本文主要是介绍小鼠脑立体定位图谱_三维成像成就空间组学 致力人类脑图谱数据更新,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
近日,由多国遗传学家和神经科学家组成的团队,通过多组学数据库资源整合并结合三维组织器官成像技术,获得了更进一步的人全脑区蛋白编码转录组分析图谱。文献发表于3月6日的Science上,同时相关数据已被Human Protein Atlas (HPA) Brain Atlas数据库收录。该研究令人类脑图谱数据更加完善的同时,通过比对多种属的脑部转录组数据,对神经系统研究模型建立提出了新思考。
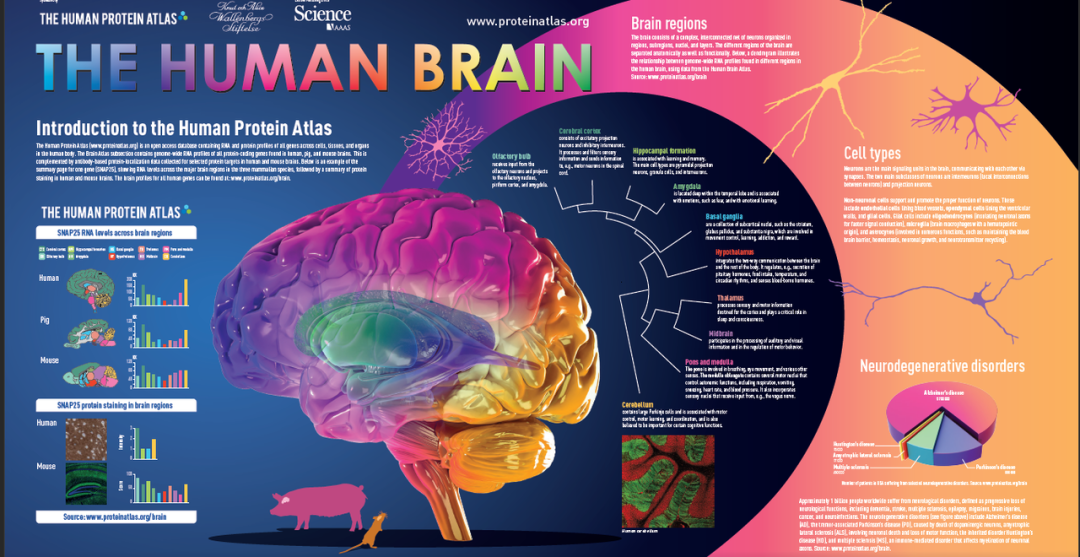
对脑的研究不仅仅因其生理功能、分子结构和基因表达的的复杂性,深入探究分子、蛋白及细胞水平的结构、功能将对了解脑高级功能和疾病发生具有重要意义,这也就是人类脑图谱计划Human Brain Atlas (part of Human Protein Atlas, HPA) 的目的所在。
现有的可用于哺乳动物大脑基因图谱数据库包括Genotype-Tissue Expression (GTEx), Functional Annotation of Mammalian Genomes 5 (FANTOM5)和Allen Mouse Brain Atlas。HPA和GTEx数据库是基于基因3‘端Poly-A尾富集后扩增的方法得到的转录组信息,经典组蛋白mRNA信息将无法获得;只有FANTOM5数据库内包含基于5’端cap的逆转录扩增数据。因此,多数据库的整合比对的好处,在于充分减轻转录组分析的3’端偏好(3’ bias)问题。基于这三大数据库,产生更全面的不同脑区内编码蛋白的基因组学数据。
通过对人、小鼠和猪的不同脑区内蛋白编码基因组比对,种属差异性和研究模型的可靠性再次受到关注。研究显示,与脑基础结构和功能相关的基因在不同哺乳动物物种的进化过程中得到保留,然而神经递质传导相关的受体则在不同物种间存在极大的表达水平差异,以人和小鼠为最。这提示:当采用小鼠用于人类脑疾病研究模型,特别是开发治疗方案和药物时,需格外谨慎看待数据和结论。就连某些神经科学研究领域中被广泛采用的细胞类型标记物,在外周器官中的表达水平往往还更高。
一个与帕金森症治疗药物开发密切相关的基因:络氨酸羟化酶(Tyrosine Hydroxylae, TH)在不同种属间的表达水平和脑区截然不同。

