本文主要是介绍助力打造清洁环境,基于YOLOv4开发构建公共场景下垃圾堆放垃圾桶溢出检测识别系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
公共社区环境生活垃圾基本上是我们每个人每天几乎都无法避免的一个问题,公共环境下垃圾投放点都会有固定的值班时间,但是考虑到实际扔垃圾的无规律性,往往会出现在无人值守的时段内垃圾堆放垃圾桶溢出等问题,有些容易扩散的垃圾比如:碎纸屑、泡沫粒等等,一旦遇上大风天气往往就会被吹得遍地都是给垃圾清理工作带来负担。
本文的主要目的及时想要探索分析通过接入社区实时视频流数据来对公共环境下的垃圾投放点进行自动化的智能分析计算,当探测到异常问题比如:随意堆放垃圾、垃圾桶溢出等问题的时候结合一些人工业务预设的规则来自动通过短信等形式推送事件给相关的工作人员来进行及时的处置这一方案的可行性,博文主要是侧重对检测模型的开发实现,业务规则需要到具体的项目中去细化,这块就不作为文本的实践内容。
首先看下实例效果:
YOLOv4比YOLOv3多了CSP和PAN结构,YOLOv4使用CSPDarknet53作为backbone,加上SPP模块、PANet作为网络的颈部,Head部分仍采用YOLOv3的结构。
总结一下YOLOv4的基本组件,总共5个:
CBM:YOLOv4的网络结构中最小的组件,由Conv+BN+Mish激活函数组成
CBL:由Conv+Bn+Leaky_relu激活函数组成。
Res Unit:残差结构,类似ResNet
CSPX:由三个卷积层和X个Res Unit模块concate组成
SPP:采用1×1,5×5,9×9,13×13的最大池化方式,进行多模融合
Yolov4集成了当时领域内的一些Tricks如:WRC、CSP、CmBN、SAT、Mish激活、Mosaic数据增强、DropBlock和CIoU通过实验对模型的精度和速度进行了平衡.YOLOv4借鉴了CSPNet(Cross Stage Partial Networks,跨阶段局部网络)的思想,对YOLOv3的Darknet53网络进行了改进,形成了全新的主干网路结构--CSPDarknet53,CSPNet实际上是基于Densnet的思想,即首先将数据划分成Part 1和Part 2两部分,Part 2通过dense block发送副本到下一个阶段,接着将两个分支的信息在通道方向进行Concat拼接,最后再通过Transition层进一步融合。CSPNet思想可以和ResNet、ResNeXt和DenseNet结合,目前主流的有CSPResNext50 和CSPDarknet53两种改造Backbone网络。
采用CSP结构有如下几点好处:
1.加强CNN学习能力
2.删除计算瓶颈
3.减少显存开销
SPP输入的特征层依次通过一个卷积核大小为5×5,9×9,13×13的最大池化下采样层,然后将这三个输出的特征层和原始的输入的特征层进行通道拼接。通过SPP结构能够在一定程度上解决多出尺度的问题;PAN来自于PANet(Path Aggregation Network),实际上就是在原来的FPN结构上又加上了一个从低层到高层的融合。在YOLOv4里面的特征融合采用的是concat通道拼接。
当然了还有训练策略、数据增强等其他方面的创新技术这里就不再展开了介绍了,感兴趣的话可以自行查询相关的资料即可。
这里是基于实验性的想法做的实践项目,简单看下数据集:
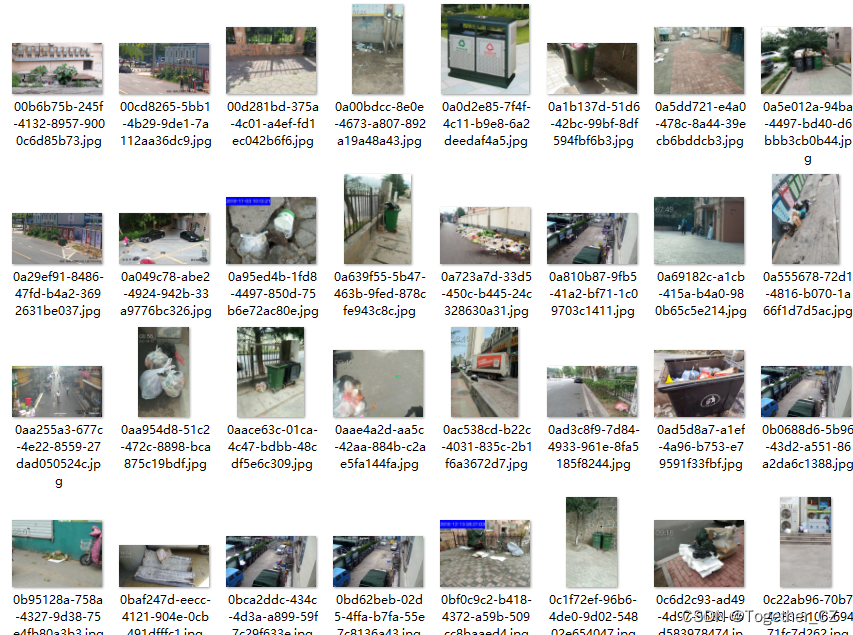

如果对如何使用yolov4项目来开发构建自己的目标检测系统有疑问的可以看我前面的超详细博文教程:
《基于官方YOLOv4开发构建目标检测模型超详细实战教程【以自建缺陷检测数据集为例】》
《基于官方YOLOv4-u5【yolov5风格实现】开发构建目标检测模型超详细实战教程【以自建缺陷检测数据集为例】》
本文的项目开发是以第一篇教程为实例进行的,当然了如果想要使用第二篇的教程本质上也都是一样的。
self.names如下:
trash_over
garbage
trash_no_fullself.yaml如下:
# path
train: ./dataset/images/train/
val: ./dataset/images/test/
test: ./dataset/images/test/# number of classes
nc: 3# class names
names: ['trash_over', 'garbage', 'trash_no_full']train.py如下所示:
import argparse
import logging
import math
import os
import random
import time
from pathlib import Path
from warnings import warnimport numpy as np
import torch.distributed as dist
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.optim.lr_scheduler as lr_scheduler
import torch.utils.data
import yaml
from torch.cuda import amp
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.tensorboard import SummaryWriter
from tqdm import tqdmimport test # import test.py to get mAP after each epoch
#from models.yolo import Model
from models.models import *
from utils.autoanchor import check_anchors
from utils.datasets import create_dataloader
from utils.general import labels_to_class_weights, increment_path, labels_to_image_weights, init_seeds, \fitness, fitness_p, fitness_r, fitness_ap50, fitness_ap, fitness_f, strip_optimizer, get_latest_run,\check_dataset, check_file, check_git_status, check_img_size, print_mutation, set_logging
from utils.google_utils import attempt_download
from utils.loss import compute_loss
from utils.plots import plot_images, plot_labels, plot_results, plot_evolution
from utils.torch_utils import ModelEMA, select_device, intersect_dicts, torch_distributed_zero_firstlogger = logging.getLogger(__name__)try:import wandb
