本文主要是介绍Recorder︱图像特征检测及提取算法、基本属性、匹配方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在做图像的研究,发现对图像本质、内核以及可以提取的特征方式一点儿都不懂,赶紧补补课。
.
一、图像常用属性
本节指的是一般来说,图像处理的一些角度,也是根据一些美图软件最为关注的一些图像属性:
- 基本属性:图像亮度,对比度,色彩饱和度,清晰度(锐度)
- 色阶:曝光、高光、阴影
- 颜色:色温、色调
.
1、图像亮度
来源于:OpenCV改变图像或视频的亮度
改变亮度是在每个像素上的点操作。如果想提高亮度,必须在每个像素上加上一些常数值。
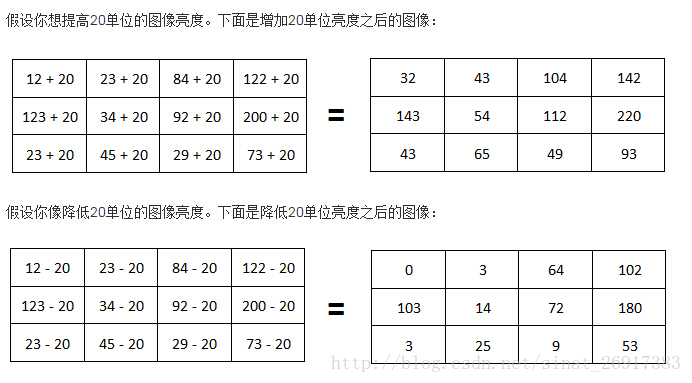
上面图像的第一个像素应该是(12-20)=-8,但是我给它的值为0。这是因为像素不可能为负值。任何像素值的下限是0,上限是2^(位深)。
.
二、图像基本特征
常用的图像特征有颜色特征、纹理特征、形状特征、空间关系特征。
参考博客:图像特征特点及其常用的特征提取与匹配方法
1、颜色特征
颜色对图像或图像区 域的方向、大小等变化不敏感,所以颜色特征不能很好地捕捉图像中对象的局部特征。颜色直方图是最常用的表达颜色特征的方法,其优点是不受图像旋转和平移变化的影响,进一步借助归一化还可不受图像尺度变化的影响,基缺点是没有 表达出颜色空间分布的信息。
- 颜色直方图:
其 优点在于:它能简单描述一幅图像中颜色的全局分布,即不同色彩在整幅图像中所占的比例,特别适用于描述那些难以自动分割的图像和不需要考虑物体空间位置的 图像。其缺点在于:它无法描述图像中颜色的局部分布及每种色彩所处的空间位置,即无法描述图像中的某一具体的对象或物体。
最常用的颜色空间:RGB颜色空间、HSV颜色空间。
颜色直方图特征匹配方法:直方图相交法、距离法、中心距法、参考颜色表法、累加颜色直方图法。
- 颜色集
颜色直方图法是一种全局颜色特征提取与匹配方法,无法区分局部颜色信息。颜色集是对颜色直方图的一种近似首先将图像从 RGB颜色空间转化成视觉均衡的颜色空间(如 HSV 空间),并将颜色空间量化成若干个柄。然后,用色彩自动分割技术将图像分为若干区域,每个区域用量化颜色空间的某个颜色分量来索引,从而将图像表达为一个二进制的颜色索引集。在图像匹配中,比较不同图像颜色集之间的距离和色彩区域的空间关系
- 颜色矩
这种方法的数学基础在于:图像中任何的颜色分布均可以用它的矩来表示。此外,由于颜色分布信息主要集中在低阶矩中,因此,仅采用颜色的一阶矩(mean)、二阶矩(variance)和三阶矩(skewness)就足以表达图像的颜色分布。
- 颜色聚合向量
其核心思想是:将属于直方图每一个柄的像素分成两部分,如果该柄内的某些像素所占据的连续区域的面积大于给定的阈值,则该区域内的像素作为聚合像素,否则作为非聚合像素。
- 颜色相关图
.
