本文主要是介绍[ Redis ] 从一致性哈希算法说起,到 RedisCluster 集群的介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言: 哨兵管理下的主从复制只做到了对一台Redis的高可用,本质上只存有一台机的数据容量。 —— 那么如果海量数据量超过了这台机器的容量呢? 你也许想到了,再对哨兵管理下的读写分离做集群。但是这个集群该怎么做呢?

最简单的做法,就是哈希分片(你可以类比HashMap) —— 原本所有数据是存在一个小规模读写分离集群上的。当数据超过这个小规模集群的时候。我们就应该做大规模集群了。这时候我们把这个小规模集群看成一个分片。配置多个这样的分片,然后通过哈希算法+对分片个数取模(类似HashMap存储数据时计算下标的方式)把所有数据均匀分布在这些分片上。
—— 但是这样的集群存在一个问题,你要对集群的机器再做扩容或者缩容怎么办?哈希分片的位置是依靠分片个数来计算的,现在你分片个数变了。那必然导致要查询的数据映射不到原本应有的机器上,造成缓存雪崩效应…
这个时候的分片我们就可以用哈希算法的进化版 —— 一致性哈希是算法,这个算法的特点就是扩容/缩容只会导致极少量的缓存失效,这里我只做大致的讲解,对于这个算法的细节,本人强烈推荐这位大佬的博文:白话解析:一致性哈希算法 consistent hashing
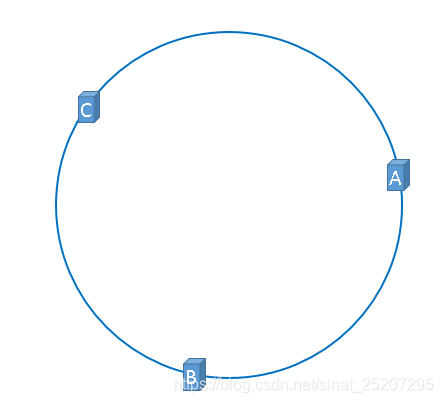
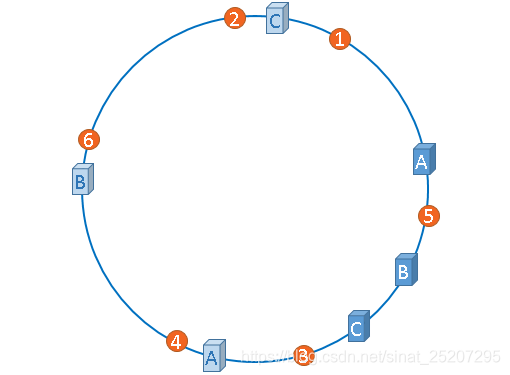
- 一致性哈希算法本质上也是要求模,我们可以想象一个原上有2^32个点,假设我们对三台机的IP做哈希后取模(hash(服务器IP地址) % 2^32),得出的结果映射在这个圆环上,就是这三台机器应有的位置。
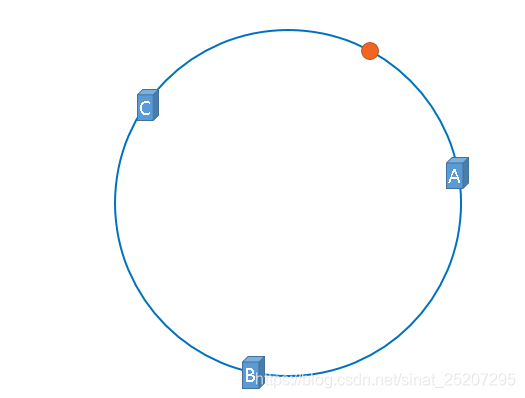
2. 假设这时候来了一个缓存数据的请求操作经过(hash(缓存数据) % 2^32)后,映射在途中橙点位置,那么这个点没有缓存机器怎么办? 这时就会按照顺时针找到的第一个节点作为缓存请求对象,如此以往。
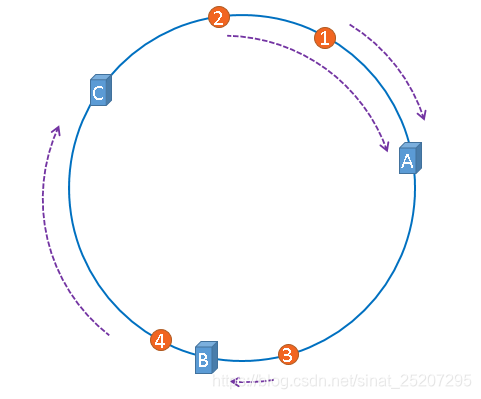
3. 那么就很容易看出来,由于这个顺时针寻址的操作 —— 当要扩容或者缩容/宕机时,就只有一台机的缓存数据会受影响(如下图,如果把B去掉,那么3的缓存请求就会打到C上,这时候C再去数据库同步一次数据就行了,扩容同理)。
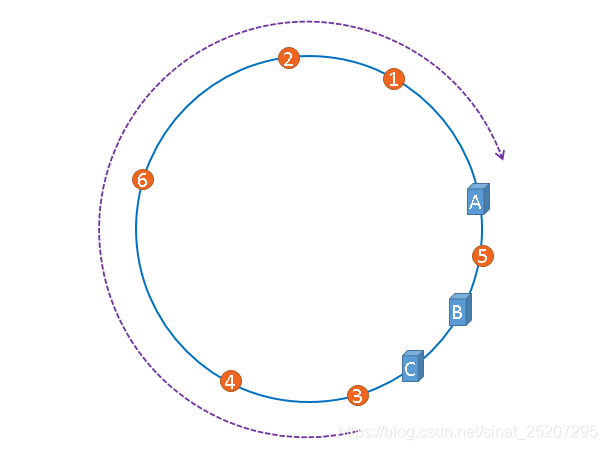
4. 但是理想是丰满的,现实确是骨感的,如果哈希算法后三台机器分布的节点不均匀怎么办? 如下图,3、4、6、2、1的缓存请求全部打在机器A上。
5. 那这个时候就要引入虚拟节点的概念了 —— 这个可以对原有哈希是算法进行加工(如某些算法依赖哈希种子,就可以改变这个种子),然后做多次哈希计算(有点布隆过滤器下标的味道了…),将原本的一个节点,虚拟出多个节点,分布在不同位置,进一步扩大节点的均匀分布程度,结果就如下所示,这时候就解决各机器可能分布不均的问题了。
上面大概解释了一致性哈希算法做大规模数据集群的概念,但Redis做大规模集群用的最多的还是官方推出的RedisCluster —— 首先这是一个去中心化的集群思想(原本的哨兵是不是类似一个中心?来管理主从复制的小规模集群)。这新方案相当于让每个主节点不但具备和从节点完成读写分离的能力,同时自身还具备了哨兵的选举能力(主节点之间会相互监督),和动态扩/缩容(和哈希一致性算法有类似之处)的能力,当然对Redis的集群方案有很多,下面简单罗列一下,仅供知识拓展,因为现在主流、好用的大规模集群还是RedisCluster。
Redis集群还可以通过:
- 哈希一致性算法对每台机进行分片(上文已描述),从而达到集群效果,缺点是开发人员维护成本相对较高
- 使用Twemproxy —— 推特最开始出的集群方案之一,但是缺点是无法在线扩容、缩容