except ImportError:wandb = Nonelogger.info("Install Weights & Biases for experiment logging via 'pip install wandb' (recommended)")def train(hyp, opt, device, tb_writer=None, wandb=None):logger.info(f'Hyperparameters {hyp}')save_dir, epochs, batch_size, total_batch_size, weights, rank = \Path(opt.save_dir), opt.epochs, opt.batch_size, opt.total_batch_size, opt.weights, opt.global_rank# Directorieswdir = save_dir / 'weights'wdir.mkdir(parents=True, exist_ok=True) # make dirlast = wdir / 'last.pt'best = wdir / 'best.pt'results_file = save_dir / 'results.txt'# Save run settingswith open(save_dir / 'hyp.yaml', 'w') as f:yaml.dump(hyp, f, sort_keys=False)with open(save_dir / 'opt.yaml', 'w') as f:yaml.dump(vars(opt), f, sort_keys=False)# Configureplots = not opt.evolve # create plotscuda = device.type != 'cpu'init_seeds(2 + rank)with open(opt.data) as f:data_dict = yaml.load(f, Loader=yaml.FullLoader) # data dictwith torch_distributed_zero_first(rank):check_dataset(data_dict) # checktrain_path = data_dict['train']test_path = data_dict['val']nc, names = (1, ['item']) if opt.single_cls else (int(data_dict['nc']), data_dict['names']) # number classes, namesassert len(names) == nc, '%g names found for nc=%g dataset in %s' % (len(names), nc, opt.data) # check# Modelpretrained = weights.endswith('.pt')if pretrained:with torch_distributed_zero_first(rank):attempt_download(weights) # download if not found locallyckpt = torch.load(weights, map_location=device) # load checkpointmodel = Darknet(opt.cfg).to(device) # createstate_dict = {k: v for k, v in ckpt['model'].items() if model.state_dict()[k].numel() == v.numel()}model.load_state_dict(state_dict, strict=False)print('Transferred %g/%g items from %s' % (len(state_dict), len(model.state_dict()), weights)) # reportelse:model = Darknet(opt.cfg).to(device) # create# Optimizernbs = 64 # nominal batch sizeaccumulate = max(round(nbs / total_batch_size), 1) # accumulate loss before optimizinghyp['weight_decay'] *= total_batch_size * accumulate / nbs # scale weight_decaypg0, pg1, pg2 = [], [], [] # optimizer parameter groupsfor k, v in dict(model.named_parameters()).items():if '.bias' in k:pg2.append(v) # biaseselif 'Conv2d.weight' in k:pg1.append(v) # apply weight_decayelif 'm.weight' in k:pg1.append(v) # apply weight_decayelif 'w.weight' in k:pg1.append(v) # apply weight_decayelse:pg0.append(v) # all elseif opt.adam:optimizer = optim.Adam(pg0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentumelse:optimizer = optim.SGD(pg0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)optimizer.add_param_group({'params': pg1, 'weight_decay': hyp['weight_decay']}) # add pg1 with weight_decayoptimizer.add_param_group({'params': pg2}) # add pg2 (biases)logger.info('Optimizer groups: %g .bias, %g conv.weight, %g other' % (len(pg2), len(pg1), len(pg0)))del pg0, pg1, pg2# Scheduler https://arxiv.org/pdf/1812.01187.pdf# https://pytorch.org/docs/stable/_modules/torch/optim/lr_scheduler.html#OneCycleLRlf = lambda x: ((1 + math.cos(x * math.pi / epochs)) / 2) * (1 - hyp['lrf']) + hyp['lrf'] # cosinescheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)# plot_lr_scheduler(optimizer, scheduler, epochs)# Loggingif wandb and wandb.run is None:opt.hyp = hyp # add hyperparameterswandb_run = wandb.init(config=opt, resume="allow",project='YOLOv4' if opt.project == 'runs/train' else Path(opt.project).stem,name=save_dir.stem,id=ckpt.get('wandb_id') if 'ckpt' in locals() else