本文主要是介绍CloudCanal x Debezium 打造实时数据流动新范式,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简述
Debezium 是一个开源的数据订阅工具,主要功能为捕获数据库变更事件发送到 Kafka。
CloudCanal 近期实现了从 Kafka 消费 Debezium 格式数据,将其 同步到 StarRocks、Doris、Elasticsearch、MongoDB、ClickHouse 等 12 种数据库和数仓,补全其数据到达能力。
本文将先简单介绍该项技术实现的背景,再通过 MySQL -> Kafka -> Starrocks 示例展示此功能。

为什么要消费 Debezium 格式数据
高流行度
Debezium 是一个高质量、被大量项目集成的开源项目,社区用户活跃,官方维护积极,修复 bug、增加新特性,不断更新版本。
作为 Kafka Connect 生态系统的一部分,Debezium 能够无缝与 Kafka 进行对接,为用户后端数据处理提供了强大的 实时数据准备 能力。
由此形成的高流行度,让每一个数据行业从业者不能忽视其影响力。
合理的消息结构
Schema(数据结构) 遵循 Kafka Connect 标准,提供了详细的字段信息。
"schema": {"type": "struct","fields": [{"type": "int32", "optional": false, "field": "id"},{"type": "string", "optional": false, "field": "name"},{"type": "int32", "optional": false, "field": "age"}],"optional": false, "name": "my_database.user.Value"
}
Payload(数据)包含实际的数据库变更数据,与 Schema 中定义的字段对应。
"payload": {"id": 123,"name": "John Doe","age": 30,"source": {...}
}
此外消息还携带了源端数据源全面的关联信息,包括库、表、时间戳、位点等信息。整体格式实用、简洁。
支持 Schema 演进
Debezium 不仅捕获数据库模式的当前状态,还能感知和记录每次模式变更细节。
当数据库表结构发生变化时(如添加、删除、修改字段等),Debezium 能够 实时捕获这些结构变更,确保变更事件的精准传递。
另外 Debezium 会为每个捕获的变更事件 记录包含当前和先前 Schema 的历史记录。
这意味着 可追溯任何时刻数据库 Schema,了解特定时间点表字段、数据类型等信息, 并且可精准还原数据库在某一时刻的结构,无需额外的查询或推测。
CDC 数据格式标准
Debezium 数据 Schema 基于 Kafka Connect 标准设计,这使 Debezium 产生的变更事件能够轻松地集成到各种 Kafka Connect 连接器中,实现了与 Kafka 生态系统的顺畅对接。
