本文主要是介绍阿里云林立翔:基于阿里云 GPU 的 AIGC 小规模训练优化方案,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
云布道师
本篇文章围绕生成式 AI 技术栈、生成式 AI 微调训练和性能分析、ECS GPU 实例为生成式 AI 提供算力保障、应用场景案例等相关话题展开。
生成式 AI 技术栈介绍
1、生成式 AI 爆发的历程
在 2022 年的下半年,业界迎来了生成式 AI 的全面爆发,尤其是以 ChatGPT 为代表的大语言模型和以 Stable Diffusion 为代表的图片生成类模型。举个例子,某幼儿园老师要求家长写一篇 1500 字的关于家庭教育法的心得体会,ChatGPT 可以胜任这份工作;各种 logo 也可以通过 Stable Diffusion 生成式模型来生成,根据提示词生成各类图片。
(1)软件算法部分
生成式 AI 的爆发彻底突破了过往对 AI 应用的想象空间,但从软件和算法角度,生成式 AI 的全面爆发并非一蹴而就,它是近三四十年所有研发人员、算法工程师以及科研人员的努力,共同促成了当今生成式 AI 的爆发。
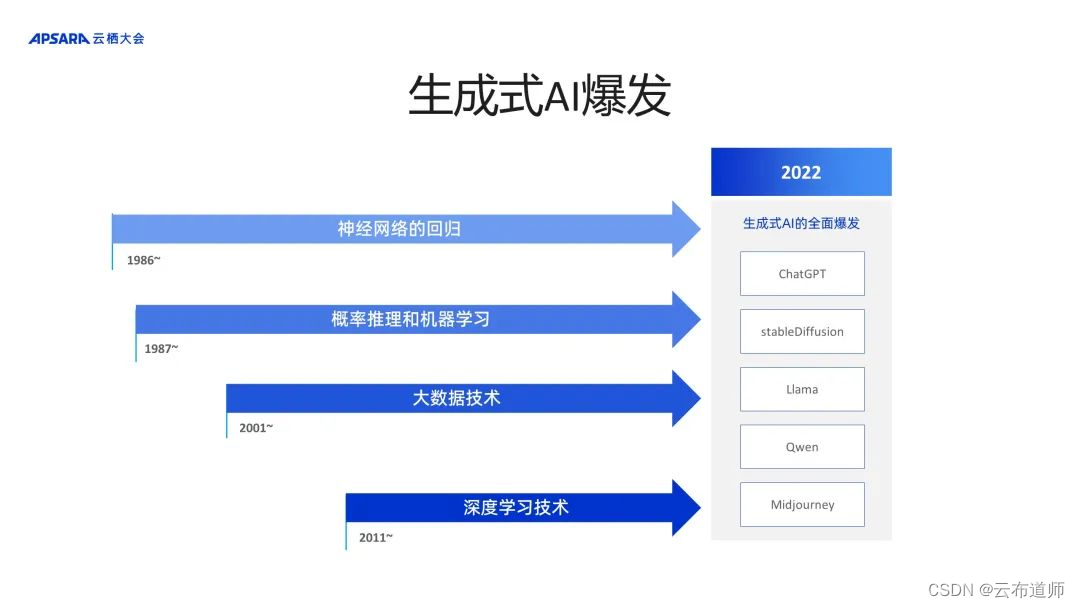
1986 年,上世纪六七十年代被抛弃的神经网络重新回归主流研究领域。1987 年,概率推理和机器学习算法引入,将不确定性的数学建模以及随机梯度下降的学习算法引入到人工智能的主流算法研究领域。
