本文主要是介绍论文阅读<MULTISCALE DOMAIN ADAPTIVE YOLO FOR CROSS-DOMAIN OBJECT DETECTION>,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文链接:https://arxiv.org/pdf/2106.01483v2.pdf![]() https://arxiv.org/pdf/2106.01483v2.pdf
https://arxiv.org/pdf/2106.01483v2.pdf
代码链接:GitHub - Mazin-Hnewa/MS-DAYOLO: Multiscale Domain Adaptive YOLO for Cross-Domain Object DetectionMultiscale Domain Adaptive YOLO for Cross-Domain Object Detection - GitHub - Mazin-Hnewa/MS-DAYOLO: Multiscale Domain Adaptive YOLO for Cross-Domain Object Detection![]() https://github.com/Mazin-Hnewa/MS-DAYOLO
https://github.com/Mazin-Hnewa/MS-DAYOLO
目录
Abstract
Method
2.1 Domain Adaptive Network for YOLO
2.2 DAN(Domain Adaptive Network)
Abstract
域适应领域在解决许多应用中遇到的域迁移问题方面发挥了重要作用。这个问题是由于用于训练的源数据分布与实际测试场景中使用的目标数据分布之间的差异造成的。本文提出了一种新的多尺度域自适应YOLO ( MultiScale Domain Adaptive YOLO,MS-DAYOLO )框架,该框架在最近引入的YOLOv4目标检测器的不同尺度上使用多个域适应路径和相应的域分类器来生成域不变特征。我们使用流行的数据集来训练和测试我们提出的方法。我们的实验表明,在使用所提出的MSDAYOLO训练YOLOv4和在目标数据r上测试时,目标检测性能显著提高
Method
以YOLOv4作为backbone,它包括23个残差块和5个下采样层去提取特征。这里关注下图中列出的backbone的后三个模块。目的是让域自适应用于这三块特征,使得它们对不同尺度的域变化更具鲁棒性,从而在基于域自适应的训练过程中收敛到域不变性。
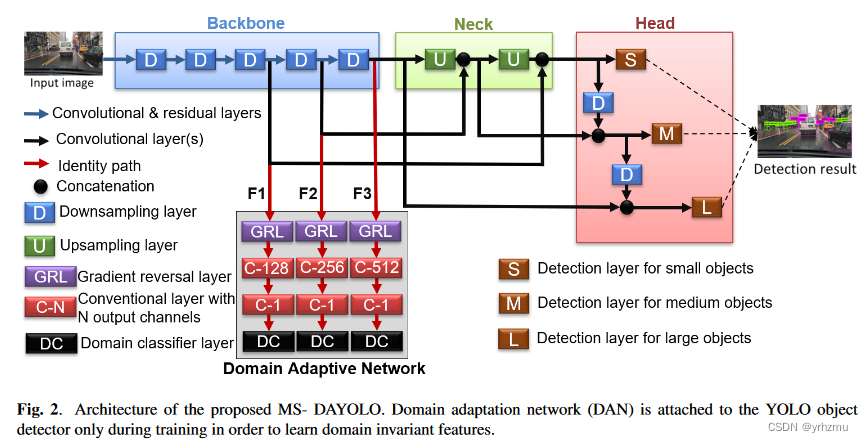
2.1 Domain Adaptive Network for YOLO
YOLOv4和设计的DAN模块以端到端的方式进行训练,测试时仅使用YOLOv4原先的结构,以保证在实时检测中的应用。
DAN的输入是backbone的三个特征提取块,主要用公式1中的损失进行约束,是第i张训练图像的GT的lable,
是源域,