这个设计使得 Debezium 数据 Schema 有望成为 CDC(Change Data Capture) 领域标准,为实时数据流的流动提供了基础设施。
端到端的缺憾
Debezium 集如此众多的优点,但是其官方缺少消息到对端的能力(目前有在补充),这让一部分用户感觉束手无策,CloudCanal 支持消费 Debezium 数据即解决这个问题,为用户实时数据生态建设贡献绵薄之力。
支持 Debezium 的主流 CDC 技术比较
对于使用 Debezium 的用户来说,消费 Kafka 中的 Debezium 数据并将其写入其他数据源,有几种主流 CDC 技术可选,如下表。
| Kafka-Connect | Flink-CDC | CloudCanal | |
|---|---|---|---|
| 同步配置 | 配置文件 | 代码/配置(新版本) | 可视化 |
| 同步性能(延迟) | 优秀 | 优秀 | 优秀 |
| 社区支持 | 一般 | 积极 | 积极 |
| 大规模部署使用 | 一般 | 优秀 | 优秀 |
| 消息格式 | 符合其标准的 JSON、Avro… | Debezium JSON、Canal JSON、Maxwell JSON | Debezium JSON、Canal JSON、CloudCanal JSON 等 |
| 插件支持 | Oracle、MySQL、SqlServer… | Oracle、MySQL、SqlServer… | StarRocks、Doris、Elasticsearch 等 12 种 |