None)# Resumestart_epoch, best_fitness = 0, 0.0best_fitness_p, best_fitness_r, best_fitness_ap50, best_fitness_ap, best_fitness_f = 0.0, 0.0, 0.0, 0.0, 0.0if pretrained:# Optimizerif ckpt['optimizer'] is not None:optimizer.load_state_dict(ckpt['optimizer'])best_fitness = ckpt['best_fitness']best_fitness_p = ckpt['best_fitness_p']best_fitness_r = ckpt['best_fitness_r']best_fitness_ap50 = ckpt['best_fitness_ap50']best_fitness_ap = ckpt['best_fitness_ap']best_fitness_f = ckpt['best_fitness_f']# Resultsif ckpt.get('training_results') is not None:with open(results_file, 'w') as file:file.write(ckpt['training_results']) # write results.txt# Epochsstart_epoch = ckpt['epoch'] + 1if opt.resume:assert start_epoch > 0, '%s training to %g epochs is finished, nothing to resume.' % (weights, epochs)if epochs < start_epoch:logger.info('%s has been trained for %g epochs. Fine-tuning for %g additional epochs.' %(weights, ckpt['epoch'], epochs))epochs += ckpt['epoch'] # finetune additional epochsdel ckpt, state_dict# Image sizesgs = 64 #int(max(model.stride)) # grid size (max stride)imgsz, imgsz_test = [check_img_size(x, gs) for x in opt.img_size] # verify imgsz are gs-multiples# DP modeif cuda and rank == -1 and torch.cuda.device_count() > 1:model = torch.nn.DataParallel(model)# SyncBatchNormif opt.sync_bn and cuda and rank != -1:model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)logger.info('Using SyncBatchNorm()')# EMAema = ModelEMA(model) if rank in [-1, 0] else None# DDP modeif cuda and rank != -1:model = DDP(model, device_ids=[opt.local_rank], output_device=opt.local_rank)# Trainloaderdataloader, dataset = create_dataloader(train_path, imgsz, batch_size, gs, opt,hyp=hyp, augment=True, cache=opt.cache_images, rect=opt.rect,rank=rank, world_size=opt.world_size, workers=opt.workers)mlc = np.concatenate(dataset.labels, 0)[:, 0].max() # max label classnb = len(dataloader) # number of batchesassert mlc < nc, 'Label class %g exceeds nc=%g in %s. Possible class labels are 0-%g' % (mlc, nc, opt.data, nc - 1)# Process 0if rank in [-1, 0]:ema.updates = start_epoch * nb // accumulate # set EMA updatestestloader = create_dataloader(test_path, imgsz_test, batch_size*2, gs, opt,hyp=hyp, cache=opt.cache_images and not opt.notest, rect=True,rank=-1, world_size=opt.world_size, workers=opt.workers)[0] # testloaderif not opt.resume:labels = np.concatenate(dataset.labels, 0)c = torch.tensor(labels[:, 0]) # classes# cf = torch.bincount(c.long(), minlength=nc) + 1. # frequency# model._initialize_biases(cf.to(device))if plots:plot_labels(labels, save_dir=save_dir)if tb_writer:tb_writer.add_histogram('classes', c, 0)if wandb:wandb.log({"Labels": [wandb.Image(str(x), caption=x.name) for x in save_dir.glob('*labels*.png')]})# Anchors# if not opt.noautoanchor:# check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz)# Model parametershyp['cls'] *= nc / 80. # scale coco-tuned hyp['cls'] to current datasetmodel.nc = nc # attach number of classes to modelmodel.hyp = hyp # attach hyperparameters to modelmodel.gr = 1.0 # iou loss ratio (obj_loss = 1.0 or iou)model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) # attach class weightsmodel.names = names# Start trainingt0 = time.time()nw = max(round(hyp['warmup_epochs'] * nb), 1000) # number of warmup iterations, max(3 epochs, 1k iterations)# nw = min(nw, (epochs - start_epoch) / 2 * nb) # limit warmup to < 1/2 of trainingmaps = np.zeros(nc) # mAP per classresults = (0, 0, 0, 0, 0, 0, 0) # P, R, mAP@.5, mAP@.5-.95, val_loss(box, obj, cls)scheduler.last_epoch = start_epoch - 1 # do not movescaler = amp.GradScaler(enabled=cuda)logger.info('Image sizes %g train, %g test\n''Using %g dataloader workers\nLogging results to %s\n''Starting training for %g epochs...' % (imgsz, imgsz_test, dataloader.num_workers, save_dir, epochs))torch.save(model, wdir / 'init.pt')for epoch in range(start_epoch, epochs): # epoch ------------------------------------------------------------------model.train()# Update image weights (optional)if opt.image_weights:# Generate indicesif rank in [-1, 0]:cw = model.class_weights.cpu().numpy() * (1 - maps) ** 2 # class weightsiw = labels_to_image_weights(dataset.labels, nc=nc, class_weights=cw) # image weightsdataset.indices = random.choices(range(dataset.n), weights=iw, k=dataset.n) # rand weighted idx# Broadcast if DDPif rank != -1:indices = (torch.tensor(dataset.indices) if rank == 0 else torch.zeros(dataset.n)).int()dist.broadcast(indices, 0)if rank != 0:dataset.indices = indices.cpu().numpy()# Update mosaic border# b = int(random.uniform(0.25 * imgsz, 0.75 * imgsz + gs) // gs * gs)# dataset.mosaic_border = [b - imgsz, -b] # height, width bordersmloss = torch.zeros(4, device=device) # mean lossesif rank != -1:dataloader.sampler.set_epoch(epoch)pbar = enumerate(dataloader)logger.info(('\n' + '%10s' * 8) % ('Epoch', 'gpu_mem', 'box', 'obj', 'cls', 'total', 'targets', 'img_size'))if rank in [-1, 0]:pbar = tqdm(pbar, total=nb) # progress baroptimizer.zero_grad()for i, (imgs, targets, paths, _) in pbar: # batch -------------------------------------------------------------ni = i + nb * epoch # number integrated batches (since train start)imgs = imgs.to(device, non_blocking=True).float() / 255.0 # uint8 to float32, 0-255 to 0.0-1.0# Warmupif ni <= nw:xi = [0, nw] # x interp# model.gr = np.interp(ni, xi, [0.0, 1.0]) # iou loss ratio (obj_loss = 1.0 or iou)accumulate = max(1, np.interp(ni, xi, [1, nbs / total_batch_size]).round())for j, x in enumerate(optimizer.param_groups):# bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0x['lr'] = np.interp(ni, xi, [hyp['warmup_bias_lr'] if j == 2 else 0.0, x['initial_lr'] * lf(epoch)])if 'momentum' in x:x['momentum'] = np.interp(ni, xi, [hyp['warmup_momentum'], hyp['momentum']])# Multi-scaleif opt.multi_scale:sz = random.randrange(imgsz * 0.5, imgsz * 1.5 + gs) // gs * gs # sizesf = sz / max(imgs.shape[2:]) # scale factorif sf != 1:ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to gs-multiple)imgs = F.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)# Forwardwith amp.autocast(enabled=cuda):pred = model(imgs) # forwardloss, loss_items = compute_loss(pred, targets.to(device), model) # loss scaled by batch_sizeif rank != -1:loss *= opt.world_size # gradient averaged between devices in DDP mode# Backwardscaler.scale(loss).backward()# Optimizeif ni % accumulate == 0:scaler.step(optimizer) # optimizer.stepscaler.update()optimizer.zero_grad()if ema:ema.update(model)# Printif rank in [-1, 0]:mloss = (mloss * i + loss_items) / (i + 1) # update mean lossesmem = '%.3gG' % (torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0) # (GB)s = ('%10s' * 2 + '%10.4g' * 