本文主要是介绍2021-08-24面向自然语言处理的预训练技术研究综述 -知网论文,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘 要
近年来,随着深度学习的快速发展,面向自然语言处理领域的预训练技术获得了长足的进步。早期的自然语言处理领 域长期使用 Word2Vec等词向量方法对文本进行编码,这些词向量方法也可看作静态的预训练技术。然而,这种上下文无关的 文本表示给其后的自然语言处理任务带来的提升非常有限,并且无法解决一词多义问题(+OOV)。ELMo提出了一种上下文相关的文 本表示方法,可有效处理多义词问题。其后,GPT和 BERT等预训练语言模型相继被提出,其中 BERT模型在多个典型下游任 务上有了显著的效果提升,极大地推动了自然语言处理领域的技术发展,自此便进入了动态预训练技术的时代。此 后,基 于 BERT的改进模型、XLNet等大量预训练语言模型不断涌现,预训练技术已成为自然语言处理领域不可或缺的主流技术。文中 首先概述预训练技术及其发展历史,并详细介绍自然语言处理领域的经典预训练技术,包括早期的静态预训练技术和经典的动 态预训练技术;然后简要梳理一系列新式的有启发意义的预训练技术,包 括 基 于 BERT 的 改 进 模 型 和 XLNet;在 此 基 础 上,分 析目前预训练技术研究所面临的问题;最后对预训练技术的未来发展趋势进行展望。
在自然语言处理领域的背景下,预 训 练 技 术 通 过 使 用 大 规模无标注的文本语料来训练深层网络结构,从而得到一组 模型参数,这种深层网络结构通常被称为“预训练模型”;将预 训练好的模型参数应用到后续的其他特定任务上,这些特定 任务通常被称为“下游任务”。 通常来说,大多数基于深度学习的自然语言处理任务可 以分为以下3个模块:数 据 处 理、文本表征和特定任务模型。 其中,数据处理模块和特定任务模型模块需要根据具体任务 的不同做相应设计,而文本表征模块则可以作为一个相对通 用的模 块 来 使 用。类似于计算机视觉领域中基于 Image- Net[1]预训练模型的做法,自然语言处理领域也可以预训练一 个通用的文本表征模块,这种通用的文本表征模块对于文本 的迁移学习具有重要意义。 以 Word2Vec[2-3]为代表的词向量技术是自然语言处理 领域一直以来最常用的文本表征方法,但这种方法仅学习了 文本的浅层表征,并且这种浅层表征是上下文无关的文本表 示,对于后续任务的效果提升非常有限[4-6]。直到 ELMo[7]提 出了一种上下文相关的文本表示方法,并在多个典型下游任 务上表现惊艳,才使得预训练一个通用的文本表征模块成为 可能。随后,GPT[8]和 BERT[9]等预训练语言模型相继被提 出,自此便进入了动态预训练技术的时代。其中,BERT 在击 败11个典型下游任务的State-of-the-art结果之后,成为了自 然语言处理领域预训练技术的重要里程碑,极大地推动了自 然语言处理领域的发展。此后,基于 BERT 的改进模型、XL- Net[10]等大量预训练语言模型涌出,预训练技术逐渐发展成 了自然语言处理领域不可或缺的主流技术。 预训练技术取得的巨大成功,很大程度上归功于其实现 了迁移学习[11]的 概 念。迁移学习本质上是在一个数据集上 训练基础模型,通过微调等方式,使得模型可以在其他不同的 数据集上处理不同的任务。预训练的过程如上文所 述,是 将 预训练好的模型的相应结构和权重直接应用到下游任务上, 从而实现“迁移学习”[12-15]的 概 念,即将预训练模型“迁 移”到 下游任务。 本文主要概述面向自然语言处理领域的预训练技术。按 照时间顺序,预训练技术大致可分为3个阶段:早期的静态预 训练技术、经典的动态预训练技术和最新发布的新式预训练 技术。第2节简要概述预训练技术的整个发展历史;第3节 详细介绍自然语言处理领域早期的静态预训练技术和经典的 动态预训练技术;第4节主要梳理近期发布的有启发意义 的 新式预训练技术;第5节分析目前预训练技术研究所面临 的 问题;第6节对自然语言处理领域的预训练技术的未来发 展 趋势进行展望。
