本文主要是介绍Hands-on Machine Learning with Scikit-Learn,Keras TensorFlow,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
读书记录(缓慢更新)
目录
Part 1. The Fundamentals of Machine Learning
The Content of The Machine Learning Landscape
The Machine Learning Landscape
What Is Machine Learning?
Why Use Machine Learning?
Types of Machine Learning Systems
Part 1. The Fundamentals of Machine Learning
The Content of The Machine Learning Landscape
Part 1. The Fundamentals(fundament n.基础;臀部) of Machine Learning 机器学习的基础
1.The Machine Learning Landscape(n.景色;形势 v.对……做景观美化) 机器学习的前景
What Is Machine Learning? 什么是机器学习
Why Use Machine Learning? 为什么使用机器学习
Types of Machine Learning Systems 机器学习系统的类型
Supervised/Unsupervised(supervise v.监督) Learning 监督/无监督学习
Batch(n.一批 v.分批处理) and Online Learning 批处理和在线学习
Instance-Based Versus(与) Model-Based Learning 基于实例与基于模型的学习
Main Challenges of Machine Learning 机器学习的主要挑战
Insufficient(sufficient a.充足的) Quantity(n.数目;大量) of Training Data 训练数据不足
Nonrepresentative(represent v.代表) Training Data 非代表性训练数据
Poor-Quality Data 低质量数据
Irrelevant(relevant a.相关的;正确的;适宜的;有价值的) Features 无关的特征
Overfitting(overfit n.过拟合) the Training Data 过拟合训练数据
Underfitting(underfit n.欠拟合) the Training Data 欠拟合训练数据
Stepping(step n.迈步;脚步;梯级;台阶;步骤;措施;阶段;进程 v.跨步走;(短距离)移动;行走) Back 退一步?
Testing and Validating(validate v.批准;证实;确认……有效) 测试和验证
Hyperparameter(parameter n.界限;范围;参数;变量) Tuning(tune n.曲调;歌曲 v.调整;校音) and Model Selection 超参数调优和模型选择
Data Mismatch(match n.比赛;对手;配偶;婚姻 v.比得上;使相配) 数据不匹配
Exercises
The Machine Learning Landscape
With Early Release ebooks(n. 电子书), you get books in their earliest form-the author's raw and unedited content as he or she writes--so you can take advantage of(take advantage of... 利用...) these technologies long before the official release of these titles. The following will be Chapter 1 in the final release of the book.
When most people hear "Machine Learning," they picture(n. 图片;绘画;照片;肖像 v.想象;绘画;拍摄) a robot: a dependable butler(n. 管家) or a deadly Terminator(终结者) depending on who you ask. But Machine Learning is not just a futuristic(a. 未来主义的) fantasy, it's already here. In fact, it has been around for decades in some specialized applications(n. 申请书;应用;程序), such as Optical Character Recognition(OCR)(光学字符识别). But the first ML application that really became mainstream(n.主流 a.主流的 v.使主流化), improving the lives of hundredsof millions of people, took over(take over 接管;控制) the world back in the 1990s: it was the spam filter(垃圾邮件过滤器 spam n.垃圾邮件 v.向..群发垃圾邮件 filter n.过滤器;滤光器;滤声器;滤波器;过滤程序 v. 过滤;渗入;透过).Not exactly a self-aware(a. 有自我意识的) Skynet(天网 ?框架), but it does technically qualify as Machine Learning(it has actually learned so well that you seldom need to flag an email as spam anymore)(但从技术上讲,它在技术上符合机器学习(它实际上已经学得很好了,你几乎不需要把电子邮件标记为垃圾邮件了). It was followed by(followed by 后面有;接着是) hundreds of ML applications that now quietly power(驱动) hundreds of products and features that you use regularly(regular a. 常规的 n. 常客), from better recommendations(recommend v. 建议;劝告;推荐;介绍) to voice search(接着是数百个机器学习应用程序,这些应用程序现在悄悄地为您经常使用的数百种产品和功能提供支持,从更好的推荐到语音搜索).
Where does Machine Learning start and where does it end? What exactly does it mean for a machine to learn something? If I download a copy of Wikipedia(维基百科), has my computer really “learned” something? Is it suddenly smarter? In this chapter we will start by clarifying(clarify v. 澄清;阐明) what Machine Learning is and why you may want to use it.