2、纹理特征
描述了图像或图像区域所对应景物的表面性质。但由于纹理只是一种物体表面的特性,并不能完全反映出物体的本质属性, 所以仅仅利用纹理特征是无法获得高层次图像内容的。
与颜色特征不同,纹理特征不是基于像素点的特征,它需要在包含多个像素点的区域中进行统计计算。
作为一种统计特征,纹理特征常具有旋转不变性,并且对于噪声有较强的抵抗 能力。
但是,纹理特征也有其缺点,一个很明显的缺点是当图像的分辨率变化的时候,所计算出来的纹理可能会有较大偏差。
在检索具有粗细、疏密等方面较大差别的纹理图像时,利用纹理特征是一种有效的方法。但当纹理之间的粗细、疏密等易于分辨的信息之间相差不大的时候,通常的纹理特征很难准确地反映出人的视觉感觉不同的纹理之间的差别。
- (1)统计方法
统计方法的典型代表是一种称为灰度共生矩阵的纹理特征分析方法Gotlieb 和 Kreyszig 等人在研究共生矩阵中各种统计特征基础上,通过实验,得出灰度共生矩阵的四个关键特征:能量、惯量、熵和相关性。统计方法中另一种典型方法,则是从图像的自相关函数(即图像的能量谱函数)提取纹理特征,即通过对图像的能量谱函数的计算,提取纹理的粗细度及方向性等特征参数
- (2)几何法
所谓几何法,是建立在纹理基元(基本的纹理元素)理论基础上的一种纹理特征分析方法。纹理基元理论认为,复杂的纹理可以由若干简单的纹理基元以一定的有规律的形式重复排列构成。在几何法中,比较有影响的算法有两种:Voronio 棋盘格特征法和结构法。
- (3)模型法
模型法以图像的构造模型为基础,采用模型的参数作为纹理特征。典型的方法是随机场模型法,如马尔可夫(Markov)随机场(MRF)模型法和 Gibbs 随机场模型法
- (4)信号处理法
纹理特征的提取与匹配主要有:灰度共生矩阵、Tamura 纹理特征、自回归纹理模型、小波变换等。
灰度共生矩阵特征提取与匹配主要依赖于能量、惯量、熵和相关性四个参数。Tamura 纹理特征基于人类对纹理的视觉感知心理学研究,提出6种属性,即:粗糙度、对比度、方向度、线像度、规整度和粗略度。自回归纹理模型(simultaneous auto-regressive, SAR)是马尔可夫随机场(MRF)模型的一种应用实例。
.
3、形状特征
种基于形状特征的检索方法都可以比较有效地利用图像中感兴趣的目标来进行检索,但它们也有一些共同的问题,包括:
①目前基于形状的检索方法还缺乏 比较完善的数学模型;
②如果目标有变形时检索结果往往不太可靠;
③许多形状特征仅描述了目标局部的性质,要全面描述目标常对计算时间和存储量有较高的要 求;
④许多形状特征所反映的目标形状信息与人的直观感觉不完全一致,或者说,特征空间的相似性与人视觉系统感受到的相似性有差别。
- (1)边界特征法
该方法通过对边界特征的描述来获取图像的形状参数。其中Hough 变换检测平行直线方法和边界方向直方图方法是经典方法。Hough 变换是利用图像全局特性而将边缘像素连接起来组成区域封闭边界的一种方法,其基本思想是点—线的对偶性;边界方向直方图法首先微分图像求得图像边缘,然后,做出关于边缘大小和方向的直方图,通常的方法是构造图像灰度梯度方向矩阵。
- (2)傅里叶形状描述符法
傅里叶形状描述符(Fourier shape descriptors)基本思想是用物体边界的傅里叶变换作为形状描述,利用区域边界的封闭性和周期性,将二维问题转化为一维问题。
由边界点导出三种形状表达,分别是曲率函数、质心距离、复坐标函数。
- (3)几何参数法
形状的表达和匹配采用更为简单的区域特征描述方法,例如采用有关形状定量测度(如矩、面积、周长等)的形状参数法(shape factor)。在 QBIC 系统中,便是利用圆度、偏心率、主轴方向和代数不变矩等几何参数,进行基于形状特征的图像检索。
需要说明的是,形状参数的提取,必须以图像处理及图像分割为前提,参数的准确性必然受到分割效果的影响,对分割效果很差的图像,形状参数甚至无法提取。
- (4)形状不变矩法
利用目标所占区域的矩作为形状描述参数。
- (5)其它方法
近年来,在形状的表示和匹配方面的工作还包括有限元法(Finite Element Method 或 FEM)、旋转函数(Turning Function)和小波描述符(Wavelet Descriptor)等方法。
- 基于小波和相对矩的形状特征提取与匹配
该方法先用小波变换模极大值得到多尺度边缘图像,然后计算每一尺度的 7个不变矩,再转化为 10 个相对矩,将所有尺度上的相对矩作为图像特征向量,从而统一了区域和封闭、不封闭结构。
.