21 世纪初,随着互联网的爆炸式发展,大数据技术被引入到各个领域,包括生产、分析以及人工智能。近十年,深度学习技术尤其火热,即通过多层感知网络堆叠来提升模型泛化精度。这些算法基础设施的不断演进,促成了生成式AI爆发。
(2)硬件部分
硬件部分也是促成当前生存式AI爆发的重要基础。如人工智能领域,我们通常喜欢和人类大脑进行类比,人脑约有 1011 个神经元,神经元之间有 1010 个突触,相当于可以达到每秒钟 1017的算力,约为 0.1 EFLOPS。个人计算机目前还达不到人脑的算力,GPU 集群的计算能力已经超过了人类大脑的算力,先进的 GPU 计算集群已经可以达到 EFLOPS 的级别。因此,算力也是目前生成式 AI 的重要硬件保障。
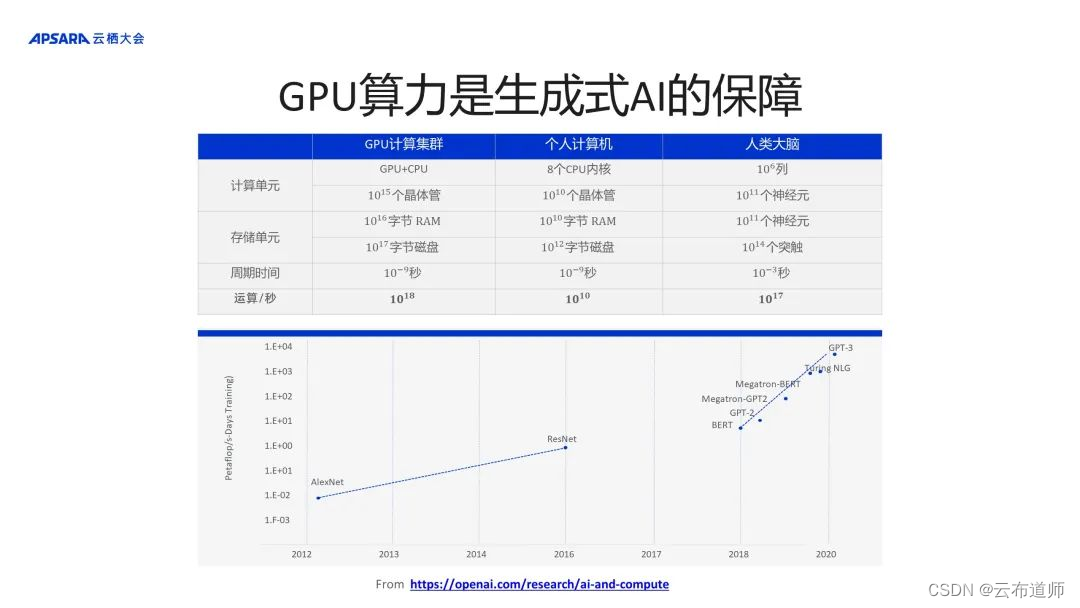
上图中展示了目前最典型的 GPU 3 模型的大致推算,纵坐标 Petaflop/s-Days 表示要在一天之内训练一个模型,算力需要达到的 Petaflop/s。GPT 3 的量级约为 10 的 4 次方的 Petaflop/s-Days,如果使用千卡的 A100 组成集群,大致需要一个月的时间训练完 GPT 3 的预训练模型。
2、生成式 AI 训练技术栈
总结来说,是由于模型结构的创新,尤其以 2017 年开始 Transformer 模型结构为代表;另外大数据带来了海量的数据集,还包括机器学习的梯度寻优算法结构,共同构成了 AI 训练算法和软件上的基础。另外,从 GPU 的云服务器到 GPU 的云服务集群,构成了 AI 训练的硬件基础。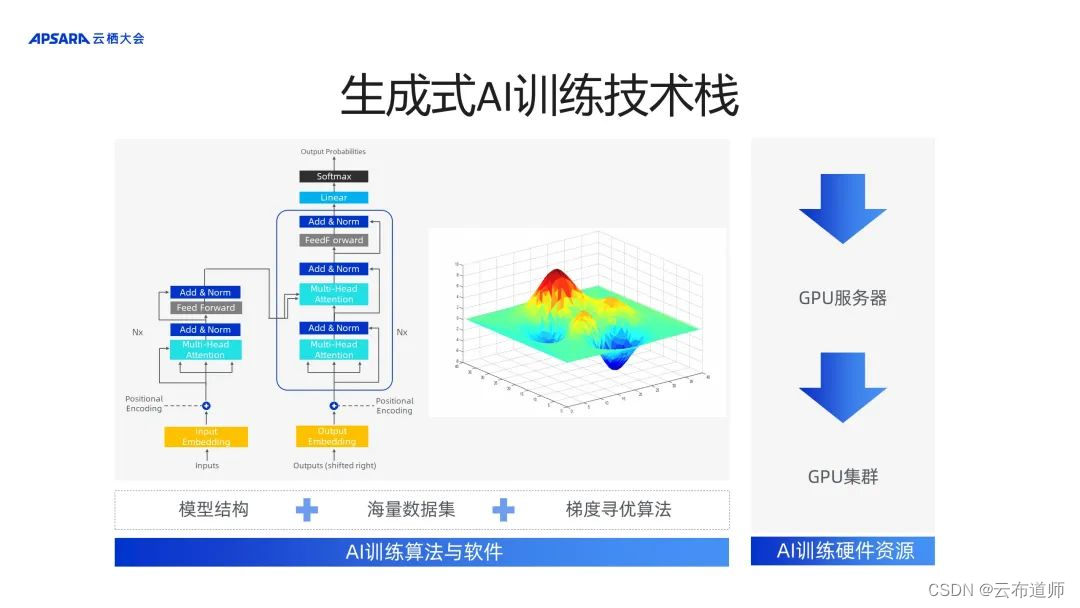
