本文主要是介绍汽车贷款违约预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
逻辑回归
数据说明:本数据是一份汽车贷款违约数据
| 名称 | 中文含义 |
|---|---|
| application_id | 申请者ID |
| account_number | 帐户号 |
| bad_ind | 是否违约 |
| vehicle_year | 汽车购买时间 |
| vehicle_make | 汽车制造商 |
| bankruptcy_ind | 曾经破产标识 |
| tot_derog | 五年内信用不良事件数量(比如手机欠费消号) |
| tot_tr | 全部帐户数量 |
| age_oldest_tr | 最久账号存续时间(月) |
| tot_open_tr | 在使用帐户数量 |
| tot_rev_tr | 在使用可循环贷款帐户数量(比如信用卡) |
| tot_rev_debt | 在使用可循环贷款帐户余额(比如信用卡欠款) |
| tot_rev_line | 可循环贷款帐户限额(信用卡授权额度) |
| rev_util | 可循环贷款帐户使用比例(余额/限额) |
| fico_score | FICO打分 |
| purch_price | 汽车购买金额(元) |
| msrp | 建议售价 |
| down_pyt | 分期付款的首次交款 |
| loan_term | 贷款期限(月) |
| loan_amt | 贷款金额 |
| ltv | 贷款金额/建议售价*100 |
| tot_income | 月均收入(元) |
| veh_mileage | 行使历程(Mile) |
| used_ind | 是否二手车 |
| weight | 样本权重 |
%matplotlib inline
import os
import numpy as np
from scipy import stats
import pandas as pd
import statsmodels.api as sm
import statsmodels.formula.api as smf
import matplotlib.pyplot as plt
# os.chdir(‘E:/data’)
pd.set_option(‘display.max_columns’, None)
导入数据和数据清洗
accepts = pd.read_csv('accepts.csv', skipinitialspace=True)
accepts = accepts.dropna(axis=0, how='any')
分类变量的相关关系
- 曾经破产标识与是否违约是否有关系?
交叉表
cross_table = pd.crosstab(accepts.bankruptcy_ind, accepts.bad_ind, margins=True)
cross_table
| bad_ind | 0 | 1 | All |
|---|---|---|---|
| bankruptcy_ind | |||
| N | 3076 | 719 | 3795 |
| Y | 243 | 67 | 310 |
| All | 3319 | 786 | 4105 |
列联表
def percConvert(ser):return ser/float(ser[-1])
cross_table.apply(percConvert, axis=1)
| bad_ind | 0 | 1 | All |
|---|---|---|---|
| bankruptcy_ind | |||
| N | 0.810540 | 0.189460 | 1.0 |
| Y | 0.783871 | 0.216129 | 1.0 |
| All | 0.808526 | 0.191474 | 1.0 |
print('''chisq = %6.4f
p-value = %6.4f
dof = %i
expected_freq = %s''' %stats.chi2_contingency(cross_table.iloc[:2, :2]))
chisq = 1.1500
p-value = 0.2835
dof = 1
expected_freq = [[3068.35688185 726.64311815][ 250.64311815 59.35688185]]
逻辑回归
accepts.plot(x='fico_score', y='bad_ind', kind='scatter')
<matplotlib.axes._subplots.AxesSubplot at 0x63c4ef0>

•随机抽样,建立训练集与测试集
train = accepts.sample(frac=0.7, random_state=1234).copy()
test = accepts[~ accepts.index.isin(train.index)].copy()
print(' 训练集样本量: %i \n 测试集样本量: %i' %(len(train), len(test)))
训练集样本量: 2874 测试集样本量: 1231
lg = smf.glm('bad_ind ~ fico_score', data=train, family=sm.families.Binomial(sm.families.links.logit)).fit()
lg.summary()
| Dep. Variable: | bad_ind | No. Observations: | 2874 |
|---|---|---|---|
| Model: | GLM | Df Residuals: | 2872 |
| Model Family: | Binomial | Df Model: | 1 |
| Link Function: | logit | Scale: | 1.0 |
| Method: | IRLS | Log-Likelihood: | -1267.8 |
| Date: | Tue, 29 May 2018 | Deviance: | 2535.7 |
| Time: | 15:04:24 | Pearson chi2: | 2.75e+03 |
| No. Iterations: | 5 |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | 8.8759 | 0.648 | 13.702 | 0.000 | 7.606 | 10.146 |
| fico_score | -0.0151 | 0.001 | -15.687 | 0.000 | -0.017 | -0.013 |
formula = '''bad_ind ~ fico_score + bankruptcy_ind
+ tot_derog + age_oldest_tr + rev_util + ltv + veh_mileage'''
lg_m = smf.glm(formula=formula, data=train,
family=sm.families.Binomial(sm.families.links.logit)).fit()
lg_m.summary().tables[1]
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | 4.9355 | 0.828 | 5.960 | 0.000 | 3.312 | 6.559 |