4、空间关系特征
指图像中分割出来的多个目标之间的相互的空间位置或相对方向关系,这些关系也可分为连接/邻接关系、交叠/重叠关系和包含/包 容关系等。通常空间位置信息可以分为两类:相对空间位置信息和绝对空间位置信息。
前一种关系强调的是目标之间的相对情况,如上下左右关系等,后一种关系强 调的是目标之间的距离大小以及方位。显而易见,由绝对空间位置可推出相对空间位置,但表达相对空间位置信息常比较简单。
空间关系特征的使用可加强对图像内容的描述区分能力,但空间关系特征常对图像或目标的旋转、反转、尺度变化等比较敏感。另外,实际应用中,仅仅利用空间信息往往是不够的,不能有效准确地表达场景信息。为了检索,除使用空间关系特征外,还需要其它特征来配合
提取图像空间关系特征可以有两种方法:一种方法是首先对图像进行自动分割,划分出图像中所包含的对象或颜色区域,然后根据这些区域提取图像特征,并建立索引;另一种方法则简单地将图像均匀地划分为若干规则子块,然后对每个图像子块提取特征,并建立索引。
.
三、图像的统计特征
一般图像的统计特征可以分为四类:直观性特征、灰度统计特征、变换系数特征与代数特征。
.
1、直观性特征
直观性特征主要指几何特征,几何特征比较稳定,受人脸的姿态变化与光照条件等因素的影响小,但不易抽取,而且测量精度不高,与图像处理技术密切相关。
.
2、灰度统计特征
灰度共生矩阵的四个关键特征:能量、惯量、熵和相关性。统计方法中另一种典型方法,则是从图像的自相关函数(即图像的能量谱函数)提取纹理特征,即通过对图像的能量谱函数的计算,提取纹理的粗细度及方向性等特征参数
.
3、变换系数特征
变换系数特征指先对图像进行Fourier变换、小波变换等,得到的系数后作为特征进行识别。
.
4、代数特征
代数特征是基于统计学习方法抽取的特征。代数特征具有较高的识别精度,代数特征抽取方法又可以分为两类:一种是线性投影特征抽取方法;另外一种是非线性特征抽取方法。
习惯上,将基于主分量分析和Fisher线性鉴别分析所获得的特征抽取方法,统称为线性投影分析。
基于线性投影分析的特征抽取方法,其基本思想是根据一定的性能目标来寻找一线性变换,把原始信号数据压缩到一个低维子空间,使数据在子空间中的分布更加紧凑,为数据的更好描述提供手段,同时计算的复杂度得到大大降低。
在线性投影分析中,以主分量分析(PCA,或称K-L变换)和Fisher线性鉴别分析(LDA)最具代表性,围绕这两种方法所形成的特征抽取算法,已成为模式识别领域中最为经典和广泛使用的方法。
线性投影分析法的主要缺点为:需要对大量的已有样本进行学习,且对定位、光照与物体非线性形变敏感,因而采集条件对识别性能影响较大。
非线性特征抽取方法也是研究的热点之一。“核技巧”最早应用在SVM中,KPCA和KFA是“核技巧”的推广应用。
核投影方法的基本思想是将原样本空间中的样本通过某种形式的非线性映射,变换到一个高维甚至无穷维的空间,并借助于核技巧在新的空间中应用线性的分析方法求解。由于新空间中的线性方向也对应原样本空间的非线性方向,所以基于核的投影分析得出的投影方向也对应原样本空间的非线性方向。
核投影方法也有一些弱点:几何意义不明确,无法知道样本在非显式映射后变成了什么分布模式;核函数中参数的选取没有相应选择标准,大多数只能采取经验参数选取;不适合训练样本很多的情况,原因是经过核映射后,样本的维数等于训练样本的个数,如果训练样本数目很大,核映射后的向量维数将会很高,并将遇到计算量上的难题。
就应用领域来说,KPCA远没有PCA应用的广泛。如果作为一般性的降维KPCA确实比PCA效果好,特别是特征空间不是一般的欧式空间的时候更为明显。PCA可以通过大量的自然图片学习一个子空间,但是KPCA做不到。
.