CloudCanal 支持 Debezium 做了那些事
CloudCanal 之前即实现了将数据库数据以 Debezium 格式写入目标端 Kafka 的能力,并在兼容性方面做了大量优化。
此次版本更新则支持从 Kafka 消费 Debezium 格式数据,并同步到对端数据库或数仓, 形成基于 Kafka 中转的端到端数据迁移同步能力,同时可平滑对接上/下游已使用其他工具且以 Debezium 数据格式载体的需求。
操作示例
Debezium 环境准备
- 相关资源一键部署 (Docker): debezium-test.tar.gz
- Kafka 集群 + Kafka UI
- Debezium
- MySQL (源端)
- Starrocks (目标端)
tar -xzvf debezium-test.tar.gz sh install.sh
创建 MySQL Source Connector
-
源端是 MySQL,通过下面的表进行创建。
CREATE DATABASE `inventory`;CREATE TABLE `inventory`.`customer` (`c_int` int NOT NULL,`c_bigint` bigint NOT NULL, `c_decimal` decimal(10,3) NOT NULL,`c_date` date NOT NULL,`c_datetime` datetime NOT NULL,`c_timestamp` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,`c_year` int NOT NULL,`c_varchar` varchar(10) NOT NULL,`c_text` text NOT NULL,PRIMARY KEY (`c_int`) ); -
通过 Debezium 的 Api 接口创建 Connector 订阅 MySQL 的变更事件。
curl -i -X POST http://127.0.0.1:7750/connectors \-H 'Content-Type: application/json' \-d '{"name": "connector-test-mx","config": {"connector.class": "io.debezium.connector.mysql.MySqlConnector","database.hostname": "112.124.38.87","database.port": "25000","database.user": "root","database.password": "123456","database.server.id": "1","database.server.name": "mx","database.include.list": "inventory","topic.prefix": "mx","table.include