6) % ('%g/%g' % (epoch, epochs - 1), mem, *mloss, targets.shape[0], imgs.shape[-1])pbar.set_description(s)# Plotif plots and ni < 3:f = save_dir / f'train_batch{ni}.jpg' # filenameplot_images(images=imgs, targets=targets, paths=paths, fname=f)# if tb_writer:# tb_writer.add_image(f, result, dataformats='HWC', global_step=epoch)# tb_writer.add_graph(model, imgs) # add model to tensorboardelif plots and ni == 3 and wandb:wandb.log({"Mosaics": [wandb.Image(str(x), caption=x.name) for x in save_dir.glob('train*.jpg')]})# end batch ------------------------------------------------------------------------------------------------# end epoch ----------------------------------------------------------------------------------------------------# Schedulerlr = [x['lr'] for x in optimizer.param_groups] # for tensorboardscheduler.step()# DDP process 0 or single-GPUif rank in [-1, 0]:# mAPif ema:ema.update_attr(model)final_epoch = epoch + 1 == epochsif not opt.notest or final_epoch: # Calculate mAPif epoch >= 3:results, maps, times = test.test(opt.data,batch_size=batch_size*2,imgsz=imgsz_test,model=ema.ema.module if hasattr(ema.ema, 'module') else ema.ema,single_cls=opt.single_cls,dataloader=testloader,save_dir=save_dir,plots=plots and final_epoch,log_imgs=opt.log_imgs if wandb else 0)# Writewith open(results_file, 'a') as f:f.write(s + '%10.4g' * 7 % results + '\n') # P, R, mAP@.5, mAP@.5-.95, val_loss(box, obj, cls)if len(opt.name) and opt.bucket:os.system('gsutil cp %s gs://%s/results/results%s.txt' % (results_file, opt.bucket, opt.name))# Logtags = ['train/box_loss', 'train/obj_loss', 'train/cls_loss', # train loss'metrics/precision', 'metrics/recall', 'metrics/mAP_0.5', 'metrics/mAP_0.5:0.95','val/box_loss', 'val/obj_loss', 'val/cls_loss', # val loss'x/lr0', 'x/lr1', 'x/lr2'] # paramsfor x, tag in zip(list(mloss[:-1]) + list(results) + lr, tags):if tb_writer:tb_writer.add_scalar(tag, x, epoch) # tensorboardif wandb:wandb.log({tag: x}) # W&B# Update best mAPfi = fitness(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]fi_p = fitness_p(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]fi_r = fitness_r(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]fi_ap50 = fitness_ap50(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]fi_ap = fitness_ap(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]if (fi_p > 0.0) or (fi_r > 0.0):fi_f = fitness_f(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]else:fi_f = 0.0if fi > best_fitness:best_fitness = fiif fi_p > best_fitness_p:best_fitness_p = fi_pif fi_r > best_fitness_r:best_fitness_r = fi_rif fi_ap50 > best_fitness_ap50:best_fitness_ap50 = fi_ap50if fi_ap > best_fitness_ap:best_fitness_ap = fi_apif fi_f > best_fitness_f:best_fitness_f = fi_f# Save modelsave = (not opt.nosave) or (final_epoch and not opt.evolve)if save:with open(results_file, 'r') as f: # create checkpointckpt = {'epoch': epoch,'best_fitness': best_fitness,'best_fitness_p': best_fitness_p,'best_fitness_r': best_fitness_r,'best_fitness_ap50': best_fitness_ap50,'best_fitness_ap': best_fitness_ap,'best_fitness_f': best_fitness_f,'training_results': f.read(),'model': ema.ema.module.state_dict() if hasattr(ema, 'module') else ema.ema.state_dict(),'optimizer': None if final_epoch else optimizer.state_dict(),'wandb_id': wandb_run.id if wandb else None}# Save last, best and