四、姿态估计问题
姿态估计问题就是:确定某一三维目标物体的方位指向问题。姿态估计在机器人视觉、动作跟踪和单照相机定标等很多领域都有应用。
基于视觉的姿态估计根据使用的摄像机数目又可分为单目视觉姿态估计和多目视觉姿态估计。根据算法的不同又可分为基于模型的姿态估计和基于学习的姿态估计。
1、基于模型的姿态估计方法
基于模型的方法通常利用物体的几何关系或者物体的特征点来估计。其基本思想是利用某种几何模型或结构来表示物体的结构和形状,并通过提取某些物体特征,在模型和图像之间建立起对应关系,然后通过几何或者其它方法实现物体空间姿态的估计。这里所使用的模型既可能是简单的几何形体,如平面、圆柱,也可能是某种几何结构,也可能是通过激光扫描或其它方法获得的三维模型。
基于模型的姿态估计方法是通过比对真实图像和合成图像,进行相似度计算更新物体姿态。目前基于模型的方法为了避免在全局状态空间中进行优化搜索,一般都将优化问题先降解成多个局部特征的匹配问题,非常依赖于局部特征的准确检测。当噪声较大无法提取准确的局部特征的时候,该方法的鲁棒性受到很大影响。
2、基于学习的姿态估计方法
基于学习的方法一般采用全局观测特征,不需检测或识别物体的局部特征,具有较好的鲁棒性。其缺点是由于无法获取在高维空间中进行连续估计所需要的密集采样,因此无法保证姿态估计的精度与连续性。
基于学习的方法一般采用全局观测特征,可以保证算法具有较好的鲁棒性。然而这一类方法的姿态估计精度很大程度依赖于训练的充分程度。要想比较精确地得到二维观测与三维姿态之间的对应关系,就必须获取足够密集的样本来学习决策规则和回归函数。而一般来说所需要样本的数量是随状态空间的维度指数级增加的,对于高维状态空间,事实上不可能获取进行精确估计所需要的密集采样。因此,无法得到密集采样而难以保证估计的精度与连续性,是基于学习的姿态估计方法无法克服的根本困难。
姿态估计输出的是一个高维的姿态向量,而不是某个类别的类标。因此这一类方法需要学习的是一个从高维观测向量到高维姿态向量的映射,目前这在机器学习领域中还是一个非常困难的问题。
特征是描述模式的最佳方式,且我们通常认为特征的各个维度能够从不同的角度描述模式,在理想情况下,维度之间是互补完备的。
.
五、图像特征提取算法类
1、HOG特征
方向梯度直方图(Histogram of Oriented Gradient, HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。它通过计算和统计图像局部区域的梯度方向直方图来构成特征。Hog特征结合SVM分类器已经被广泛应用于图像识别中,尤其在行人检测中获得了极大的成功。需要提醒的是,HOG+SVM进行行人检测的方法是法国研究人员Dalal在2005的CVPR上提出的,而如今虽然有很多行人检测算法不断提出,但基本都是以HOG+SVM的思路为主。