.list": "inventory.customer","snapshot.mode": "never","database.history.kafka.bootstrap.servers": "112.124.38.87:19092,112.124.38.87:29092,112.124.38.87:39092","schema.history.internal.kafka.bootstrap.servers": "112.124.38.87:19092,112.124.38.87:29092,112.124.38.87:39092","schema.history.internal.kafka.topic": "mx.schemahistory.customer","database.history.kafka.topic": "mx.mx_history_schema","include.schema.changes": "false" }}' -
创建后,查看 Connetor 的状态。
curl -s http://127.0.0.1:7750/connectors/connector-test-mx/status
CloudCanal 订阅 Kafka 的数据变更
准备 CloudCanal
- 下载安装 CloudCanal 私有部署版本
添加数据源
- 数据源管理 -> 添加数据源, 添加 Kafka、Starrocks、MySQL
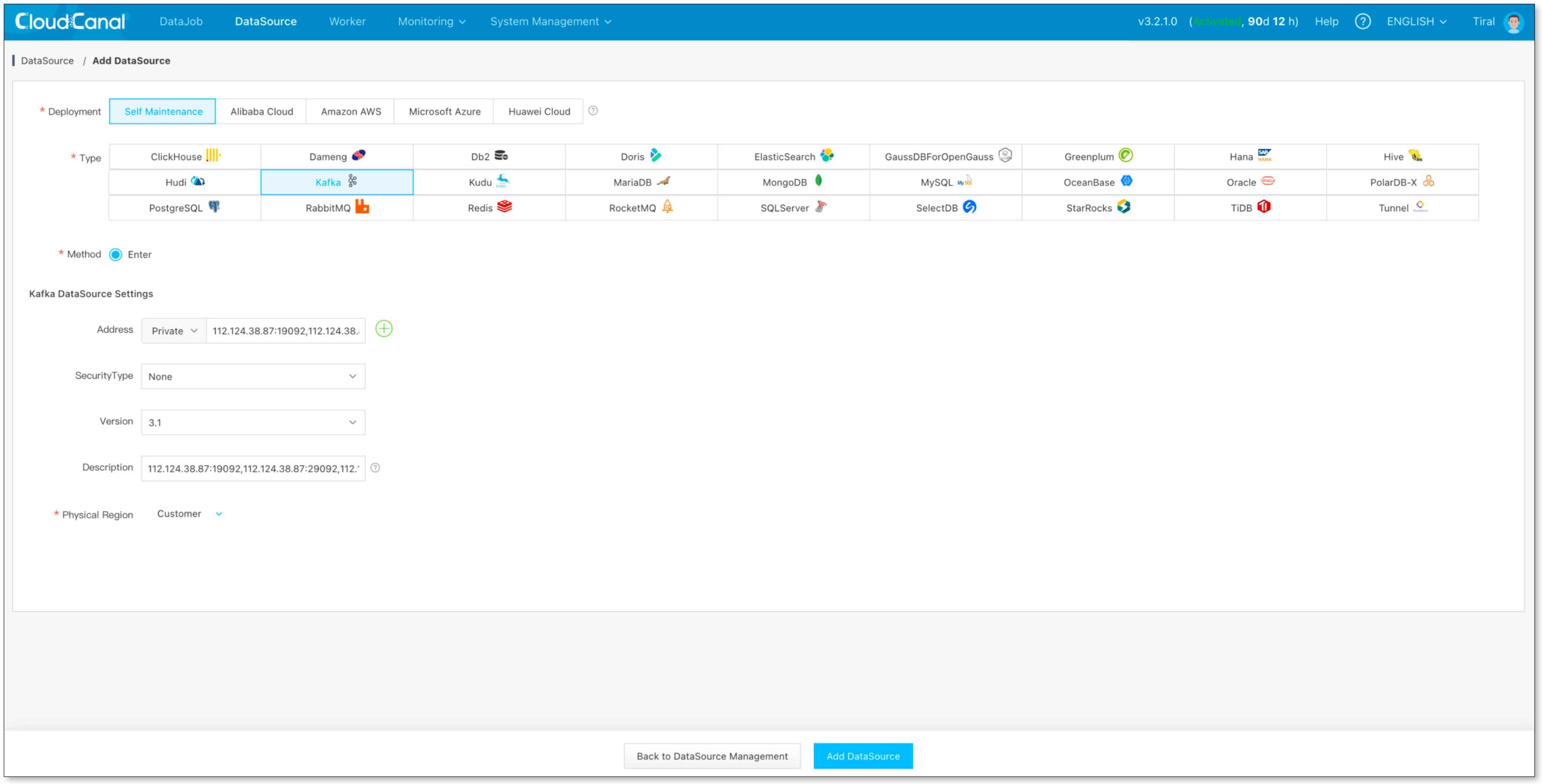

