本文主要是介绍【大数据HA】HAProxy实现thrift协议HMS服务的高可用-附Chatgpt协助截图,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景
之前安装了HMS(Hive metastore service),独立于hive运行,安装部署过程见我下面列出的另一篇文章,需要为它建立HA高可用功能。防止在访问时出现单点故障问题。
【大数据】Docker部署HMS(Hive Metastore Service)并使用Trino访问Minio-CSDN博客
本来想到的是Nginx,但是在进一步分析,HMS发布的是thrift协议,一种tcp协议,而nginx支持的是http和https协议,所以无法匹配。另外找解决方案,在chatgpt的帮助下,发现可以使用HAProxy来做thrift协议的HA,所以选择了HAProxy。
一:环境介绍
之前发布了HMS服务,现在需要支持HA,那么需要启动两个HMS(使用docker启动的),并且两个HMS指向同一个mysql数据库,这样在两个HMS之间可以实现HA,所以重新做了一个HMS的服务,在两台虚机上
虚机一:wuxdihadl03b,IP 10.40.8.44,部署了HMS和mysql服务

虚机二:wuxdihadl04b,IP 10.40.8.45,部署了HMS服务

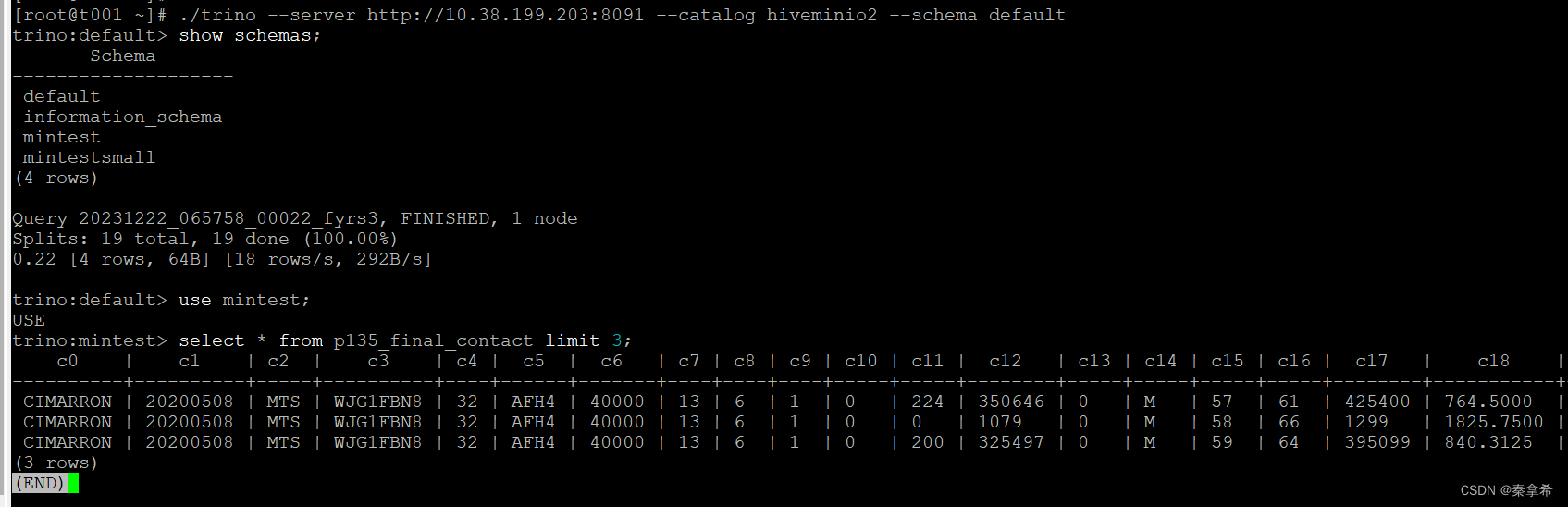
使用trino访问了两个HMS实例,均能访问HMS及后端的minio数据
trino的catalog配置
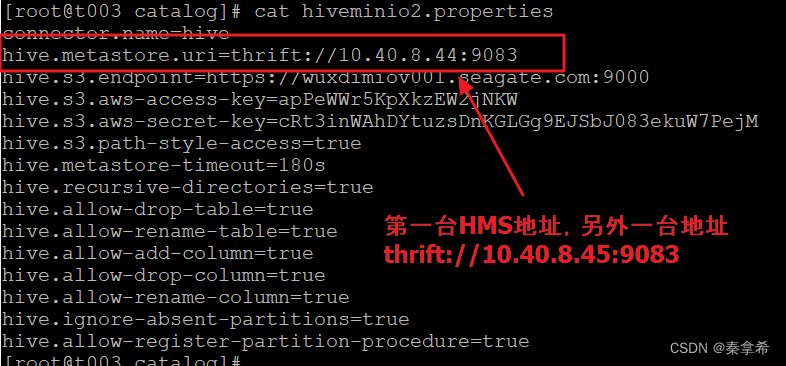
trino访问数据
二:实现目标
环境已经准备好了,现在就是要使用HAProxy来代理到后端的两个HMS服务,并且在一台HMS下线后,仍然能使用另一台HMS对外服务。
三:安装HAProxy
yum install haproxy -y四:配置HAProxy
