本文主要是介绍论文阅读:Zoom-Net:Mining Deep Feature Interactions for Visual Relationship Recognition(ECCV18),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

这篇论文有两个亮点,第一个是SCA-Module,第二个是损失函数的求法。整个框架还是很简洁明了的,就不多说了。
1.Spatiality-Context-Apperance Module(SCA-M)
总共计算了五种特征,主宾各一种,谓语三种。图上画得挺清楚的,就不细说了。

谓语的三种特征计算的这种结构叫做Contrasive ROI Pooling,是用来感知空间位置关系的
主语和宾语的计算结构叫做Pyramid ROI Pooling,是把global的谓语特征传播到了local的物体特征
Zoom-Net使用了两个SCA-M,第一个作者说用来融合不同分支间的空间上下文,第二个用来多尺度交互
2.损失函数
首先,作者把VG数据集的物体类别和谓语类别分成了两个Intra-Hierarchical Tree(简称IH-Tree)

模型最终的输出是IH-Tree三个层级softmax cat在一起的结果,三个分支的loss是这个softmax的损失之和。这样的loss鼓励层级内的排斥和层级间的依赖。
总loss:作者设的都是1
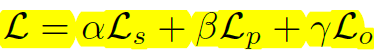
这篇关于论文阅读:Zoom-Net:Mining Deep Feature Interactions for Visual Relationship Recognition(ECCV18)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