Then, before we set out(出发) to explore the Machine Learning continent(n. 大陆;洲), we will take alook at the map and learn about the main regions(n. 地区;地域;领域;身体部位) and the most notable(a. 显要的;值得注意的 n.显要人物;名流) landmarks(n. 地标;里程碑;转折点):supervised versus(prep. 与……相比;以……为对手) unsupervised learning, online versus batch learning, instance-based versus model-based learning. Then we will look at the workflow(n. 工作流程) of a typical ML project, discuss the main challenges you may face, and cover how to evaluate and fine-tune(调好 ?微调) a Machine Learning system.
This chapter introduces a lot of fundamental concepts (and jargon(n. 专业术语)) that every data scientist should know by heart. It will be a high-level overview(n/v. 概述;综述) (the only chapter without much code), all rather simple, but you should make sure everything is crystal-clear(a. 非常清楚的 crystal n.晶体;水晶 a.晶莹的;清澈透明的) to you before continuing to the rest(n/v. 休息 n. 剩余部分) of the book. So grab(n/v. 抓住) a coffee and let’s get started!
If you already know all the Machine Learning basics, you may want to skip(v. 跳过 n.蹦跳) directly(direct a. 直接的;径直的;坦率的 v. 给……指路;指引;引导;导演;指示;命令) to Chapter 2. If you are not sure, try to answer all the questions listed at the end of the chapter before moving on.
What Is Machine Learning?
Machine Learning is the science (and art) of programming computers so they can learn from data.
Here is a slightly(slight a. 轻微的;少量的 v. 怠慢;轻视 n. 冒犯;冷落) more general(a. 普遍的;一般的;常规的;大概的) definition(define v. 给……下定义,解释;阐明):
[Machine Learning is the] field of study that gives computers the ability to learn without being explicitly programmed. —Arthur Samuel, 1959
And a more engineering-oriented(面向工程的 orient v. 朝向;面对;确定方位) one: A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E. —Tom Mitchell, 1997
For example, your spam filter is a Machine Learning program that can learn to flag spam given examples of spam emails (e.g., flagged by users) and examples of regular (nonspam, also called “ham”) emails. The examples that the system uses to learn are called the training set. Each training example is called a training instance (or sample). In this case, the task T is to flag spam for new emails, the experience E is the training data, and the performance measure P needs to be defined; for example, you can use the ratio(n. 比率;比例) of correctly classified emails. This particular(a. 特定的 n. 详细资料) performance(n. 表演;表现;性能 a. 高性能的) measure(n. 措施;办法;度量单位 v. 测量;估量;记录) is called accuracy(n. 准确性;准确) and it is often used in classification tasks.
If you just download a copy of Wikipedia, your computer has a lot more data, but it is not suddenly better at any task. Thus, it is not Machine Learning.
Why Use Machine Learning?
Consider how you would write a spam filter using traditional programming techni‐ ques (Figure(n. 数字;数目;身材;图形;价格 v. 估计;理解;计算;用图画想象) 1-1):
1. First you would look at what spam typically looks like. You might notice that some words or phrases(phrase n. 短语;词组;惯用语;习语 v. 用……方式表达;以……措辞表达) (such as “4U,” “credit(n. 信用;信贷;赞扬;信誉;声望;余额;补助;学分 v. 把钱存入(账户);相信) card,” “free,” and “amazing”) tend to come up(接近;出现;到达) a lot in the subject(n. 主题;话题;学科;科目;课程 v. 使臣服;征服 a. 隶属的,臣服的). Perhaps you would also notice a few other patterns(pattern n. 模式;模型;样品 v. 用图案装饰;给……加上花样;模仿) in the sender’s(sender n. 发送人) name, the email’s body(电子邮件正文), and so on.
2. You would write a detection algorithm(检测算法 detect v. 察觉;检测;识别) for each of the patterns that you noticed, and your program would flag emails as spam if a number of these patterns are detected.
3. You would test your program, and repeat steps 1 and 2 until it is good enough.

Since the problem is not trivial(a. 琐碎的;不重要的), your program will likely become a long list of com‐ plex rules—pretty hard to maintain.
In contrast(相比之下 contrast n/v. 对比 n. 差异), a spam filter based on Machine Learning techniques automatically(automatical a. 自动的) learns which words and phrases are good predictors(predict v. 预测;预言) of spam by detecting unusually frequent patterns of words in the spam examples compared to the ham examples(正常邮件示例) (Figure 1-2). The program is much shorter, easier to maintain(v. 保持;维修;主张;赡养), and most likely more accurate(a .准确的;精确的).