| bankruptcy_ind[T.Y] | -0.4181 | 0.195 | -2.143 | 0.032 | -0.801 | -0.036 |
| fico_score | -0.0131 | 0.001 | -11.053 | 0.000 | -0.015 | -0.011 |
| tot_derog | 0.0529 | 0.016 | 3.260 | 0.001 | 0.021 | 0.085 |
| age_oldest_tr | -0.0043 | 0.001 | -6.673 | 0.000 | -0.006 | -0.003 |
| rev_util | 0.0008 | 0.001 | 1.593 | 0.111 | -0.000 | 0.002 |
| ltv | 0.0290 | 0.003 | 8.571 | 0.000 | 0.022 | 0.036 |
| veh_mileage | 2.502e-06 | 1.51e-06 | 1.654 | 0.098 | -4.63e-07 | 5.47e-06 |
# 向前法 def forward_select(data, response):remaining = set(data.columns)remaining.remove(response)selected = []current_score, best_new_score = float('inf'), float('inf')while remaining:aic_with_candidates=[]for candidate in remaining:formula = "{} ~ {}".format(response,' + '.join(selected + [candidate]))aic = smf.glm(formula=formula, data=data, family=sm.families.Binomial(sm.families.links.logit)).fit().aicaic_with_candidates.append((aic, candidate))aic_with_candidates.sort(reverse=True)best_new_score, best_candidate=aic_with_candidates.pop()if current_score > best_new_score: remaining.remove(best_candidate)selected.append(best_candidate)current_score = best_new_scoreprint ('aic is {},continuing!'.format(current_score))else: print ('forward selection over!')breakformula <span class="token operator">=</span> <span class="token string">"{} ~ {} "</span><span class="token punctuation">.</span><span class="token builtin">format</span><span class="token punctuation">(</span>response<span class="token punctuation">,</span><span class="token string">' + '</span><span class="token punctuation">.</span>join<span class="token punctuation">(</span>selected<span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token keyword">print</span><span class="token punctuation">(</span><span class="token string">'final formula is {}'</span><span class="token punctuation">.</span><span class="token builtin">format</span><span class="token punctuation">(</span>formula<span class="token punctuation">)</span><span class="token punctuation">)</span> model <span class="token operator">=</span> smf<span class="token punctuation">.</span>glm<span class="token punctuation">(</span>formula<span class="token operator">=</span>formula<span class="token punctuation">,</span> data<span class="token operator">=</span>data<span class="token punctuation">,</span> family<span class="token operator">=</span>sm<span class="token punctuation">.</span>families<span class="token punctuation">.</span>Binomial<span class="token punctuation">(</span>sm<span class="token punctuation">.</span>families<span class="token punctuation">.</span>links<span class="token punctuation">.</span>logit<span class="token punctuation">)</span> <span class="token punctuation">)</span><span class="token punctuation">.</span>fit<span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token keyword">return</span><span class="token punctuation">(</span>model<span class="token punctuation">)</span>
candidates = ['bad_ind', 'fico_score', 'bankruptcy_ind', 'tot_derog','age_oldest_tr', 'rev_util', 'ltv', 'veh_mileage']
data_for_select = train[candidates]lg_m1 = forward_select(data=data_for_select, response='bad_ind')
lg_m1.summary().tables[1]
aic is 2539.6525973826097,continuing!
aic is 2448.972227745799,continuing!