- Codis集群 —— 很优秀的一个集群方案,前豌豆荚大神开发,但要想使用Codis,必须使用它内置的Redis,所以它内部的版本号就很重要了,可惜的是这个项目再Redis3.2.8后就没维护了
- 官方推出的RedisCluster去中心化大规模集群方案 ( 如下文描述 )
RedisCluster大规模集群
RedisCluster集群和哈希一致性算法有点类似,但是它不是一台机器映射一个节点的方式。而是一台机器管理多少个节点(这里我们把节点称为槽)的方式来做集群,具体如下:
-
所有的redis节点彼此互联(通过PING-PONG机制来确认彼此是否健康),内部使用二进制协议优化传输速度和带宽。
-
节点的fail是通过集群中超过半数的节点检测失效时才生效 —— 以上两点和哨兵是一样的思想,假设对一台机器发送Ping超过多久没返回,就会主观认为这台机器挂了,然后其他机器也会对这台机器发Ping信号,如果一半以上认为挂了就客观上认为真的挂了,此时会做新主节点选举的事情。(不管是RedisCluster还是哨兵的故障转移,他们底层使用的都是Raft算法)
-
Redis把[0-16383]个槽均匀分布给每一台机器管理,比如A, B, C 三个节点,它们可以是一台机器上的三个端口,也可以是三台不同的服务器。那么,采用哈希槽 (hash slot)的方式来分配16384个slot 的话,它们三个节点分别承担的slot 区间是:
-
节点A覆盖0-5460;
-
节点B覆盖5461-10922;
-
节点C覆盖10923-16383.

[ RedisCluster集群图示 ]
-
-
当有数据来时会对这个数据做哈希+取模计算出数据的归属槽位(如:CRC16(缓存数据) & 16384-1),请求任一机器,这时机器内就会计算,如果是当前管理的槽位,就会去找数据返回。反之会把管理当前槽位的机器信息通过叫做Move的命令发给客户端重定向到对应的机器上来获取结果。
-
如果这时候做动态扩容,那么就会把每个节点管理的槽位分一部分到新的节点上,比如:
- 节点A覆盖1365-5460
- 节点B覆盖6827-10922
- 节点C覆盖12288-16383
- 节点D覆盖0-1364,5461-6826,10923-12287
同样删除一个节点也是类似,移动完成后就可以删除这个节点了。
-
动态扩容时如果来了缓存请求,机器发现槽点由正在扩容的机器上管理,就会把新机器的信息通过一个叫ask的命令发送给客户端去寻找对应数据。
总结:
- 一致性哈希算法集群: 由2^32 个节点组成的环,机器的IP地址做哈希运算然后对2^32取模后的节点映射在环上。缓存请求通过同样的算法+顺时针寻址找到对应的机器 —— 这样的好处是动态扩/缩容只会影响极小部分数据。而为了分布更加均匀,采用对机器做多次哈希,虚拟出不同节点来优化。
- RedisCluster集群: 将16384个槽位均匀分给每台机管理,缓存请求机器时,会用哈希算法+取模得出对应的槽位。机器内部会做运算,检测当前槽位是否属于自身,是则返回数据,否则重定向到对应的机器返回数据 —— 动态扩/缩容时会对16384个槽位做二次分配。当有请求过来是,也是通过机器内部分析找出管理槽位的机器节点并返回相应数据。(需要注意的是:采用去中心化概念,主节点之间相互监督,完成故障转移。 故障转移的选举方式和哨兵一样,都是采用Raft算法)
本文参考:
Redis-Cluster集群
高可用Redis(十二):Redis Cluster
白话解析:一致性哈希算法 consistent hashing
Redis集群化方案对比:Codis、Twemproxy、Redis Cluster
另外推荐一位非常棒博主,他对Redis的理解更加透彻 —— http://kaito-kidd.com/
这篇关于[ Redis ] 从一致性哈希算法说起,到 RedisCluster 集群的介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