deletetorch.save(ckpt, last)if best_fitness == fi:torch.save(ckpt, best)if (best_fitness == fi) and (epoch >= 200):torch.save(ckpt, wdir / 'best_{:03d}.pt'.format(epoch))if best_fitness == fi:torch.save(ckpt, wdir / 'best_overall.pt')if best_fitness_p == fi_p:torch.save(ckpt, wdir / 'best_p.pt')if best_fitness_r == fi_r:torch.save(ckpt, wdir / 'best_r.pt')if best_fitness_ap50 == fi_ap50:torch.save(ckpt, wdir / 'best_ap50.pt')if best_fitness_ap == fi_ap:torch.save(ckpt, wdir / 'best_ap.pt')if best_fitness_f == fi_f:torch.save(ckpt, wdir / 'best_f.pt')if epoch == 0:torch.save(ckpt, wdir / 'epoch_{:03d}.pt'.format(epoch))if ((epoch+1) % 25) == 0:torch.save(ckpt, wdir / 'epoch_{:03d}.pt'.format(epoch))if epoch >= (epochs-5):torch.save(ckpt, wdir / 'last_{:03d}.pt'.format(epoch))elif epoch >= 420: torch.save(ckpt, wdir / 'last_{:03d}.pt'.format(epoch))del ckpt# end epoch ----------------------------------------------------------------------------------------------------# end trainingif rank in [-1, 0]:# Strip optimizersn = opt.name if opt.name.isnumeric() else ''fresults, flast, fbest = save_dir / f'results{n}.txt', wdir / f'last{n}.pt', wdir / f'best{n}.pt'for f1, f2 in zip([wdir / 'last.pt', wdir / 'best.pt', results_file], [flast, fbest, fresults]):if f1.exists():os.rename(f1, f2) # renameif str(f2).endswith('.pt'): # is *.ptstrip_optimizer(f2) # strip optimizeros.system('gsutil cp %s gs://%s/weights' % (f2, opt.bucket)) if opt.bucket else None # upload# Finishif plots:plot_results(save_dir=save_dir) # save as results.pngif wandb:wandb.log({"Results": [wandb.Image(str(save_dir / x), caption=x) for x in['results.png', 'precision-recall_curve.png']]})logger.info('%g epochs completed in %.3f hours.\n' % (epoch - start_epoch + 1, (time.time() - t0) / 3600))else:dist.destroy_process_group()wandb.run.finish() if wandb and wandb.run else Nonetorch.cuda.empty_cache()return resultsif __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('--weights', type=str, default='weights/yolov4.weights', help='initial weights path')parser.add_argument('--cfg', type=str, default='cfg/yolov4.cfg', help='model.yaml path')parser.add_argument('--data', type=str, default='data/self.yaml', help='data.yaml path')parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path')parser.add_argument('--epochs', type=int, default=100)parser.add_argument('--batch-size', type=int, default=8, help='total batch size for all GPUs')parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')parser.add_argument('--rect', action='store_true', help='rectangular training')parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')parser.add_argument('--notest', action='store_true', help='only test final epoch')parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset')parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')parser.add_argument('--log-imgs', type=int, default=16, help='number of images for W&B logging, max 100')parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')parser.add_argument('--project', default='runs/train', help='save to project/name')parser.add_argument('--name', default='exp', help='save to project/name')parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')opt = parser.parse_args()# Set DDP variablesopt.total_batch_size = opt.batch_sizeopt.world_size = int(os.environ['WORLD_SIZE']) if 