这些结果都提示,在神经生物学研究中,需要选择更符合生理病理意义的模型,且基于整体器官的分析方法更加重要。
成年啮齿动物脑解离更有利于从事神经退行性疾病的细胞模型建立:
✦成年后神经网络发育完善,神经元数量稳定,药理学和电生理学反应成熟;
✦成体动物各种细胞类型发育完全,小胶质细胞、少突胶质细胞比例达到顶峰且稳定,具备完善的功能性;
✦血脑屏障组成细胞均发育成熟,屏障功能完备。
独创且革命性的Adult Brain Dissociation Kit, mouse and rat(成年脑解离试剂盒)以最优化的酶组合,gentleMACS Octo八通道全自动组织解离器充分高效解离成年脑组织细胞外基质成分,保证细胞活力的同时保留细胞表位信息,满足多种下游应用需求。
三维整体成像揭示神经系统内RNA和蛋白分布不一致
本研究应用了基于有机试剂的透明化方法制备透明化小鼠脑,实现了三维空间内转录组和蛋白表达定位的分析,观察神经环路结构的同时,首次观察到了RNA和蛋白分布的不一致性。一个实例:去甲肾上腺素摄取转运体SLC6A2 的转录RNA可于脑桥蓝斑核区域的胞体内检测到,这也与通常认知的去甲肾上腺素能神经元的分布一致;然而,SLC6A2蛋白却检测不到,因为蛋白被迅速转运到广泛的轴突网络结构中。相似的实例还有孤儿受体GPR151,其转录RNA可通过原位杂交的方法检测于小鼠下丘脑外侧缰核的神经元胞体内,但蛋白却于投射到脚尖核的轴突内通过免疫标记得到检测。对于这种广泛范围内的蛋白分布检测,只能依赖基于完整组织的三维成像方法。
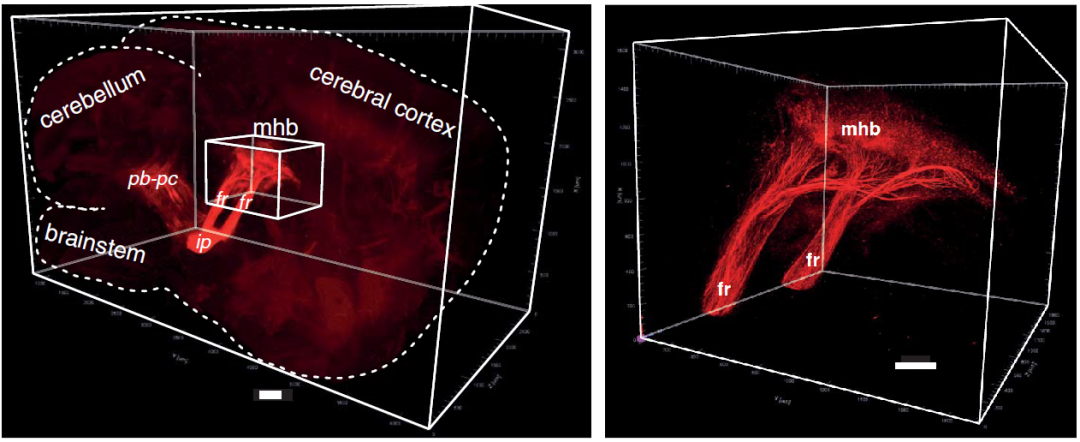
iDISCO+ 透明化后的小鼠全脑进行GRP151受体的免疫染色标记。内侧缰核 (mhb), 中脑切面后屈束(fr), 脚尖核 (ip) 得到较强的染色标记。圈出区域为局部放大。采用UltraMicroscope II, Miltenyi Biotec进行图像采集。比例尺250 μm.
组织器官整体三维成像无疑成为影像分析的新宠,该方法基于透明化的组织块进行光片扫描后的图像数据三维重建。与传统光学显微成像和共聚焦扫描成像等方法相比,避免了切片后染色带来的伪信号、光漂白效应剧烈等缺陷,最重要的是,在器官整体层面进行研究,探究如神经环路、淋巴管分布、血管支配等连续系统中具有绝对的优势。

网络讲座
想更进一步了解三维整体成像技术的最新应用吗?!
时间:5月28日
主题:Finding the needle in the haystack - identifying tumor burden in sentinel lymph nodes by advanced 3D imaging
主讲人:Matthias Gunzer, PhD
Director of the Institute for Experimental Immunology and Imaging and the Imaging Center Essen (IMCES), University Hospital, University Duisburg-Essen, Germany
点击文章左下角“阅读原文”,即可注册观看!
美天旎中国


在看点这里

这篇关于小鼠脑立体定位图谱_三维成像成就空间组学 致力人类脑图谱数据更新的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