找到配置文件/etc/haproxy/haproxy.cfg,修改frontend,backend,listen语段,frontend代表前端服务,客户端访问入口,backend代理后端服务,listen配置监控界面。因为HMS使用的是thrift协议,因此在设置时,需要设置mode为tcp,否则默认为http
frontend设置
frontend mainbind *:5000 #对外暴露的访问地址及端口mode tcp #设置协议为tcp,thrift归属于tcp协议acl url_static path_beg -i /static /images /javascript /stylesheetsacl url_static path_end -i .jpg .gif .png .css .jsuse_backend static if url_staticdefault_backend hms #后端服务的名称
backend设置
backend hmsbalance roundrobin #负载均衡策略mode tcp #协议模式,thrift归属tcpserver app1 10.40.8.44:9083 check #HMS服务1server app2 10.40.8.45:9083 check #HMS服务2
listen设置
listen statsbind :9000 # 页面访问端口stats enable # 启用统计报告stats uri /haproxy_stats # 设置统计页面的 URL 路径stats realm Haproxy\ Statistics # 设置认证窗口标题stats auth admin:haproxy # 设置访问统计页面的用户名和密码stats admin if TRUE # 开启管理模式,允许通过界面进行某些操作以上配置完成,下面贴出我这个文件haproxy.cfg的完整配置