'WORLD_SIZE' in os.environ else 1opt.global_rank = int(os.environ['RANK']) if 'RANK' in os.environ else -1set_logging(opt.global_rank)if opt.global_rank in [-1, 0]:check_git_status()# Resumeif opt.resume: # resume an interrupted runckpt = opt.resume if isinstance(opt.resume, str) else get_latest_run() # specified or most recent pathassert os.path.isfile(ckpt), 'ERROR: --resume checkpoint does not exist'with open(Path(ckpt).parent.parent / 'opt.yaml') as f:opt = argparse.Namespace(**yaml.load(f, Loader=yaml.FullLoader)) # replaceopt.cfg, opt.weights, opt.resume = '', ckpt, Truelogger.info('Resuming training from %s' % ckpt)else:# opt.hyp = opt.hyp or ('hyp.finetune.yaml' if opt.weights else 'hyp.scratch.yaml')opt.data, opt.cfg, opt.hyp = check_file(opt.data), check_file(opt.cfg), check_file(opt.hyp) # check filesassert len(opt.cfg) or len(opt.weights), 'either --cfg or --weights must be specified'opt.img_size.extend([opt.img_size[-1]] * (2 - len(opt.img_size))) # extend to 2 sizes (train, test)opt.name = 'evolve' if opt.evolve else opt.nameopt.save_dir = increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok | opt.evolve) # increment run# DDP modedevice = select_device(opt.device, batch_size=opt.batch_size)if opt.local_rank != -1:assert torch.cuda.device_count() > opt.local_ranktorch.cuda.set_device(opt.local_rank)device = torch.device('cuda', opt.local_rank)dist.init_process_group(backend='nccl', init_method='env://') # distributed backendassert opt.batch_size % opt.world_size == 0, '--batch-size must be multiple of CUDA device count'opt.batch_size = opt.total_batch_size // opt.world_size# Hyperparameterswith open(opt.hyp) as f:hyp = yaml.load(f, Loader=yaml.FullLoader) # load hypsif 'box' not in hyp:warn('Compatibility: %s missing "box" which was renamed from "giou" in %s' %(opt.hyp, 'https://github.com/ultralytics/yolov5/pull/1120'))hyp['box'] = hyp.pop('giou')# Trainlogger.info(opt)if not opt.evolve:tb_writer = None # init loggersif opt.global_rank in [-1, 0]:logger.info(f'Start Tensorboard with "tensorboard --logdir {opt.project}", view at http://localhost:6006/')tb_writer = SummaryWriter(opt.save_dir) # Tensorboardtrain(hyp, opt, device, tb_writer, wandb)# Evolve hyperparameters (optional)else:# Hyperparameter evolution metadata (mutation scale 0-1, lower_limit, upper_limit)meta = {'lr0': (1, 1e-5, 1e-1), # initial learning rate (SGD=1E-2, Adam=1E-3)'lrf': (1, 0.01, 1.0), # final OneCycleLR learning rate (lr0 * lrf)'momentum': (0.3, 0.6, 0.98), # SGD momentum/Adam beta1'weight_decay': (1, 0.0, 0.001), # optimizer weight decay'warmup_epochs': (1, 0.0, 5.0), # warmup epochs (fractions ok)'warmup_momentum': (1, 0.0, 0.95), # warmup initial momentum'warmup_bias_lr': (1, 0.0, 0.2), # warmup initial bias lr'box': (1, 0.02, 0.2), # box loss gain'cls': (1, 0.2, 4.0), # cls loss gain'cls_pw': (1, 0.5, 2.0), # cls BCELoss positive_weight'obj': (1, 0.2, 4.0), # obj loss gain (scale with pixels)'obj_pw': (1, 0.5, 2.0), # obj BCELoss positive_weight'iou_t': (0, 0.1, 0.7), # IoU training threshold'anchor_t': (1, 2.0, 8.0), # anchor-multiple threshold'anchors': (2, 2.0, 10.0), # anchors per output grid (0 to ignore)'fl_gamma': (0, 0.0, 2.0), # focal loss gamma (efficientDet default gamma=1.5)'hsv_h': (1, 0.0, 0.1), # image HSV-Hue augmentation (fraction)'hsv_s': (1, 0.0, 0.9), # image