 Moreover, if spammers(spammer n. 垃圾邮件制作者) notice that all their emails containing “4U” are blocked, they might start writing “For U” instead. A spam filter using traditional programming techniques would need to be updated to flag “For U” emails. If spammers keep work‐ ing around your spam filter, you will need to keep writing new rules forever.
Moreover, if spammers(spammer n. 垃圾邮件制作者) notice that all their emails containing “4U” are blocked, they might start writing “For U” instead. A spam filter using traditional programming techniques would need to be updated to flag “For U” emails. If spammers keep work‐ ing around your spam filter, you will need to keep writing new rules forever.
In contrast, a spam filter based on Machine Learning techniques automatically noti‐ ces that “For U” has become unusually frequent in spam flagged by users, and it starts flagging them without your intervention(n. 干预;介入;调停) (Figure 1-3).

Another area where Machine Learning shines(shine v. 发光;出众;擦亮 n. 光亮;光泽) is for problems that either are too complex for traditional approaches or have no known algorithm(机器学习的另一个亮点是针对传统方法过于复杂或没有已知算法的问题). For example, consider speech recognition(语音识别 speech v. 演说;发言 recognize v. 认识;辨别出;承认;意识到): say you want to start simple and write a program capable(a. 有能力的;可以....的) of distinguishing(distinguish v. 区别;认出) the words “one” and “two.” You might notice that the word “two” starts with a high-pitch(高音调) sound (“T”), so you could hardcode an algorithm(编写一个算法) that measures high-pitch sound intensity(n. (光、声音等的)强度;强烈) and use that to distinguish ones and twos. Obviously this technique will not scale(n. 天平;等级;刻度;规模;范围;比例;鳞片;水垢;牙垢;音阶 v. 改变(文字、图片)的尺寸大小;刮去)鱼鳞);翻越;剔除(牙垢) a. (模型或复制品)按比例缩小的) to thousands of words spoken by millions of very different people in noisy environments and in dozens of languages. The best solution (at least today(至少在当今)) is to write an algorithm that learns by itself, given many example recordings for each word.
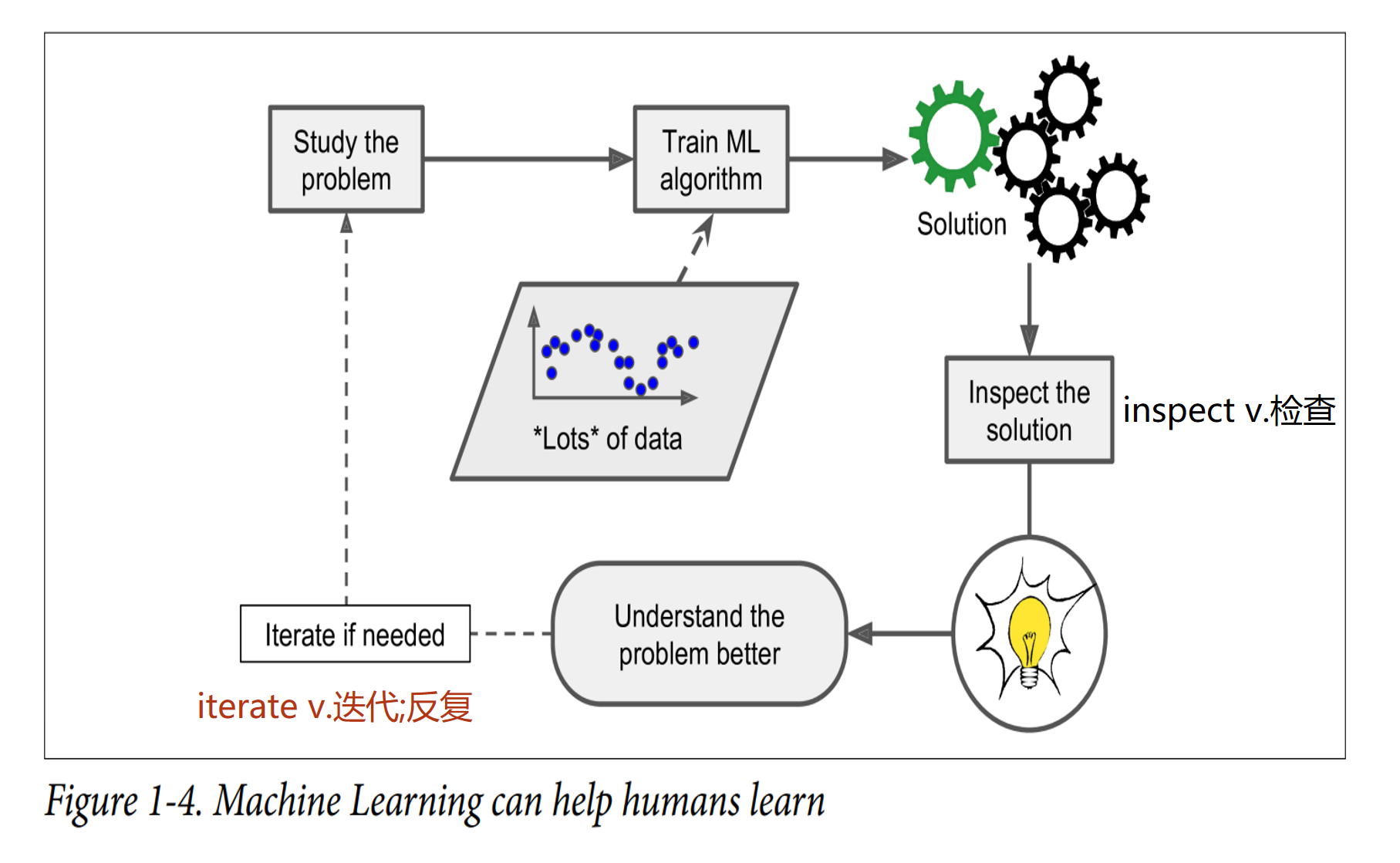