aic is 2406.5983198124773,continuing!
aic is 2401.0559077596185,continuing!
aic is 2397.9413617381233,continuing!
aic is 2397.0135732954586,continuing!
aic is 2396.212716240673,continuing!
final formula is bad_ind ~ fico_score + ltv + age_oldest_tr + tot_derog + bankruptcy_ind + veh_mileage + rev_util
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | 4.9355 | 0.828 | 5.960 | 0.000 | 3.312 | 6.559 |
| bankruptcy_ind[T.Y] | -0.4181 | 0.195 | -2.143 | 0.032 | -0.801 | -0.036 |
| fico_score | -0.0131 | 0.001 | -11.053 | 0.000 | -0.015 | -0.011 |
| ltv | 0.0290 | 0.003 | 8.571 | 0.000 | 0.022 | 0.036 |
| age_oldest_tr | -0.0043 | 0.001 | -6.673 | 0.000 | -0.006 | -0.003 |
| tot_derog | 0.0529 | 0.016 | 3.260 | 0.001 | 0.021 | 0.085 |
| veh_mileage | 2.502e-06 | 1.51e-06 | 1.654 | 0.098 | -4.63e-07 | 5.47e-06 |
| rev_util | 0.0008 | 0.001 | 1.593 | 0.111 | -0.000 | 0.002 |
Seemingly wrong when using ‘statsmmodels.stats.outliers_influence.variance_inflation_factor’
def vif(df, col_i):from statsmodels.formula.api import olscols <span class="token operator">=</span> <span class="token builtin">list</span><span class="token punctuation">(</span>df<span class="token punctuation">.</span>columns<span class="token punctuation">)</span> cols<span class="token punctuation">.</span>remove<span class="token punctuation">(</span>col_i<span class="token punctuation">)</span> cols_noti <span class="token operator">=</span> cols formula <span class="token operator">=</span> col_i <span class="token operator">+</span> <span class="token string">'~'</span> <span class="token operator">+</span> <span class="token string">'+'</span><span class="token punctuation">.</span>join<span class="token punctuation">(</span>cols_noti<span class="token punctuation">)</span> r2 <span class="token operator">=</span> ols<span class="token punctuation">(</span>formula<span class="token punctuation">,</span> df<span class="token punctuation">)</span><span class="token punctuation">.</span>fit<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">.</span>rsquared <span class="token keyword">return</span> <span class="token number">1</span><span class="token punctuation">.</span> <span class="token operator">/</span> <span class="token punctuation">(</span><span class="token number">1</span><span class="token punctuation">.</span> <span class="token operator">-</span> r2<span class="token punctuation">)</span>
exog = train[candidates].drop(['bad_ind', 'bankruptcy_ind'], axis=1)for i in exog.columns:print(i, '\t', vif(df=exog, col_i=i))
fico_score 1.542313308954432
tot_derog 1.347832436613074
age_oldest_tr 1.1399926313381807
rev_util 1.0843803200842592
ltv 1.0246247922768867
veh_mileage 1.0105135995489778
预测
train['proba'] = lg_m1.predict(train)
test['proba'] = lg_m1.predict(test)
test[‘proba’].head()
4 0.123459
6 0.002545
10 0.071279
11 0.219843
13 0.241252
Name: proba, dtype: float64
模型评估
设定阈值
test['prediction'] = (test['proba'] > 0.5).astype('int')
混淆矩阵
pd.crosstab(test.bad_ind, test.prediction, margins=True)
| prediction | 0 | 1 | All |
|---|---|---|---|
| bad_ind | |||
| 0 | 969 | 33 | 1002 |
| 1 | 199 | 30 | 229 |
| All | 1168 | 63 | 1231 |
- 计算准确率