软件算法与硬件发展带来了当下生成式 AI 训练技术栈爆发,带来了通往 AGI 的曙光。
生成式 AI 微调训练和性能分析
第二部分,我将介绍目前在生成式 AI 的微调训练场景下的流程、使用场景以及基于 ECS GPU 云服务器,生存式 AI 微调训练场景的性能分析。
1、生成式 AI 从开发到部署的流程
大致可以分为三部分——预训练、微调和推理,如下图所示:
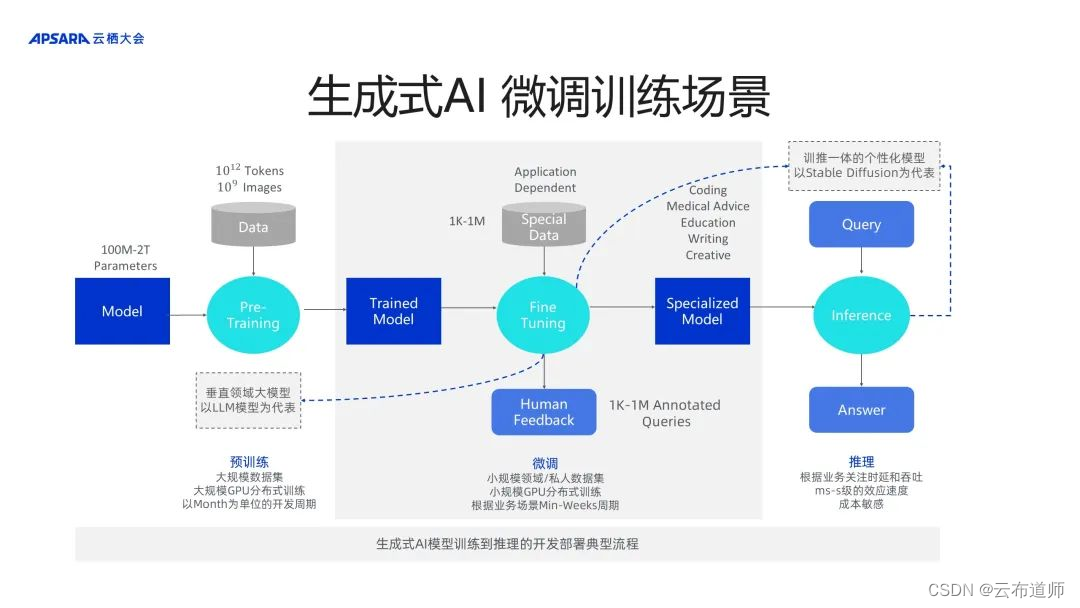
最左侧是 Pre-Training(预训练),生成通用模型,中间是 Fine Tuning(微调),生成特定领域的数据集,最终在部署时,进行 Inference 推理。
在 Pre-Training 阶段,最重要的特点是有海量的数据集以及大的参数量,因此该场景需要大规模算力进行分布式训练,通常以月为单位的开发周期和生产迭代的流程。
在 Fine Tuning 阶段,与 Pre-Training 略有区别,该场景下需要 Special Data,如垂直领域模型的客户专属的私域数据。此外,根据应用场景需求,有些场景可能需在要分钟级 Fine Tuning 出一个模型,有些场景可以以周为单位生产模型,进而把Pre-Training 模型变成 specialize 特定领域的模型,如 coding、media advise、education 等垂类的模型。
在 Inference 推理阶段,其特点更加明显,即用于部署,最关键是如何在符合特定的在线服务环境下做到时延和吞吐,以达到上线需求。
生成式 AI 微调训练场景中两类常见的模型,如上图所示。