Finally, Machine Learning can help humans learn (Figure 1-4): (机器学习可帮助人类学习(图 1-4))ML algorithms can be inspected to see what they have learned(可以检查机器学习算法,看看他们学到了什么) (although for some algorithms this can be tricky(a. 棘手的;狡猾的 trick n. 诡计;骗局;技巧 v. 欺骗 a. 骗人的)). For instance, once the spam filter has been trained on enough spam, it can easily be inspected to reveal(v. 揭示;显示) the list of words and combinations(combination n. 组合;结合) of words that it believes are the best predictors(predictor n. 预测器) of spam(可以很容易地检查它,以显示它认为是垃圾邮件的最佳预测器的单词列表和单词组合). Sometimes this will reveal unsuspected(a. 未知的 suspect v. 怀疑;猜想 n. 可疑分子 a. 可疑的;不可靠的) correlations(correlation n. 相关;相关性) or new trends, and thereby(ad. 因此;从而) lead to a better understanding of the problem.
Applying(apply v. 申请;应用) ML techniques to dig(v. 挖掘;寻找 n. 挖苦;考古挖掘) into large amounts of data can help discover patterns that were not immediately apparent(a. 显而易见的;表面上的). This is called data mining. 应用机器学习技术来挖掘大量数据可以帮助发现那些没有立即显现出来的模式。这被称为数据挖掘。
To summarize, Machine Learning is great for:
• Problems for which existing solutions require a lot of hand-tuning or long lists of rules: one Machine Learning algorithm can often simplify code and perform bet‐ ter.
• Complex problems for which there is no good solution at all using a traditional approach: the best Machine Learning techniques can find a solution.
• Fluctuating(fluctuate v. 波动) environments: a Machine Learning system can adapt to new data.
• Getting insights(insight n. 见解;了解) about complex problems and large amounts of data.
Types of Machine Learning Systems
There are so many different types of Machine Learning systems that it is useful to classify them in broad(a. 广泛的;大致的) categories(broad categories大类) based on:
• Whether or not(是否) they are trained with human supervision (supervised, unsupervised, semisupervised, and Reinforcement Learning)(监督、无监督、半监督和强化学习)
• Whether or not they can learn incrementally on the fly (online versus batch learning)(在线学习与批处理学习)
• Whether they work by simply comparing new data points to known data points, or instead detect patterns in the training data and build a predictive(a. 预言性的) model(预测模型), much like scientists do (instance-based versus model-based learning)(基于实例的学习与基于模型的学习)
These criteria(n. 标准) are not exclusive(a. 独有的;排斥的 n. 独家新闻); you can combine them in any way you like. For example, a state-of-the-art spam filter may learn on the fly using a deep neural network(深度神经网络) model trained using examples of spam and ham; this makes it an online, modelbased, supervised learning system(基于模型的在线监督学习系统).