是目标域,
是第i张训练图预测出的概率。通过最大化这个损失,backbone去学习域不变特征,这有助于提高目标域的检测性能。
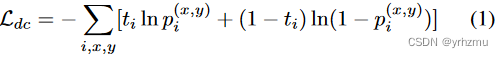
在Backbone和DAN中使用GRL(Gradient Reversal Layer)连接,GRL是一种双向算子,用于实现两种不同的优化目标。在前馈方向,GRL充当标识算子。这导致在进行局部反向传播时,标准的目标是最小化DAN的分类误差,而对于向骨干网络的反向传播,GRL成为一个负标量( λ )。这导致了二分类误差的最大化;并且这种最大化促进了backbone生成领域不变特征。总损失用公式2计算,λ用于控制DAN对backbone的影响。
![]()
2.2 DAN(Domain Adaptive Network)
为了解决梯度消失问题,分别对三个尺度进行域适应,换句话说,只对最终尺度( F3 )进行域适应并不会因为梯度消失问题而对之前的尺度( F1和F2)产生显著影响。因此,我们采用多尺度策略,通过3个相应的GRL将主干的3个特征F1、F2和F3连接到DAN,如图2所示。对于每个尺度,GRL后有两个卷积层,第一个卷积层减少一半的特征通道,第二个卷积层预测域类概率。最后,使用一个域分类器层来计算领域分类损失。
Experiment
3.1 Setup
训练的数据包括两部分,一部分来自有标注的源域,另一部分来自没有标注的目标域。每个batch有64张图像,其中32张来自源域,32张来自目标域。使用Cityscape,Foggy Cityscaoes,BDD100K和INIT进行实验。
3.2 Result and Discussion
Clear to Foggy
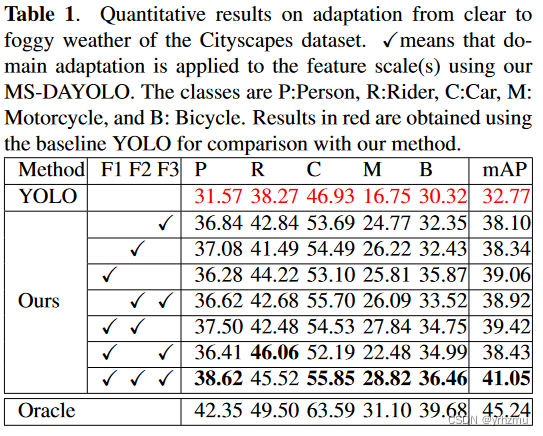
用Cityscape和Foggy Cityscape的训练集作为全部训练集,Foggy Cityscape的验证集去进行评估。和YOLOV4相比,性能得到非常大的提升。
Sunny to Rainy
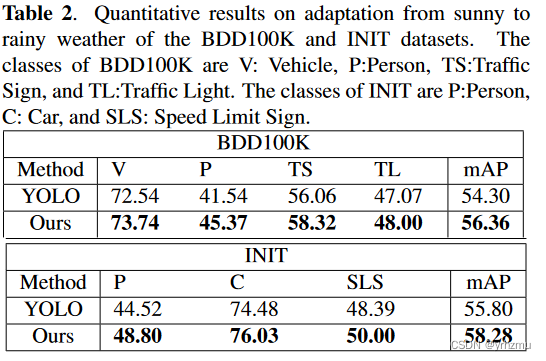
还使用BDD100K [ 23 ]和INIT [ 24 ]数据集讨论了我们提出的方法从晴天到阴雨天气的适应能力。我们为源数据提取"晴朗天气"有标签图像,"阴雨天气"无标签图像来表示目标数据。与之前一样,原始的YOLOv4仅使用源数据(即带标记的晴天图像)进行训练。提出的MS - DAYOLO使用源数据和目标数据(即有标记的晴天图像和无标记的雨天图像)进行训练。此外,从雨天数据中提取有标签的图像进行测试和评估。结果汇总于表2。我们的方法在两个数据集上都比原始的YOLO取得了明显的性能提升。
这篇关于论文阅读<MULTISCALE DOMAIN ADAPTIVE YOLO FOR CROSS-DOMAIN OBJECT DETECTION>的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