第一类,如妙鸭相机 APP,它是基于 Diffusion 生成类模型提供针对客户定制化专属模型的一种训练方式,它是快速 Fine Tuning 与高效 Inference 兼顾的一种训推一体的生成式 AI 模型。
第二类,垂直领域的大模型,以大语言模型为代表,它根据特定场景以及对应的垂类领域的数据,基于基座模型 Fine Tuning 定制化的 LLM 模型。
2、生成式 AI 微调场景的 GPU 性能分析
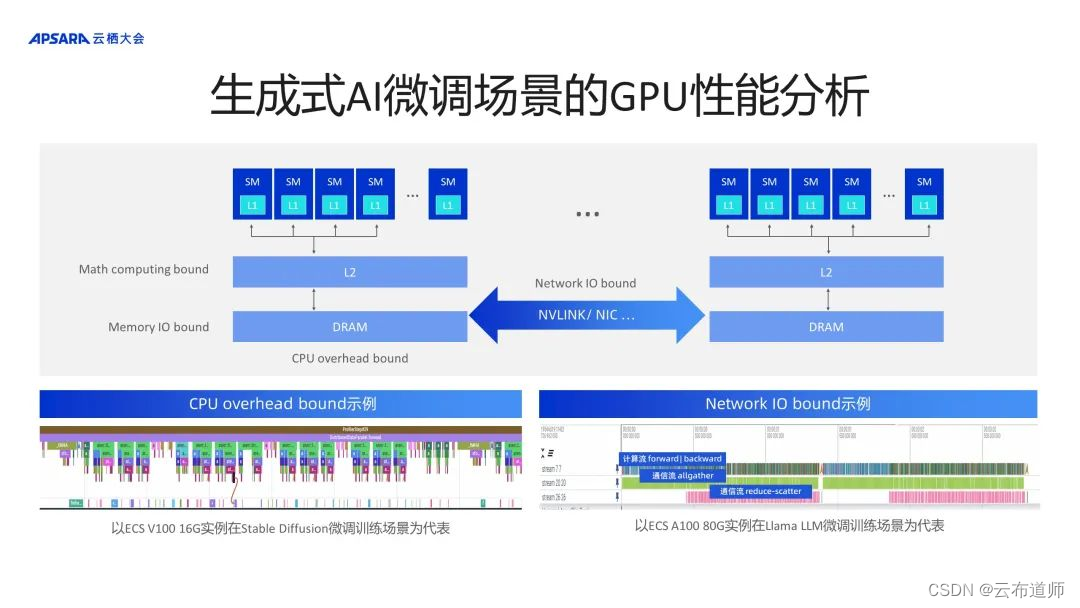
以上两类模型在 GPU 计算上存在瓶颈。GPU 的原理并不复杂,即一堆小的 Micro 的计算单元做 ALU 计算,和小块矩阵乘法。但模型或深度学习算法并不是简单地由矩阵乘组成,包括 transform layer 等对应的 activation 等,如何将堆叠的 layer 映射到算力资源,更好地发挥出算力的 efficiency 是我们需要解决的场景。
具体到生成式AI的微调场景,上图的最下方列了两张 Timeline 图,左下角是以 ECS V100 16G 实例在 Stable Diffusion 微调训练场景为代表,可以看到 GPU 计算逻辑时间序列有很多空白,说明 GPU 的算力没有被完全发挥出来,其最重要的瓶颈来自于 CPU 本身的 overhead 特别大,这是 v100 场景下在 Stable Diffusion 微调遇到的瓶颈。