预训练语言模型的核心在于关键范式的转变:从 只 初 始 化模型的第一层,转向了预训练一个多层网络结构。传 统 的 词向量方法只使用预训练好的静态文本表示,初始化下游任 务模型的第一层,而下游任务模型的其余网络结构仍然需要 从头开始训练。这是一种以效率优先而牺牲表达力的浅层方 法,无法捕捉到那些也许更有用的深层信 息[34-36];更 重 要 的 是,其本质上是一种静态的方式,无法消除词语歧义。而预训 练语言模型是预训练一个多层网络结构,用以初始化下游任 务模型的多层网络结构,可以同时学到浅层信息和深层信息。 此外,预训练语言模型是一种动态的文本表示方法,会根据当 前上下文对文本表征进行动态调整,经过调整后的文本表征 更能表达词语在该上下文中的具体含义,能有效处理一词多 义的问题。
3.1 静态预训练技术
2003年Bengio提出的 NNLM 是早期使用神经网络实现 语言模型的经典模型。2013年,Word2Vec借鉴 NNLM 的思 想,提出用语言模型得到词向量。随 后,GloVe和 FastText 相继被提出,这种静态的预训练技术逐渐成为了最常用的文 本表征技术。 3.1.1 NNLM 模型 NNLM 使用神经网络来搭建语言模型,并且优化后的 模 型的副产品就是词向量。语言模型能够量化一个句子近似人 类自然表达的概率,如 果 文 本 序 列 S 用(w0,w1,…,wt-1)来 表示,那么语言模型即计算: P(S)=P(w0)P(w1|w0)…P(wt-1|w0,w1,…,wt-2) (1) 但式(1)的计算过 于 复 杂。早期基于统计的语言模型一 般会引入马尔可夫假设:假定一个句子中的词只与它前面的 n个词相关,并且用词频来估计语言模型中的条件概率,这 使 得语言模型的计算变得可行。然 而,这种基于统计的语言模 型无法把n取得很大,否则会带来参数过多的问题,因而无法 建模语言中上下文较长的依赖关系,具有很大的局限性。 2003年,Bengio将深度学习的思想融入语言模型中,并 发现将训练得到的 NNLM 模型的第一层参数当作词语的文 本表征时,能够很好地获取词语之间的相似度[26]。 NNLM 模型的结构如 图1所 示,
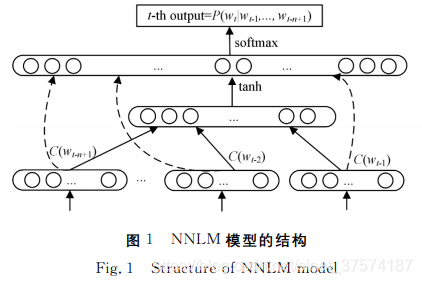
分 为3个 部 分:词 到 词 向量的映射;词向量到隐藏层的映射;隐 藏 层 到 输 出 层 的 映 射。其损失函数如下:
![]()
L= 1 T∑t logP(wt|wt-1,…,wt-n+1;θ)+R(θ) (2)
其中,R(θ)为正 则 化 项。由损失函数可以看出,NNLM 本 质 上是一个 N-Gram 的语言模 型。此 外,NNLM 的 参 数 个 数 是 窗口大小为n的线性函数,此时的取值不再受模型参数量的 限制,因此能对更长的依赖关系进行建模。
GloVe其实是没有网 络 结 构 的,整个算法都是基于矩阵 分解的 做 法 来 获 取 词 向 量,本 质 上 与 LSA[42]这 种 基 于 SVD[43]的矩阵分解方法类似。
3.2.1 ELMo模型
静态的词向量方法存在一个重要缺陷,即 无 法 较 好 地 处 理一词多义问题(+OOV);而 ELMo通过使用针对语言模型训练好的 双向 LSTM 来构建文本表示,由此捕捉上下文相关的词义 信 息,因而可以更好地处理一词多义问题。 为了使用大规模无监督语料,ELMo使用两层带残差的 双向 LSTM 来训 练 语 言 模 型,如 图 2所 示。
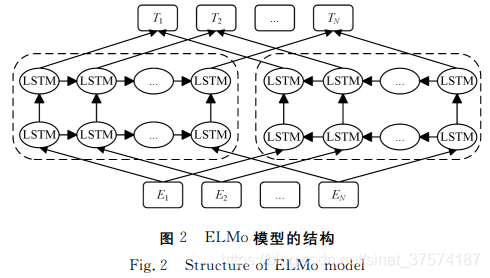