acc = sum(test['prediction'] == test['bad_ind']) /np.float(len(test))
print('The accurancy is %.2f' %acc)
The accurancy is 0.81
for i in np.arange(0, 1, 0.1):prediction = (test['proba'] > i).astype('int')confusion_matrix = pd.crosstab(test.bad_ind, prediction,margins = True)precision = confusion_matrix.iloc[1, 1] /confusion_matrix.loc['All', 1]recall = confusion_matrix.iloc[1, 1] / confusion_matrix.loc[1, 'All']f1_score = 2 * (precision * recall) / (precision + recall)print('threshold: %s, precision: %.2f, recall:%.2f , f1_score:%.2f'\%(i, precision, recall, f1_score))
threshold: 0.0, precision: 0.19, recall:1.00 , f1_score:0.31
threshold: 0.1, precision: 0.26, recall:0.92 , f1_score:0.41
threshold: 0.2, precision: 0.34, recall:0.70 , f1_score:0.46
threshold: 0.30000000000000004, precision: 0.41, recall:0.46 , f1_score:0.43
threshold: 0.4, precision: 0.45, recall:0.25 , f1_score:0.32
threshold: 0.5, precision: 0.48, recall:0.13 , f1_score:0.21
threshold: 0.6000000000000001, precision: 0.50, recall:0.05 , f1_score:0.09
threshold: 0.7000000000000001, precision: 0.67, recall:0.02 , f1_score:0.03
threshold: 0.8, precision: 0.50, recall:0.00 , f1_score:0.01
threshold: 0.9, precision: 0.50, recall:0.00 , f1_score:0.01
- 绘制ROC曲线
import sklearn.metrics as metrics
fpr_test, tpr_test, th_test = metrics.roc_curve(test.bad_ind, test.proba)
fpr_train, tpr_train, th_train = metrics.roc_curve(
train.bad_ind, train.proba)
plt.figure(figsize=[3, 3])
plt.plot(fpr_test, tpr_test, ‘b–’)
plt.plot(fpr_train, tpr_train, ‘r-’)
plt.title(‘ROC curve’)
plt.show()
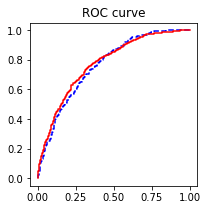
print('AUC = %.4f' %metrics.auc(fpr_test, tpr_test))
AUC = 0.7619
print(metrics.classification_report(test.bad_ind, test.prediction)) # 计算评估指标
precision recall f1-score support0 0.83 0.97 0.89 10021 0.48 0.13 0.21 229
avg / total 0.76 0.81 0.77 1231
statsmodel会默认进行标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
cols = [‘fico_score’ ,‘ltv’ ,‘age_oldest_tr’ ,‘tot_derog’]
train1 = train[cols]; test1 = test[cols]
train2 = pd.DataFrame(scaler.fit_transform(train1), columns=cols, index=train1.index)
test2 = pd.DataFrame(scaler.transform(test1), columns=cols, index = test1.index)
train3 = train2.join(train.bad_ind).join(train.bankruptcy_ind)
test3 = test2.join(test.bad_ind).join(test.bankruptcy_ind)
formula2 = ‘bad_ind ~’ + ‘+’.join(cols) + ‘+ bankruptcy_ind’
lg_m2 = smf.glm(formula=formula2, data=train3,
family=sm.families.Binomial(sm.families.links.logit)).fit()
# formula2
train3[‘proba’] = lg_m2.predict(train3)
test3[‘proba’] =lg_m2.predict(test3)
fpr_test, tpr_test, th_test = metrics.roc_curve(test3.bad_ind, test3.proba)
fpr_train, tpr_train, th_train = metrics.roc_curve(
train3.bad_ind, train3.proba)
plt.figure(figsize=[6, 6])
plt.plot(fpr_test, tpr_test, ‘b-’)
plt.plot(fpr_train, tpr_train, ‘r-’)
plt.title(‘ROC curve’)
print(‘AUC = %.4f’ %metrics.auc(fpr_test, tpr_test))
test3[‘prediction’] = (test3[‘proba’] > 0.5).astype(‘int’)
pd.crosstab(test3.bad_ind, test3.prediction, margins=True)
AUC = 0.7614
| prediction | 0 | 1 | All |
|---|---|---|---|
| bad_ind | |||
| 0 | 971 | 31 | 1002 |
| 1 | 198 | 31 | 229 |
| All | 1169 | 62 | 1231 |

这篇关于汽车贷款违约预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