Let’s look at each of these criteria a bit more closely.
Supervised/Unsupervised
Learning Machine Learning systems can be classified according to the amount and type of supervision they get during training. There are four major categories: supervised learning, unsupervised learning, semisupervised learning, and Reinforcement Learning.
Supervised learning
In supervised learning, the training data you feed to the algorithm includes the desired solutions, called labels (Figure 1-5).
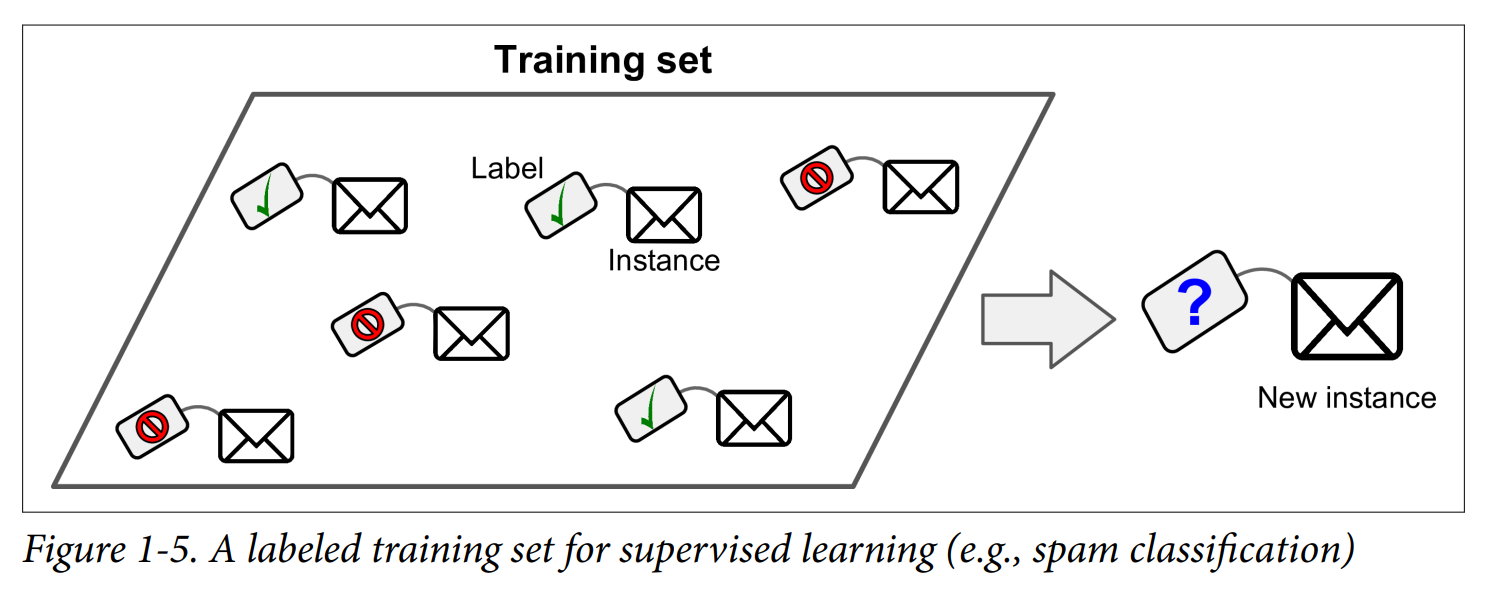
A typical supervised learning task is classification. The spam filter is a good example of this: it is trained with many example emails along with their class (spam or ham), and it must learn how to classify new emails.
Another typical task is to predict a target numeric value, such as the price of a car, given a set of features (mileage, age, brand, etc.) called predictors. This sort of task is called regression (Figure 1-6).1 To train the system, you need to give it many examples of cars, including both their predictors and their labels (i.e., their prices).
In Machine Learning an attribute is a data type (e.g., “Mileage”), while a feature has several meanings depending on the context, but generally means an attribute plus its value (e.g., “Mileage = 15,000”). Many people use the words attribute and feature inter‐ changeably, though.
这篇关于Hands-on Machine Learning with Scikit-Learn,Keras TensorFlow的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