右下角 ECS A100 80G 实例在 Llama LLM 微调训练场景为代表,最上面一层是在 GPU 上的计算执行逻辑,下面是密集的 all gather 通信流,又伴随着密集的 Reduce scatter 通信流,它是网络 IO 成为 bound 的计算 workload。
映射到算力资源,CPU overhead bound 和 Network IO bound 成为了 GPU 运算的瓶颈。
ECS GPU 实例为生成式 AI 提供算力保障
ECS GPU 云服务器通过软硬件结合的方式,为生成式 AI 的微调场景提供了充沛、高性能的算力保障。
1、ECS 异构计算为生成式 AI 提供澎湃算力
下面是阿里云异构计算产品大图。底座是 ECS 的神龙计算平台,之上提供了包括gn7e、gn7i 以及其他做计算加速实例的硬件资源组。在算力的基础之上,提供DeepGPU Toolkits,其目标在于衔接上层 AI 应用和底层硬件资源,进行软结合一体化的优化,提升 ECS GPU 云服务器与友商相比的差异化竞争力,服务于客户以达到高性能和高性价比的 AI 训练和推理效果。
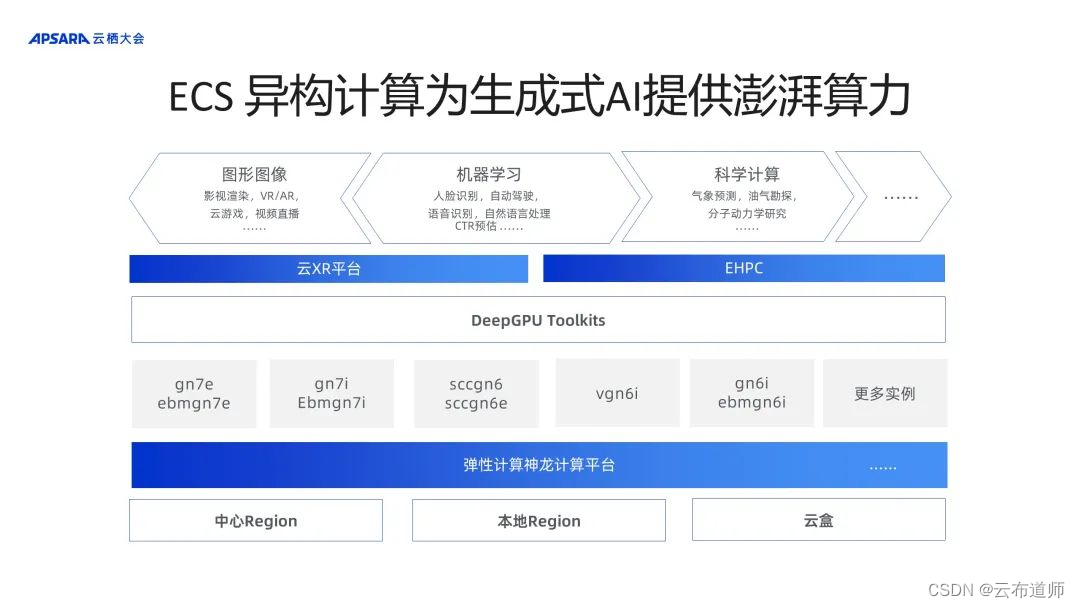
2、ECS 异构计算 DeepGPU 提升生成式 AI 效率
以下是 DeepGPU 的简图。
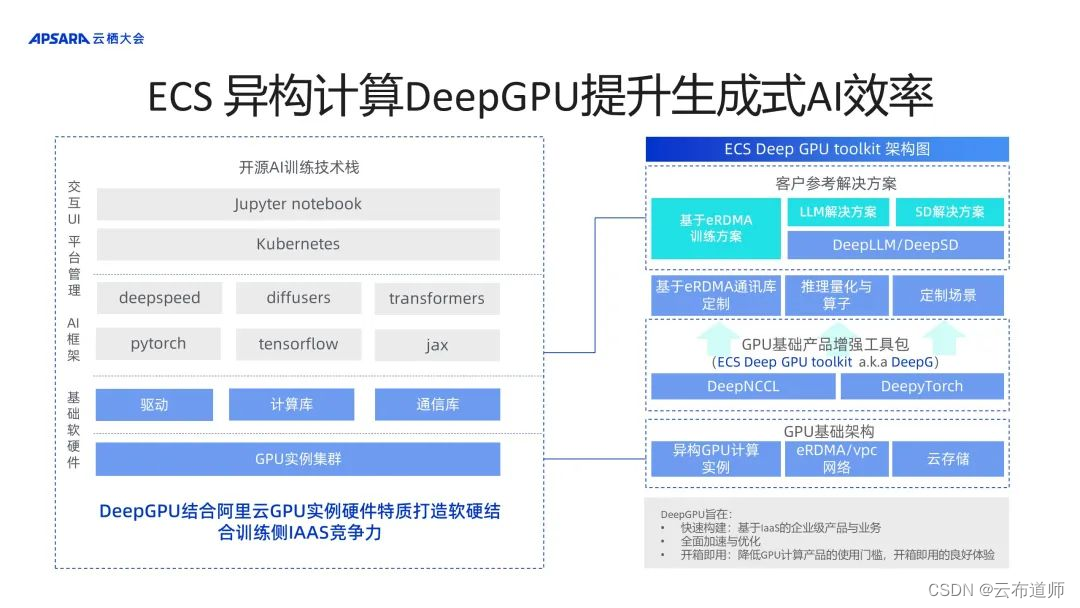
左侧是开发模型的训练技术栈,通常开发人员只关注两部分,第一,是否能提供足够的算力服务,可以通过开源的调度器以及开源的模型框架搭建模型算法的开发流程。DeepGPU 的工作则是在客户并不触及的部分,包括驱动级、计算库和通信库,整合包括 CIPU、ECS GPU 云服务器的能力提升在模型训练和推理的效果和能力。