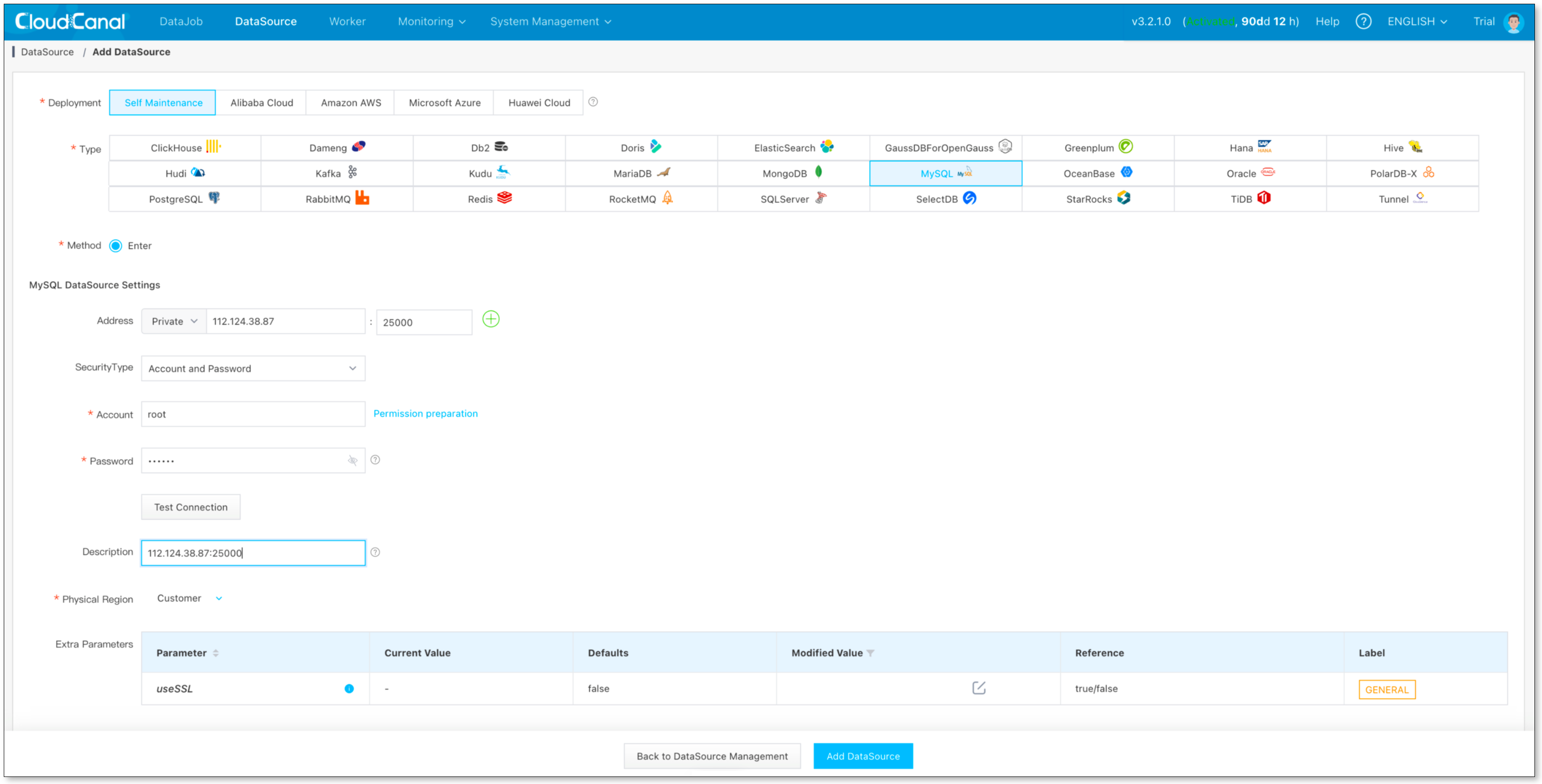
创建同步任务
-
任务管理-> 新建任务
-
Kafka选择 Debezium Envelope Json Format格式
-
该消息格式的说明,参见:源端 Kafka Debezium Json 使用说明
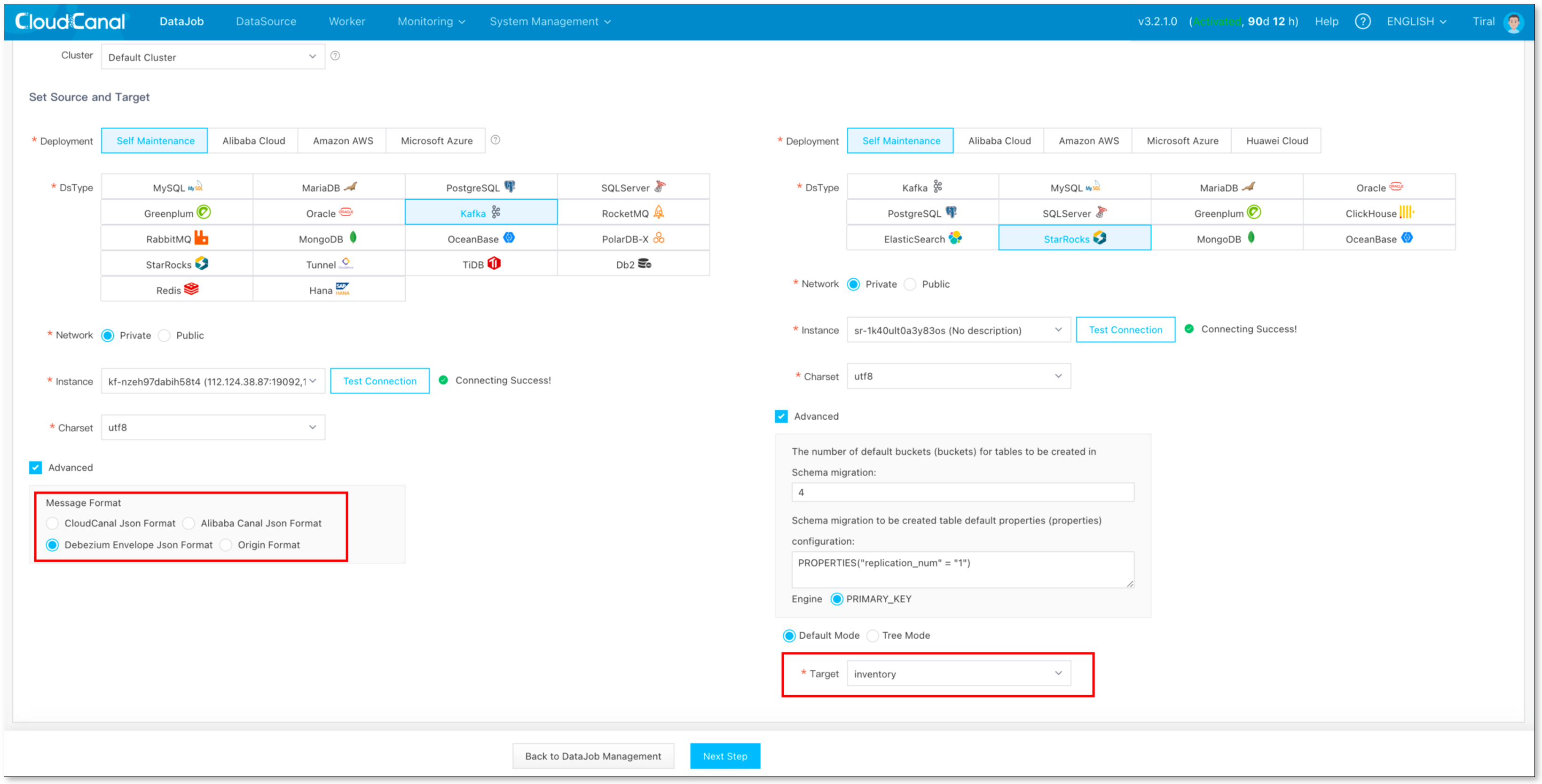
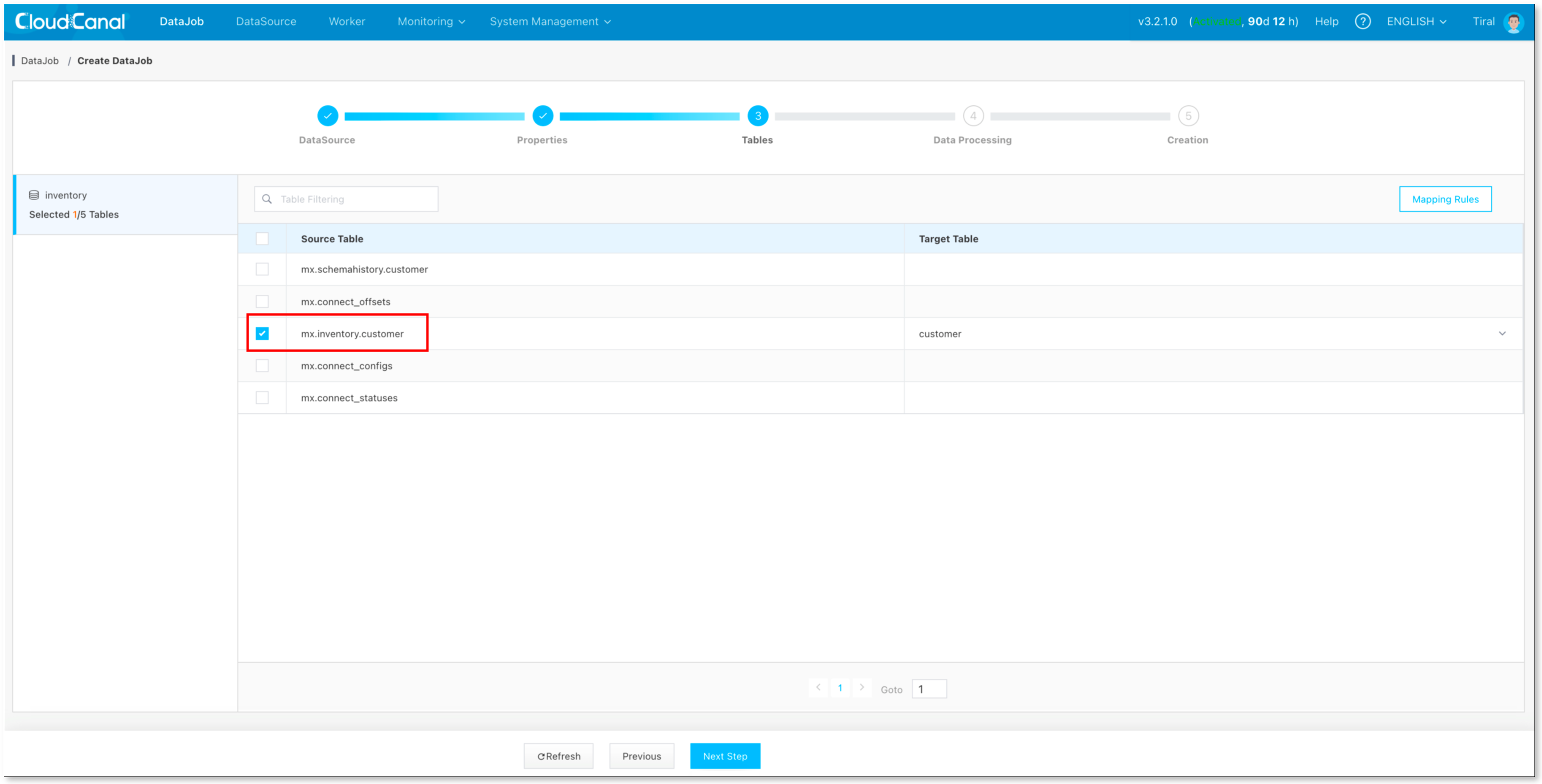
-
Kafka 消息中如果有 Schema,需要在 任务详细 -> 参数修改 -> 源数据源配置 中修改 envelopSchemaInclude 为 true
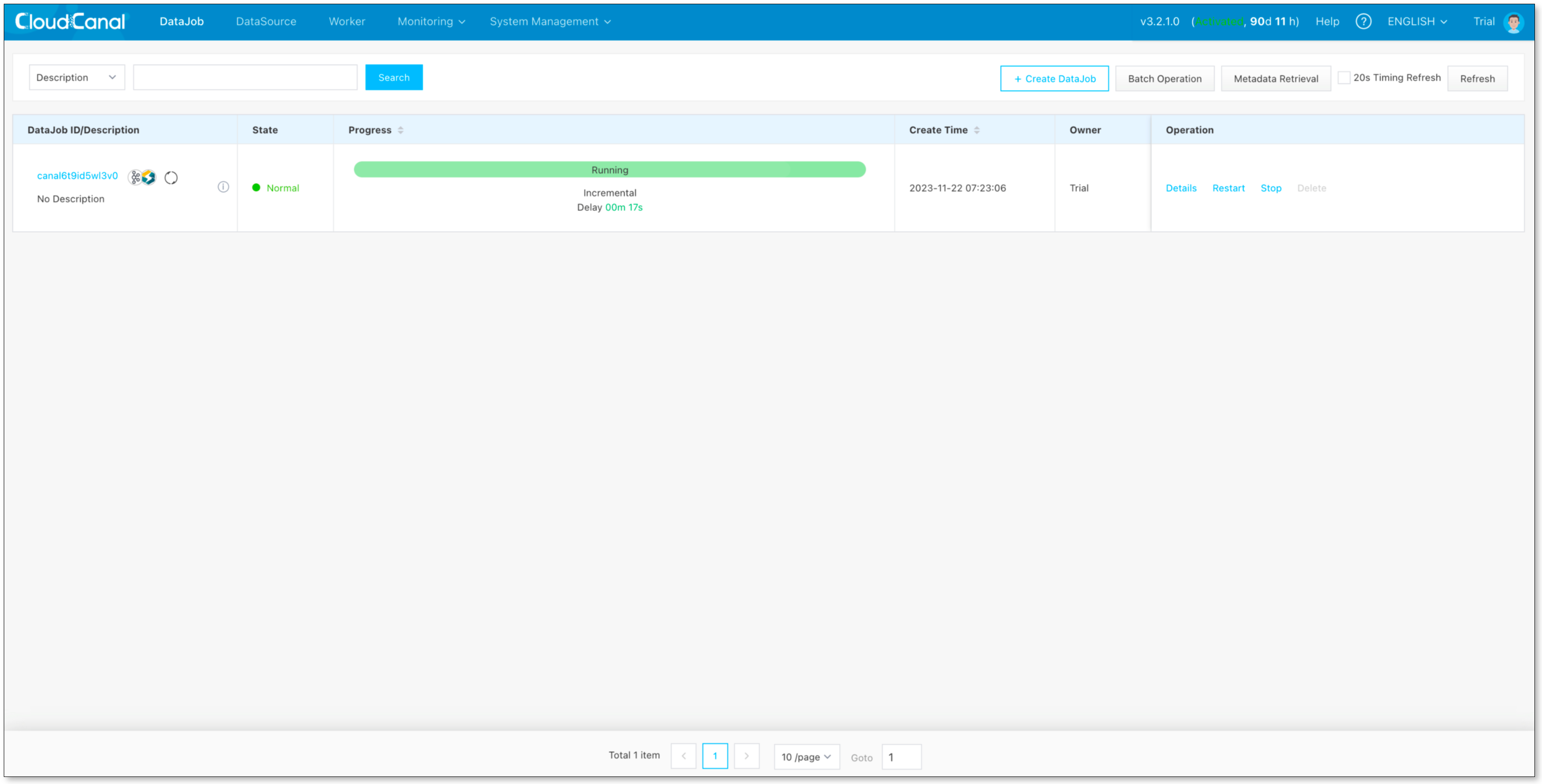
同步测试
-
源端数据库做数据变更,Debezium 将数据写入 Kafka 后,CloudCanal 会写入到 Starrocks 中。
-
数据同步结束后校验 MySQL 和 Starrocks 的数据,40 万左右的数据是一致的。

总结
本文介绍了 CloudCanal 支持消费 Debezium 格式数据的背景,以及通过 MySQL -> Kafka -> Starrocks 示例介绍其使用。
这篇关于CloudCanal x Debezium 打造实时数据流动新范式的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