#---------------------------------------------------------------------
# Example configuration for a possible web application. See the
# full configuration options online.
#
# https://www.haproxy.org/download/1.8/doc/configuration.txt
#
#---------------------------------------------------------------------#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global# to have these messages end up in /var/log/haproxy.log you will# need to:## 1) configure syslog to accept network log events. This is done# by adding the '-r' option to the SYSLOGD_OPTIONS in# /etc/sysconfig/syslog## 2) configure local2 events to go to the /var/log/haproxy.log# file. A line like the following can be added to# /etc/sysconfig/syslog## local2.* /var/log/haproxy.log#log 127.0.0.1 local2chroot /var/lib/haproxypidfile /var/run/haproxy.pidmaxconn 4000user haproxygroup haproxydaemon# turn on stats unix socketstats socket /var/lib/haproxy/stats# utilize system-wide crypto-policiesssl-default-bind-ciphers PROFILE=SYSTEMssl-default-server-ciphers PROFILE=SYSTEM#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaultsmode httplog globaloption httplogoption dontlognulloption http-server-closeoption forwardfor except 127.0.0.0/8option redispatchretries 3timeout http-request 10stimeout queue 1mtimeout connect 10stimeout client 1mtimeout server 1mtimeout http-keep-alive 10stimeout check 10smaxconn 3000listen statsbind :9000stats enablestats uri /haproxy_statsstats realm Haproxy\ Statisticsstats auth admin:haproxystats admin if TRUE#---------------------------------------------------------------------
# main frontend which proxys to the backends
#---------------------------------------------------------------------