在一副图像中,局部目标的表象和形状(appearance and shape)能够被梯度或边缘的方向密度分布很好地描述。(本质:梯度的统计信息,而梯度主要存在于边缘的地方)。
与其他的特征描述方法相比,HOG有很多优点。首先,由于HOG是在图像的局部方格单元上操作,所以它对图像几何的和光学的形变都能保持很好的不变性,这两种形变只会出现在更大的空间领域上。其次,在粗的空域抽样、精细的方向抽样以及较强的局部光学归一化等条件下,只要行人大体上能够保持直立的姿势,可以容许行人有一些细微的肢体动作,这些细微的动作可以被忽略而不影响检测效果。因此HOG特征是特别适合于做图像中的人体检测的。
2、LBP特征
LBP(Local Binary Pattern,局部二值模式)是一种用来描述图像局部纹理特征的算子;它具有旋转不变性和灰度不变性等显著的优点。它是首先由T. Ojala, M.Pietikäinen, 和D. Harwood 在1994年提出,用于纹理特征提取。而且,提取的特征是图像的局部的纹理特征。
上述提取的LBP算子在每个像素点都可以得到一个LBP“编码”,那么,对一幅图像(记录的是每个像素点的灰度值)提取其原始的LBP算子之后,得到的原始LBP特征依然是“一幅图片”(记录的是每个像素点的LBP值)。
LBP的应用中,如纹理分类、人脸分析等,一般都不将LBP图谱作为特征向量用于分类识别,而是采用LBP特征谱的统计直方图作为特征向量用于分类识别。
例如:一幅100*100像素大小的图片,划分为10*10=100个子区域(可以通过多种方式来划分区域),每个子区域的大小为10*10像素;在每个子区域内的每个像素点,提取其LBP特征,然后,建立统计直方图;这样,这幅图片就有10*10个子区域,也就有了10*10个统计直方图,利用这10*10个统计直方图,就可以描述这幅图片了。之后,我们利用各种相似性度量函数,就可以判断两幅图像之间的相似性了。

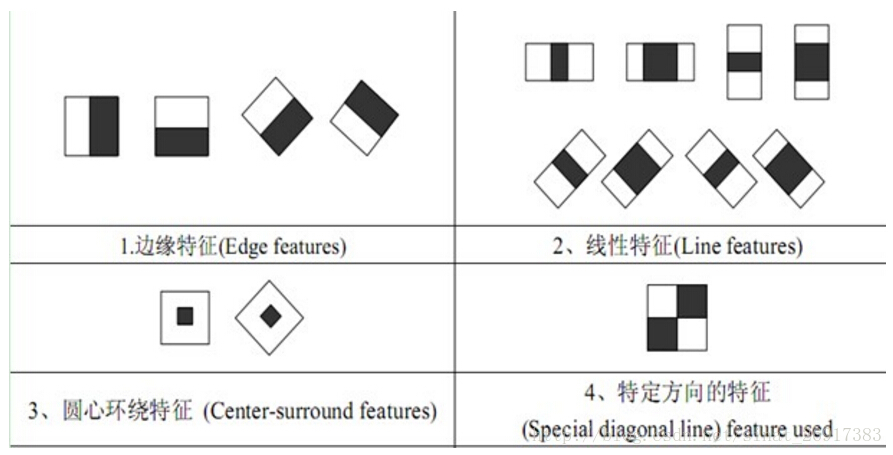
3、Haar-like特征
Haar-like特征最早是由Papageorgiou等应用于人脸表示,Viola和Jones在此基础上,使用3种类型4种形式的特征。
Haar特征分为三类:边缘特征、线性特征、中心特征和对角线特征,组合成特征模板。
特征模板内有白色和黑色两种矩形,并定义该模板的特征值为白色矩形像素和减去黑色矩形像素和。Haar特征值反映了图像的灰度变化情况。例如:脸部的一些特征能由矩形特征简单的描述,如:眼睛要比脸颊颜色要深,鼻梁两侧比鼻梁颜色要深,嘴巴比周围颜色要深等。但矩形特征只对一些简单的图形结构,如边缘、线段较敏感,所以只能描述特定走向(水平、垂直、对角)的结构。
通过改变特征模板的大小和位置,可在图像子窗口中穷举出大量的特征。上图的特征模板称为“特征原型”;特征原型在图像子窗口中扩展(平移伸缩)得到的特征称为“矩形特征”;矩形特征的值称为“特征值”。
.