右侧是 DeepGPU 的整体架构图,其底层是依托于 GPU 的基础架构,包括异构 GPU 计算实例、eRDMA/vpc 网络以及云存储,在基础产品增强工具包中提供包括基于 eRDMA 训练的客户参考解决方案,最终的目的是帮助客户在基于 ECS GPU 云服务器上,其模型的训练推理的性能可以达到最佳。
3、阿里云 CIPU + DeepGPU 提升分布式训练效率
简单介绍 DeepNCCL 如何通过阿里云特有的基础设施达到软硬结合的训练加速的效果。左侧图是 CIPU 的基础设施,它提供了 eRDMA Engine,可以达到大吞吐、低延时的网络通信的能力,叠加 DeepNCCL 软硬结合的性能优化,右图显示 allgather 的 NCCL test 性能数据,右侧是原生的数据,左侧是 DeepNCCL 加持的性能数据,DeepNCCL 实现了比原生数据提升 50%~100% 的 primitive 的 NCCL 集合通信的算子优化能力。

应用场景案例
这部分通过几个典型的场景介绍 ECS GPU 云服务器叠加 DeepGPU 在生成式 AI 的应用场景以及对应的性能加速效果。
1、ECS A10 DeepGPU Diffusion 微调训练案例
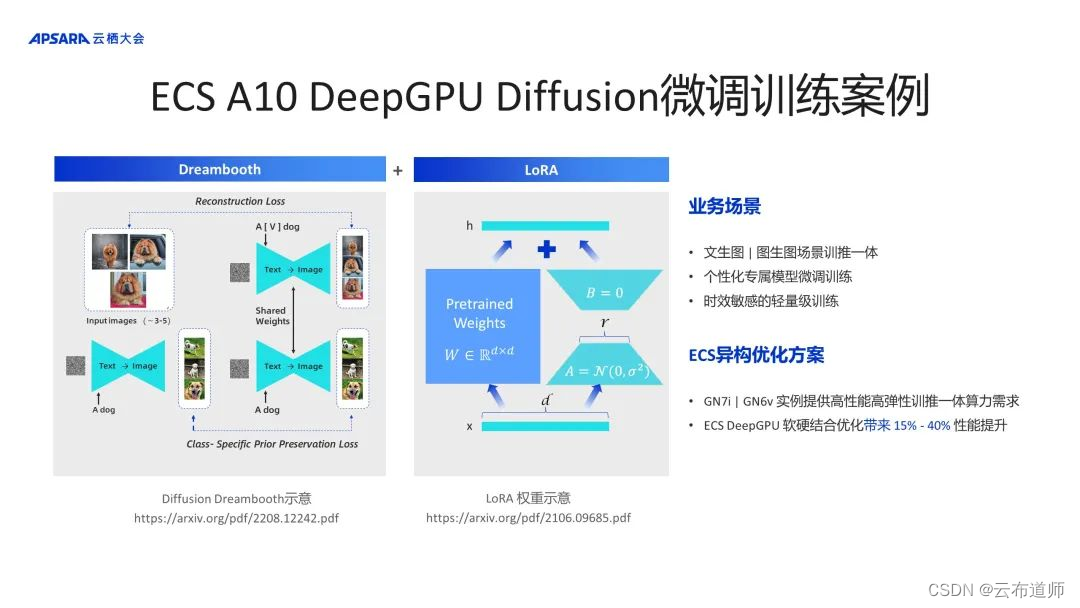
