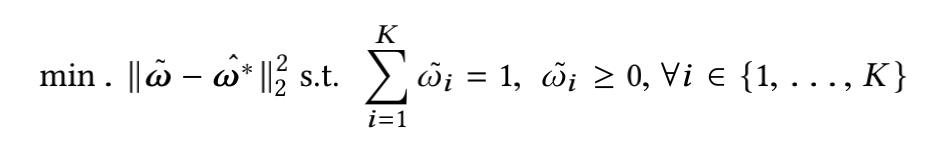本文主要是介绍[Focal Loss] Retinanet,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、解决的问题
一阶段检测网络的性能瓶颈:dense detector场景下,前景-背景训练样本极度不平衡
2、Focal loss
![]()
1)通过增加![]() 项,让网络更关注难的、容易误分的样本;减少大量easy negative的权重,使得他们对loss的贡献更小
项,让网络更关注难的、容易误分的样本;减少大量easy negative的权重,使得他们对loss的贡献更小
2)γ越大,容易样本的weight越小(γ = 0时,focal loss和CE loss相同);本文设置γ = 2

3)α是稀有类别的权重,γ↑,α↓;本文设置α = 0.25
4)形式不唯一,其他表达也可以获得相似的结果
5)和sigmoid相结合可以有更好的数值稳定性
6)α-balanced CE loss只平衡了正/负样本的重要性,而不是简单/困难样本
![]()
3、Retinanet

1)结构
a)backbone:FPN(只用ResNet的AP很低) ,
和
通过stride=2的conv 3 x 3得到,而不是FPN的max pool
b)分类subnetwork
- 预测每个空间位置的A个anchor的K类概率(最后一个conv层有KA个卷积核)
- 不同pyramid level共享参数
- sigmoid activation
- 与回归subnetwork不共享参数
- 最后一个conv层初始化时,![]() ,从而使网络一开始预测的概率值为π,而不是0;否则一开始负样本占主导,概率倾向于0,正样本的loss值会非常大(对于正样本,loss是-log0)。本文π = 0.01,结果对该值的设置不敏感
,从而使网络一开始预测的概率值为π,而不是0;否则一开始负样本占主导,概率倾向于0,正样本的loss值会非常大(对于正样本,loss是-log0)。本文π = 0.01,结果对该值的设置不敏感
c)回归subnetwork
- 预测每个空间位置的A个anchor和最近的GT框的offset(最后一个conv层有4A个卷积核)
- class-agnostic,但equally effective
- 与分类subnetwork不共享参数
- inference时,用0.05阈值过滤anchor,取top-1k解码bbox回归结果
2)anchor
- 正样本:IoU >= 0.5;负样本:IoU < 0.4
- 每个anchor至多匹配到一个GT框
- 对所有anchor计算loss,用正anchor数目normalize
这篇关于[Focal Loss] Retinanet的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


![[论文笔记]Circle Loss: A Unified Perspective of Pair Similarity Optimization](/front/images/it_default.jpg)