4、其他
- Sobel边缘检测
Soble边缘检测算法比较简,实际应用中效率比canny边缘检测效率要高,但是边缘不如Canny检测的准确,但是很多实际应用的场合,sobel边缘却是首选,尤其是对效率要求较高,而对细纹理不太关心的时候。
Soble边缘检测通常带有方向性,可以只检测竖直边缘或垂直边缘或都检测。
- Canny边缘检测
canny边缘检测实际上是一种一阶微分算子检测算法,但为什么这里拿出来说呢,因为它几乎是边缘检测算子中最为常用的一种,也是个人认为现在最优秀的边缘检测算子。Canny提出了边缘检测算子优劣评判的三条标准:
高的检测率。边缘检测算子应该只对边缘进行响应,检测算子不漏检任何边缘,也不应该将非边缘标记为边缘。
精确定位。检测到的边缘与实际边缘之间的距离要尽可能的小。
明确的响应。对每一条边缘只有一次响应,只得到一个点。
Canny边缘检测之所以优秀是因为它在一阶微分算子的基础上,增加了非最大值抑制和双阈值两项改进。利用非极大值抑制不仅可以有效地抑制多响应边缘,而且还可以提高边缘的定位精度;利用双阈值可以有效减少边缘的漏检率。
- ORB特征
它是对FAST特征点与BREIF特征描述子的一种结合与改进,这个算法是由Ethan Rublee,Vincent Rabaud,Kurt Konolige以及Gary R.Bradski在2011年一篇名为“ORB:An Efficient Alternative to SIFT or SURF”的文章中提出。就像文章题目所写一样,ORB是除了SIFT与SURF外一个很好的选择,而且它有很高的效率,最重要的一点是它是免费的,SIFT与SURF都是有专利的,你如果在商业软件中使用,需要购买许可。
- BRIEF特征
可以用PCA、LDA等特征降维的方法来压缩特征描述子的维度。还有一些算法,例如LSH,将SIFT的特征描述子转换为一个二值的码串,然后这个码串用汉明距离进行特征点之间的匹配。这种方法将大大提高特征之间的匹配,因为汉明距离的计算可以用异或操作然后计算二进制位数来实现,在现代计算机结构中很方便。下面来们提取一种二值码串的特征描述子。
BRIEF[1]应运而生,它提供了一种计算二值串的捷径,而并不需要去计算一个类似于SIFT的特征描述子。它需要先平滑图像,然后在特征点周围选择一个Patch,在这个Patch内通过一种选定的方法来挑选出来ndnd个点对。
.
参考文献
1、图像特征类:
关于图像特征提取
图像特征特点及其常用的特征提取与匹配方法
2、图像特征提取算法:
目标检测的图像特征提取之(二)LBP特征
图像特征提取三大法宝:HOG特征,LBP特征,Haar特征
http://www.cnblogs.com/ronny/category/366231.html
.
延伸一:K-means聚类图像压缩:色彩量化
来源于:Image-compression-with-Kmeans-clustering: Color Quantization
from skimage import io
import numpy as npcenters = np.load('codebook_tiger.npy')c_image = io.imread('compressed_tiger.png')image = np.zeros((c_image.shape[0],c_image.shape[1],3),dtype=np.uint8 )
for i in range(c_image.shape[0]):for j in range(c_image.shape[1]):image[i,j,:] = centers[c_image[i,j],:]io.imsave('reconstructed_tiger.png',image);
io.imshow(image)
io.show()效果:

.
延伸二:车辆追踪算法大PK:SVM+HOG vs. YOLO
云栖社区:车辆追踪算法大PK:SVM+HOG vs. YOLO
文章原标题《Vehicle tracking using a support vector machine vs. YOLO》,作者:Kaspar Sakmann,译者:耕牛的人,校核:主题曲(身形)。
对于Udacity(优达学城)自动驾驶汽车纳米学位的汽车检测和跟踪项目,如果使用传统的计算机可视化技术将是一个挑战,就像方向梯度直方图(Histogram of Oriented Gradients,HOG)和其它特征组合在一起在视频里跟踪汽车一样,理想的解决方案应该是实时运行的,如>30FPS,我曾经使用线性SVM来处理视频,在一台i7 CPU计算机上得到的结果只有可怜的3FPS。最后我使用YOLO来处理视频终于通过了Udacity的项目,YOLO是一个超快的用于对象检测的卷积神经网络,如果你的GPU够快(我当时使用的是GTX 1080),视频处理的速度可以达到65FPS,比我用SVM+HOG的方法足足快20倍。

特征提取:
我使用的特征向量如下:
- 空间特征:除了用于自检的像斑(16x16像素)外啥都没有。
- 颜色直方图特征:捕获每个像斑的统计颜色信息,通过这种特征向量捕获的汽车颜色通常是非常饱和的。
- 方向梯度直方图(HOG)特征:捕获每个图像通道的梯度结构,在不同的光线条件下,这种方法表现得还不错。
在这篇博客里有关于HOG特征的详细描述,其思想始终是,在一个直方图里,在一个图像上聚集梯度,让特征向量在不同视角和光线条件下变得更加稳定。下面是HOG特征应用于有车的和没车的图像上时的可视化呈现。
而SVM+HOG方案需要处理大约150次。上面大家看到的视频,我还没有进行过优化,如减少图像或定义兴趣区域,或者针对汽车做特定训练。
在准确性相当时,YOLO比SVM+HOG要快20多倍,检测阈值可以被设置为任意置信水平,我保留默认值(50%),并且除了汽车之外不再检测其它对象,这让我相当兴奋,我将在另一个独立项目中进一步验证汽车检测的可能性。
.
