbf{F(x^*)}\mathbf{d}\geq 0 dTF(x∗)d≥0
其中 F \mathbf{F} F为函数对应的黑塞矩阵。
同样如果 x ∗ \mathbf{x}^* x∗在约束集内部时,需要满足的二阶必要条件为:
▽ f ( x ∗ ) = 0 \bigtriangledown f(\mathbf{x}^*)=0 ▽f(x∗)=0
d T F ( x ∗ ) d ≥ 0 \mathbf{d}^T\mathbf{F(x^*)}\mathbf{d}\geq 0 dTF(x∗)d≥0
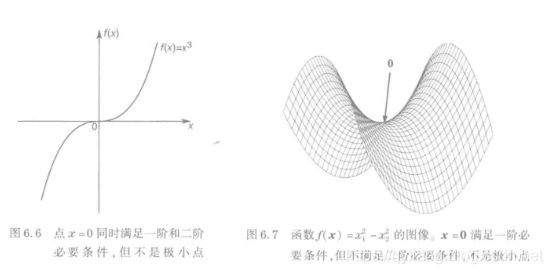
同时满足两个必要条件也不一定为局部最小点,如作图;右图为满足一阶必要条件,而不满足二阶必要条件的例子。
3. 局部最小点的充分条件
如果:
- ▽ f ( x ∗ ) = 0 \bigtriangledown f(\mathbf{x}^*)=0 ▽f(x∗)=0
- F ( x ∗ ) > 0 \mathbf{F(x^*)}> 0 F(x∗)>0
则 x ∗ \mathbf{x}^* x∗为函数 f f f的严格局部最小点。
相当于在一元函数中,一阶导数为0且二阶导数大于0,则该点为极小值。
当然面对一个高度非线性的问题,如果利用二阶必要条件或充分条件求解,需要很多次进行二阶求导,具有很大的工作量,所以通常采用极小值的迭代求解方法,下一章将会介绍。
这篇关于[最优化导论]C6 集合约束和无约束优化问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