HSV-Saturation augmentation (fraction)'hsv_v': (1, 0.0, 0.9), # image HSV-Value augmentation (fraction)'degrees': (1, 0.0, 45.0), # image rotation (+/- deg)'translate': (1, 0.0, 0.9), # image translation (+/- fraction)'scale': (1, 0.0, 0.9), # image scale (+/- gain)'shear': (1, 0.0, 10.0), # image shear (+/- deg)'perspective': (0, 0.0, 0.001), # image perspective (+/- fraction), range 0-0.001'flipud': (1, 0.0, 1.0), # image flip up-down (probability)'fliplr': (0, 0.0, 1.0), # image flip left-right (probability)'mosaic': (1, 0.0, 1.0), # image mixup (probability)'mixup': (1, 0.0, 1.0)} # image mixup (probability)assert opt.local_rank == -1, 'DDP mode not implemented for --evolve'opt.notest, opt.nosave = True, True # only test/save final epoch# ei = [isinstance(x, (int, float)) for x in hyp.values()] # evolvable indicesyaml_file = Path(opt.save_dir) / 'hyp_evolved.yaml' # save best result hereif opt.bucket:os.system('gsutil cp gs://%s/evolve.txt .' % opt.bucket) # download evolve.txt if existsfor _ in range(300): # generations to evolveif Path('evolve.txt').exists(): # if evolve.txt exists: select best hyps and mutate# Select parent(s)parent = 'single' # parent selection method: 'single' or 'weighted'x = np.loadtxt('evolve.txt', ndmin=2)n = min(5, len(x)) # number of previous results to considerx = x[np.argsort(-fitness(x))][:n] # top n mutationsw = fitness(x) - fitness(x).min() # weightsif parent == 'single' or len(x) == 1:# x = x[random.randint(0, n - 1)] # random selectionx = x[random.choices(range(n), weights=w)[0]] # weighted selectionelif parent == 'weighted':x = (x * w.reshape(n, 1)).sum(0) / w.sum() # weighted combination# Mutatemp, s = 0.8, 0.2 # mutation probability, sigmanpr = np.randomnpr.seed(int(time.time()))g = np.array([x[0] for x in meta.values()]) # gains 0-1ng = len(meta)v = np.ones(ng)while all(v == 1): # mutate until a change occurs (prevent duplicates)v = (g * (npr.random(ng) < mp) * npr.randn(ng) * npr.random() * s + 1).clip(0.3, 3.0)for i, k in enumerate(hyp.keys()): # plt.hist(v.ravel(), 300)hyp[k] = float(x[i + 7] * v[i]) # mutate# Constrain to limitsfor k, v in meta.items():hyp[k] = max(hyp[k], v[1]) # lower limithyp[k] = min(hyp[k], v[2]) # upper limithyp[k] = round(hyp[k], 5) # significant digits# Train mutationresults = train(hyp.copy(), opt, device, wandb=wandb)# Write mutation resultsprint_mutation(hyp.copy(), results, yaml_file, opt.bucket)# Plot resultsplot_evolution(yaml_file)print(f'Hyperparameter evolution complete. Best results saved as: {yaml_file}\n'f'Command to train a new model with these hyperparameters: $ python train.py --hyp {yaml_file}')本文是基于yolov4.cfg进行模型的开发训练的,终端执行即可启动训练,日志输出如下所示:
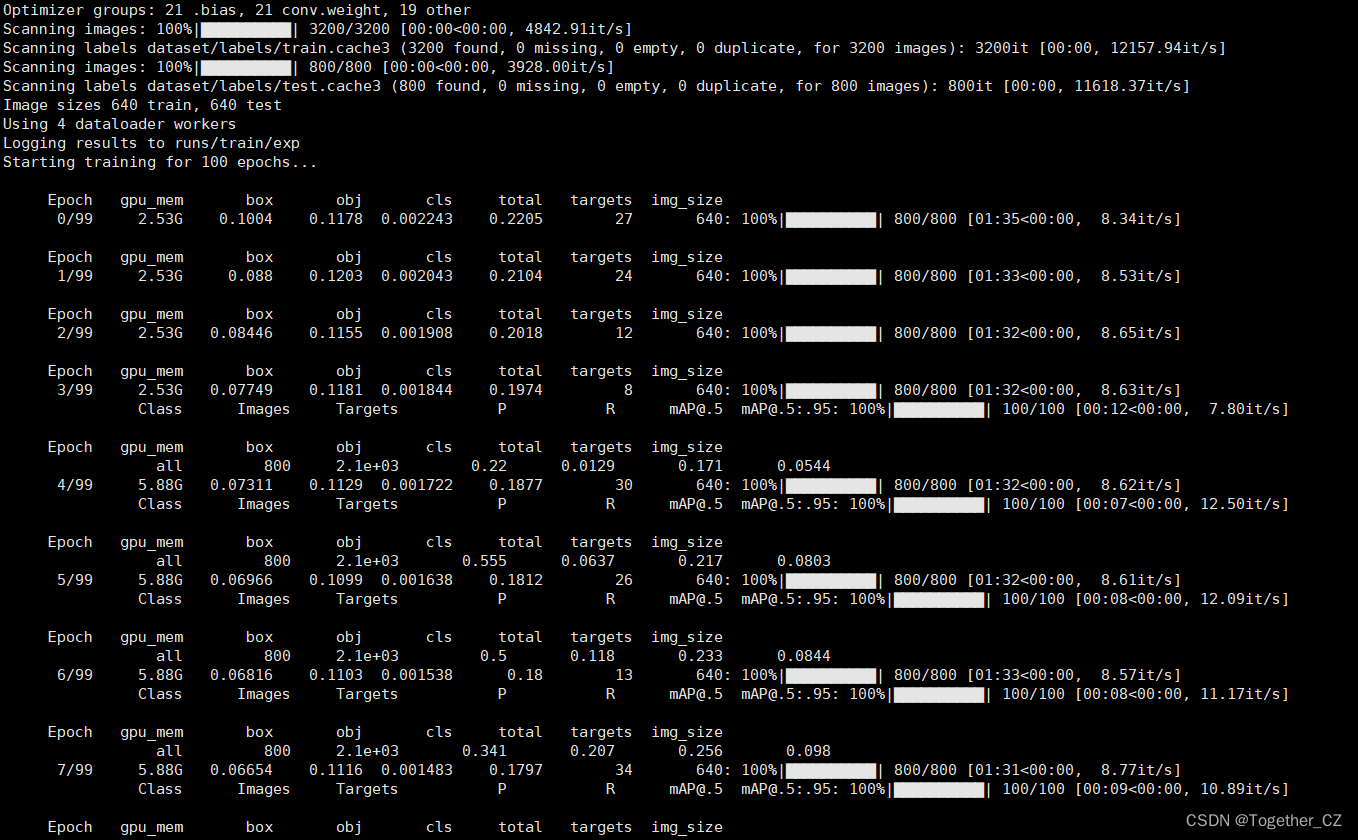
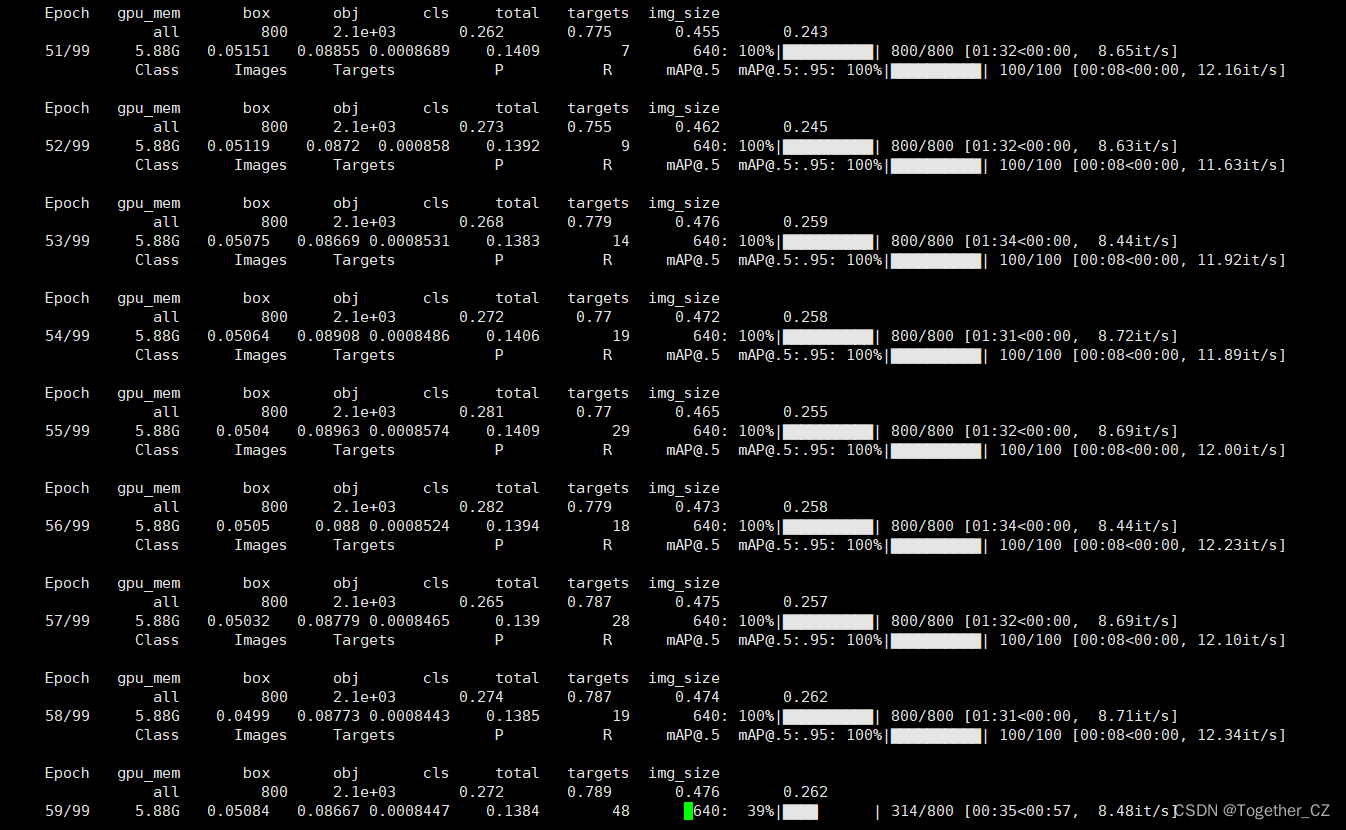

接下来看下结果详情。
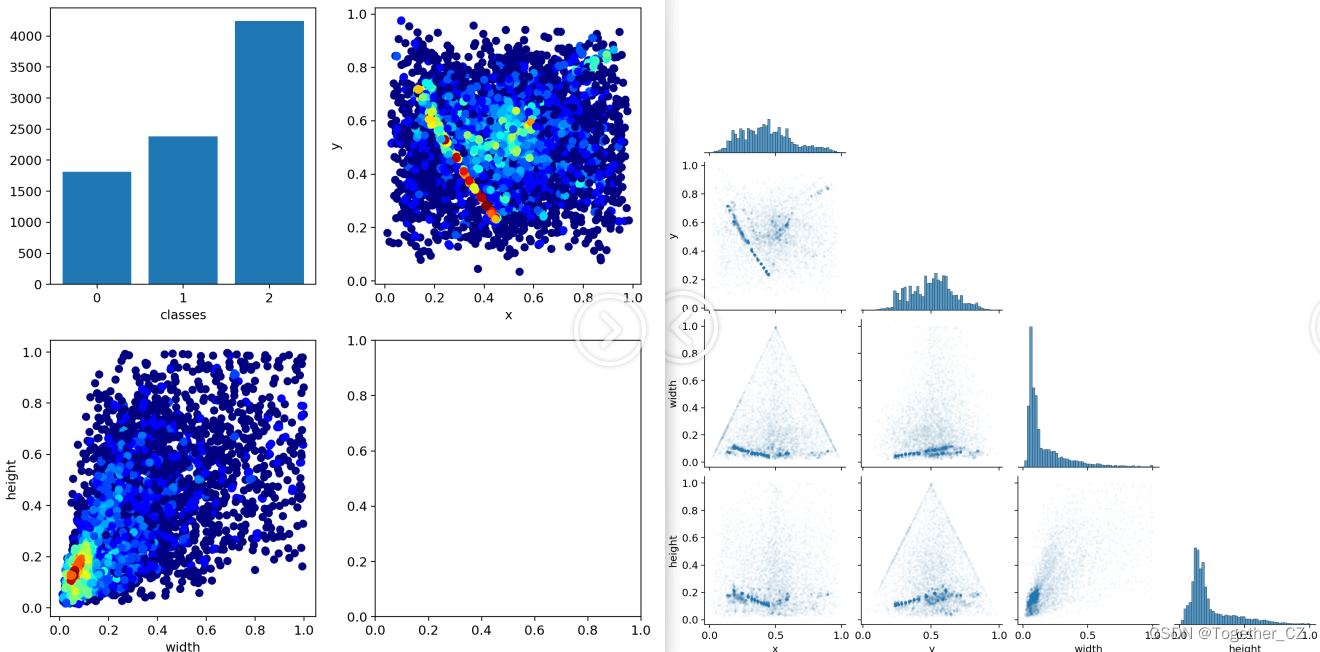
【数据分布可视化】
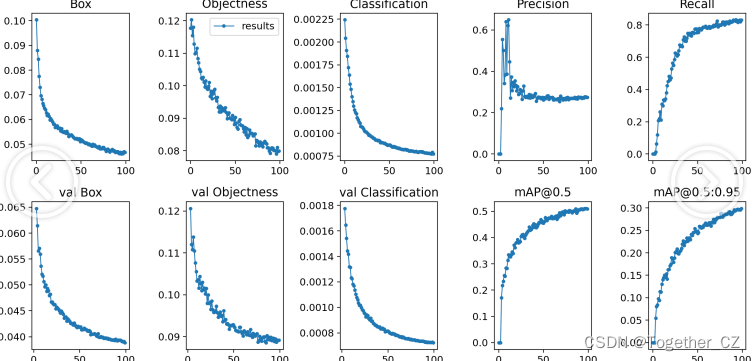
【训练可视化】
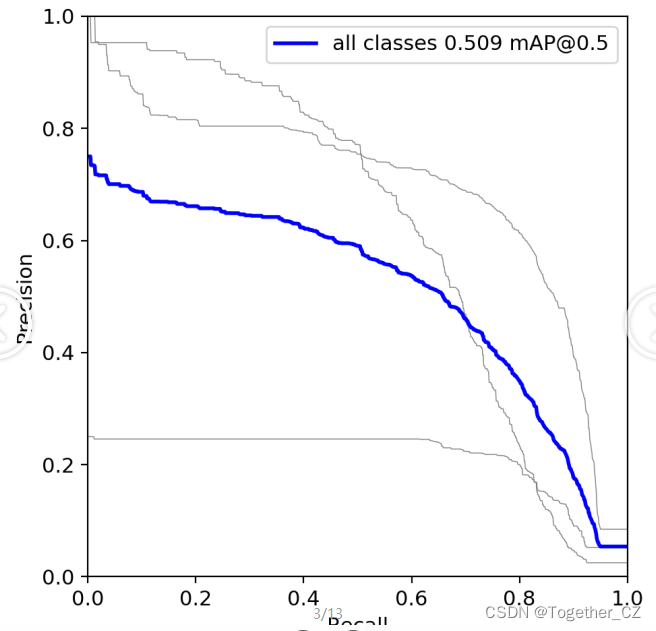
【PR曲线】
精确率-召回率曲线(Precision-Recall Curve)是一种用于评估二分类模型性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)和召回率(Recall)之间的关系图来帮助我们了解模型在不同阈值下的表现。精确率是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。
【Batch实例】

后续可以通过接入社区监控摄像头实时视频流数据来进行智能计算分析,对于实时检测到的目标对象进行综合处理后结合业务规则形成事件推送给相关的处理人员就可以实现垃圾堆放垃圾桶溢出的及时处理了,感兴趣的话也都可以自行动手尝试下!
这篇关于助力打造清洁环境,基于YOLOv4开发构建公共场景下垃圾堆放垃圾桶溢出检测识别系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