关于 DeepGPU Diffusion 微调的训练案例的性能加速方案,前面的内容中曾提及过该场景的目标,即训推一体。换言之,客户首次或二次进入都要快速生成模型,则其训练一定要快,也就是说其在模型上有一定的折中,如通过 LoRA 降低总计算量;其次,模型中需要有专属于每个客户自己的 feature,通常是在 Diffusion 中通过Dreambooth 或 controlnet 提供专属模型的优化能力。
通过算法上的加持可以形成用户专属模型,另外可以保证快速。再叠加 gn7e、gn7i 提供的高弹性算力保障,可以提升整个训推一体的算力需求,同时 DeepGPU 软硬结合可以额外带来 15%~40% 的性能提升。类似的案例已经在客户妙鸭大规模上线,通过快速地弹出大量的 A10、V100 实例以及 DeepGPU 的性能加持,帮助妙鸭快速应对高峰期用户推理和训练的请求。
2、ECS A100 DeepGPU LLM 微调训练案例
另一部分,在大语言模型的微调训练案例,其特点是模型参数量太大,在单机很难装载训练,因此模型参数需要 sharding 到不同的 GPU 卡和不同的机器上做训练算法的迭代,这会引入大量卡间通信,且是同步通信操作,因此多卡互联的能力是 LLM 在微调训练场景的瓶颈。

ECS GPU 云服务器提供包括 eRDMA 以及大带宽的算力和通信带宽保障,再叠加DeepGPU 的 DeepNCCL 加持,可以为大语言模型在多机多卡的微调场景带来10%~80% 的性能提升。这个案例也在许多客户场景上得到了实践。
以上就是本次分享的全部内容。
这篇关于阿里云林立翔:基于阿里云 GPU 的 AIGC 小规模训练优化方案的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