此 外,ELMo借 鉴了Jozefowicz等[45]的 做 法,针对英文形态学上的特点,在 预训练模型的输入层和输出层使用了字符级的 CNN 结 构。 这种结构大幅减小了词表的规模,很好地解决了未登录词的 问题;卷积操作也可以捕获一些英文中的形态学信 息;同 时, 训 练 双 向 的 LSTM,不仅考虑了上文信息,也 融 合 了 下 文 信息。
从预训练模型的迁移方式来看,ELMo是一种特征抽取 式的预训练模型。对于 第k个 词 来 说,ELMo有3层 的 文 本 表示可 以 利 用:输 入 层 CNN 的 输 出hk,0、第 一 层 双 向 LSTM 的输出hk,1和第二层双向 LSTM 的输出hk,2。设3层 文 本 表 示如下:
![]()
Rk={hk,j}(j=0,1,2) (5)
则第k个词经过预训练模型得到的文本表示为:
![]()
其中,γtask是一个缩放因子,用以将 ELMo输出的向量 与 下 游 任务的向量拉到 同 一 分 布;stask j 是针对每一层的输出向量设 置的不同权值参数,用以组合不同层次的语义信息。 ELMo模型不仅简单,而且表现出众,在自然语言处理领 域的6个典型下游任务的数据集上全面刷新了最优成绩,尤 其在阅读理解任务上提高了4.7个 点[12]。其 主 要 贡 献 是 提 供了一种新的文本表征的思路:在大规模无监督数据上训练 预训练语言模型,并将其迁移到下游特定任务中使用。
Masked-LM 预训练类似于一种完形填空的任务,即在预 训练时,随机遮盖输入文本序列的部分词语,在输出层获得该 位置的概率分布,进而极大化似然概率来调整模型参数。文 献[9]实际随机选择文本序列中15%的词用于后续替换,但 这些词也并非全部被替换为[MASK],其 中10%替 换 为 随 机 词,10%保持不变。这种操作可以理解为通过引入噪声来增 强模型的鲁棒性。 与此同时,为了更好地处理多个句子之间的关系,BERT 还利用和借鉴 了 Skip-thoughts[26]中 预 测 下 一 句 的 任 务 来 学 习句子级别的语义关系。具体做法是:按照 GPT提出的组合 方式将两个句子组合成一个序列,模型预测后面句子是否为 前面句 子 的 下 文,也就是建模预测下一句的任务。因 此, BERT的预训练过程实质上是一个多任务学习的过程,同 时 完成训练 Masked-LM 和预测下一句这两个任务,损 失 函 数 也由这两个任务的损失组成。 在预 训 练 细 节 上,BERT 借 鉴 了 ULMFiT 的 一 系 列 策略,使模型更易于训练。在如何迁移到下游任务方面,BERT 主要借鉴了 GPT的迁移学习框架的思想,并设计了更通用的 输入层和输出层。此外,在预训练数据、预训练模型参数量和 计算资源上,BERT 也 远 多 于 早 期 的 ELMo和 GPT。BERT 的表现是里程碑式的,在自然语言处理领域的11项基本任务 中获得了显著的效果提升。而自然语言处理领域的许多后续 研究一般也以 BERT 模型为基础进行改进,学 界 普 遍 认 为, 从 BERT模型开始,自然语言处理领域终于找到了一种方法 可以像计算机视觉那样进行迁移学习。 总而言之,BERT的出现是建立在前期很多重要工作之 上 的,包 括 ELMo,ULMFiT,GPT,Transformer以 及 Skip- thoughts等,是一个 集 大 成 者。BERT 的出现极大地推动了 自然语言处理领域的发展,凡需要构建自然语言处理模型者, 均可将这个强大的预训练模型作为现成的组件使用,从而节 省了从头开始训练模型所需的时间、精力、知识和资源。
这篇关于2021-08-24面向自然语言处理的预训练技术研究综述 -知网论文的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