frontend mainbind *:5000mode tcpacl url_static path_beg -i /static /images /javascript /stylesheetsacl url_static path_end -i .jpg .gif .png .css .jsuse_backend static if url_staticdefault_backend hms#---------------------------------------------------------------------
# static backend for serving up images, stylesheets and such
#---------------------------------------------------------------------
backend staticbalance roundrobinserver static 127.0.0.1:4331 check#---------------------------------------------------------------------
# round robin balancing between the various backends
#---------------------------------------------------------------------
backend hmsbalance roundrobinmode tcpserver app1 10.40.8.44:9083 checkserver app2 10.40.8.45:9083 check
重启HAProxy服务
systemctl reload haproxy五:测试HAProxy功能
首先修改trino的metastore地址为thrift://10.40.8.44:5000
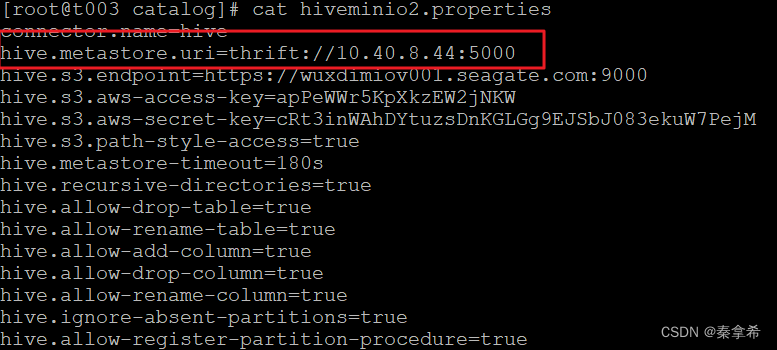
docker停止两个HMS服务


查看HAProxy页面服务http://10.40.8.44:9000/haproxy_stats,两个服务是下线的
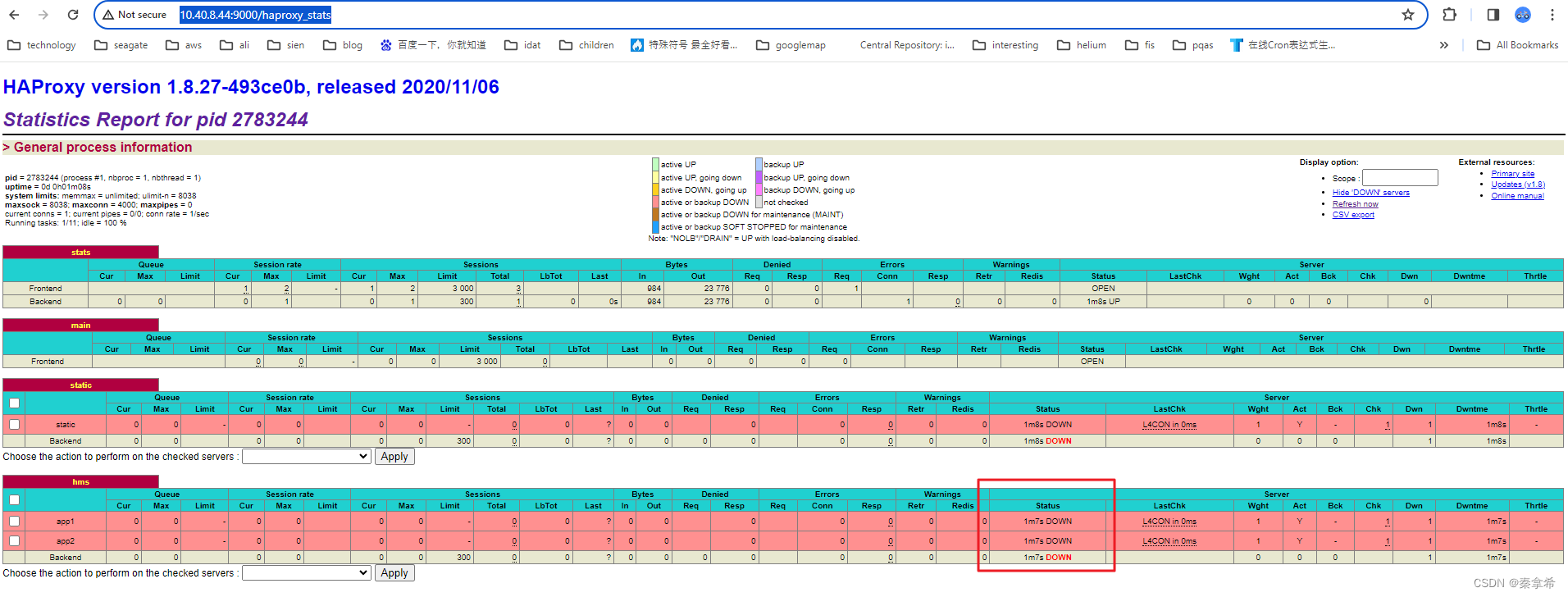
trino访问,metastore地址10.40.8.44:5000,无法访问

启动一个服务

查看页面,一个HMS已经启动
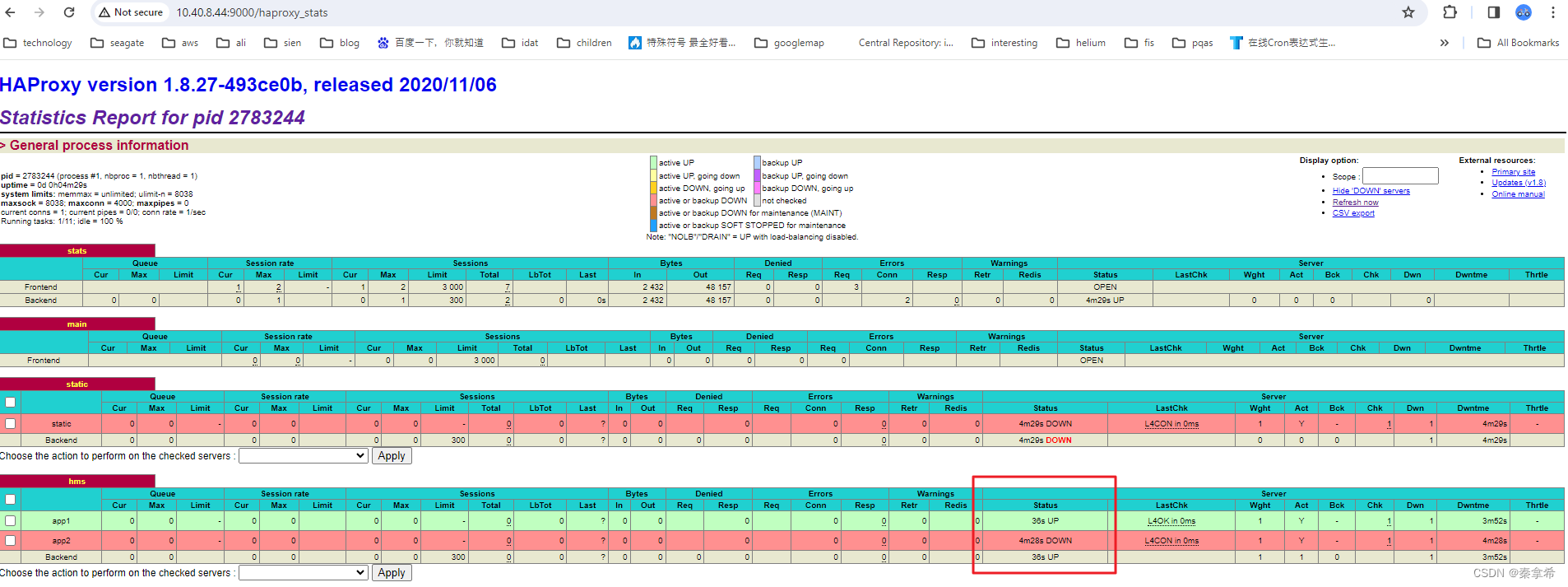
trino访问
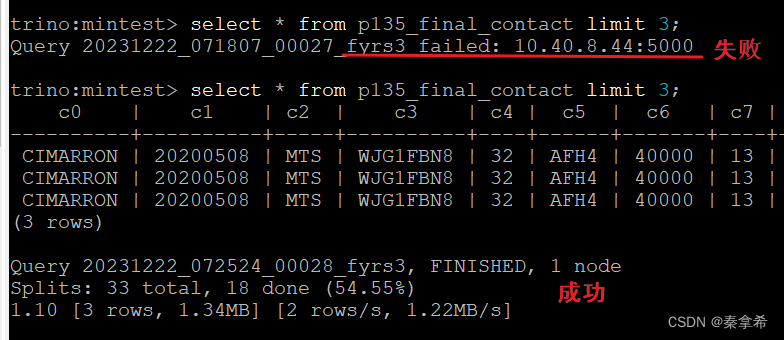
再启动另一个HMS,仍然能访问
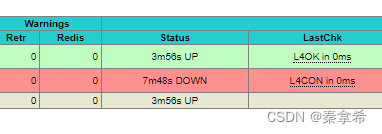
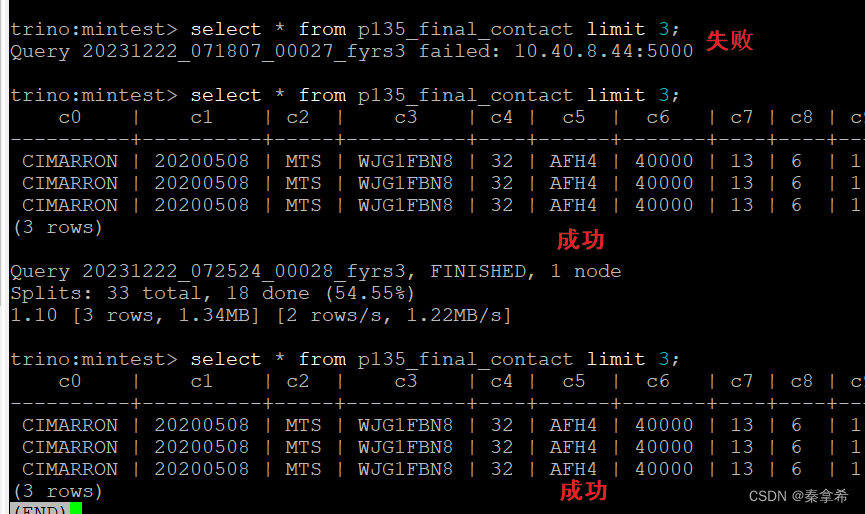
反复多情况测试均成功,本次测试结束!
六:附注:列一下chatgpt给与的帮助截图
只能说chatgpt提升工作效率100%以上,某度,某元还是扎根好好做吧。注:我用的是chatgpt4
问:HMS的HA怎么做

问:Nginx可以做HMS服务的HA吗

我指出了问题点,gpt马上就纠正了错误,肯定了我的观点

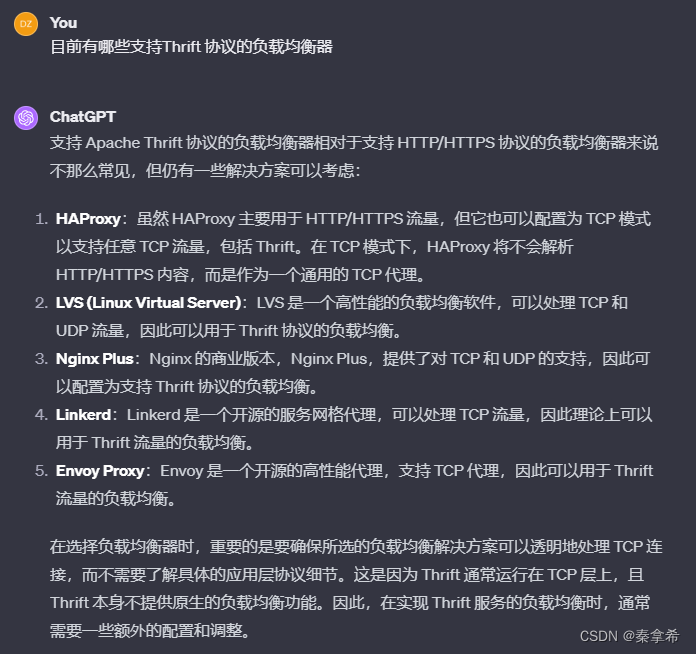
问:目前有哪些支持Thrift 协议的负载均衡器
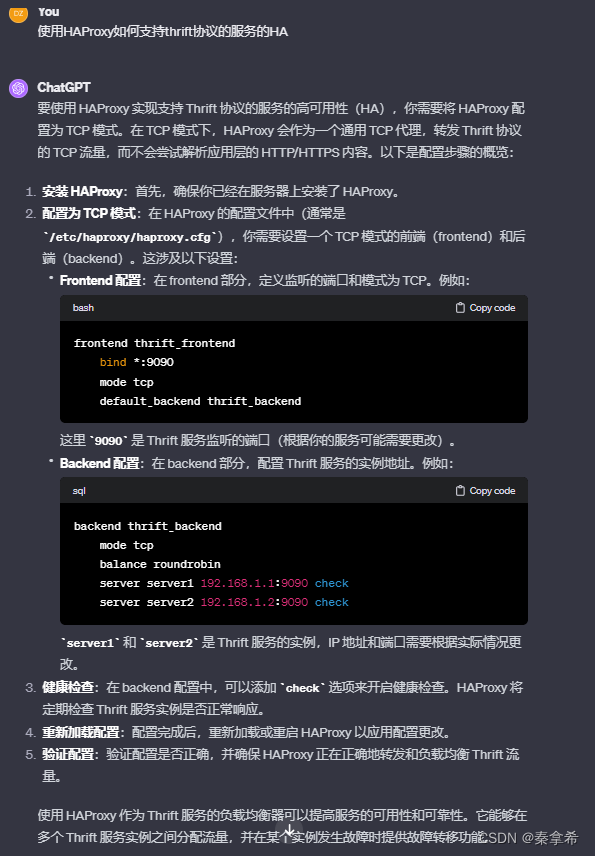
问:使用HAProxy如何支持thrift协议的服务的HA
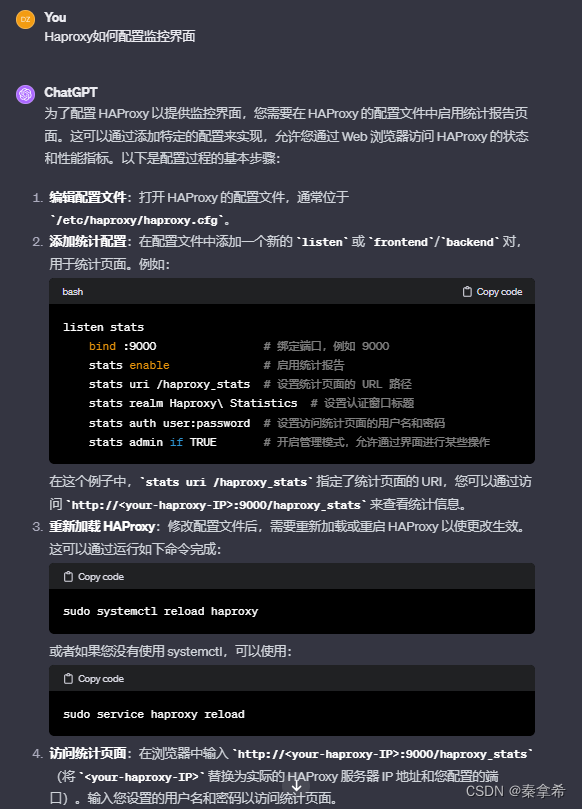
问:Haproxy配置监控界面
这篇关于【大数据HA】HAProxy实现thrift协议HMS服务的高可用-附Chatgpt协助截图的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