延伸三:轻量级物体检测卷积神经网络SqueezeDet:功耗更低、识别更准确、速度更快
本目录中的代码实现了我们论文中(https://arxiv.org/abs/1612.01051)提出的模型——一个用于自动驾驶中实时物体检测的统一、小型且低耗的完全卷积神经网络。如果我们的工作对您的研究有帮助,您可做如下引用:
@inproceedings{squeezedet,Author = {Bichen Wu and Forrest Iandola and Peter H. Jin and Kurt Keutzer},Title = {SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real-Time Object Detection for Autonomous Driving},Journal = {arXiv:1612.01051},Year = {2016}安装
Linux环境下可执行以下命令:
拷贝SqueezeDet的目录:
git clone https://github.com/BichenWuUCB/squeezeDet.git我们以$SQDT_ROOT来调用SqueezeDet的顶层目录。
(可选)设置你自己的虚拟环境:
1.以下的操作假设运行的Python版本是Python2.7。找到你的用户主目录下,并在此创建虚拟环境。
cd ~virtualenv env --python=python2.启动虚拟环境
source env/bin/activate使用pip安装所需的Python工具包
pip install -r requirements.txt演示
从这里(https://www.dropbox.com/s/a6t3er8f03gdl4z/model_checkpoints.tgz?dl=0)下载SqueezeDet模型的参数,解压,并将解压后的文件放在$SQDT_ROOT/data/目录下。命令行下的命令如下:
cd $SQDT_ROOT/data/wget https://www.dropbox.com/s/a6t3er8f03gdl4z/model_checkpoints.tgztar -xzvf model_checkpoints.tgzrm model_checkpoints.tgz现在我们可以运行Demo了。执行以下命令可以检测样本中的图像
$SQDT_ROOT/data/sample.png,
cd $SQDT_ROOT/python ./src/demo.py如果想检测其他图片,可以修改input_path=./data/*.png使其指向其他的图片。由于输入的图片会被缩放为1242x375的分辨率(KITTI图片分辨率),所以当输入图片接近此分辨率时模型的效果最佳。
SqueezeNet实现的是实时的物体检测,因此可以用来检测一段视频。之后我们会发布检测视频的Demo。
训练及验证
从这里(图片:http://www.cvlibs.net/download.php?file=data_object_image_2.zip,标签:http://www.cvlibs.net/download.php?file=data_object_label_2.zip)下载KITTI物体检测的数据集,并将它们放到SQDT_ROOT/data/KITTI/目录下,解压后会生成SQDT_ROOT/data/KITTI/training/ 和$SQDT_ROOT/data/KITTI/testing/两个子目录。
现在,我们需要将原来的训练集重新划分为训练集和验证集。
cd $SQDT_ROOT/data/KITTI/mkdir ImageSetscd ./ImageSetsls ../training/image_2/ | grep ".png" | sed s/.png// > trainval.txttrainval.txt这个文件记录了训练集中所有图片的索引。实验中,我们随机选取trainval.txt文件里一半的索引作为新的训练集图片的索引并存到train.txt,其余的作为验证集存到val.txt。为了方便读者使用,我们编写了下面的脚本以自动完成数据集的重新划分:
cd $SQDT_ROOT/data/python random_split_train_val.py然后,我们需要从$SQDT_ROOT/data/KITTI/ImageSets下得到train.txt和val.txt。
这篇关于Recorder︱图像特征检测及提取算法、基本属性、匹配方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




