本文主要是介绍神经网络从小白到入门:一、从波士顿房价问题切入TF神经网络:KNN算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文中的波士顿房价问题所需数据,在晚上是公共资源,将该数据存储到网盘中,分享就不存放到CSDN上了,CSDN的收费过于离谱
链接:https://pan.baidu.com/s/1VGDAzZpPLLSCALgscNbZ1A
提取码:tg5n
以下为波士顿房价数据中的各个字段信息说明
- CRIM–城镇人均犯罪率
- ZN - 占地面积超过25,000平方英尺的住宅用地比例。
- INDUS - 每个城镇非零售业务的比例。
- CHAS - Charles River虚拟变量(如果是河道,则为1;否则为0)
- NOX - 一氧化氮浓度(每千万份)
- RM - 每间住宅的平均房间数
- AGE - 1940年以前建造的自住单位比例
- DIS加权距离波士顿的五个就业中心
- RAD - 径向高速公路的可达性指数
- TAX - 每10,000美元的全额物业税率
- PTRATIO - 城镇的学生与教师比例
- B - 1000(Bk - 0.63)^ 2其中Bk是城镇黑人的比例
- LSTAT - 人口状况下降%
- MEDV - 自有住房的中位数报价, 单位1000美元
亦或者使用包自带的数据,如下:
from sklearn.datasets import load_boston
dataset=load_boston()print(dataset)
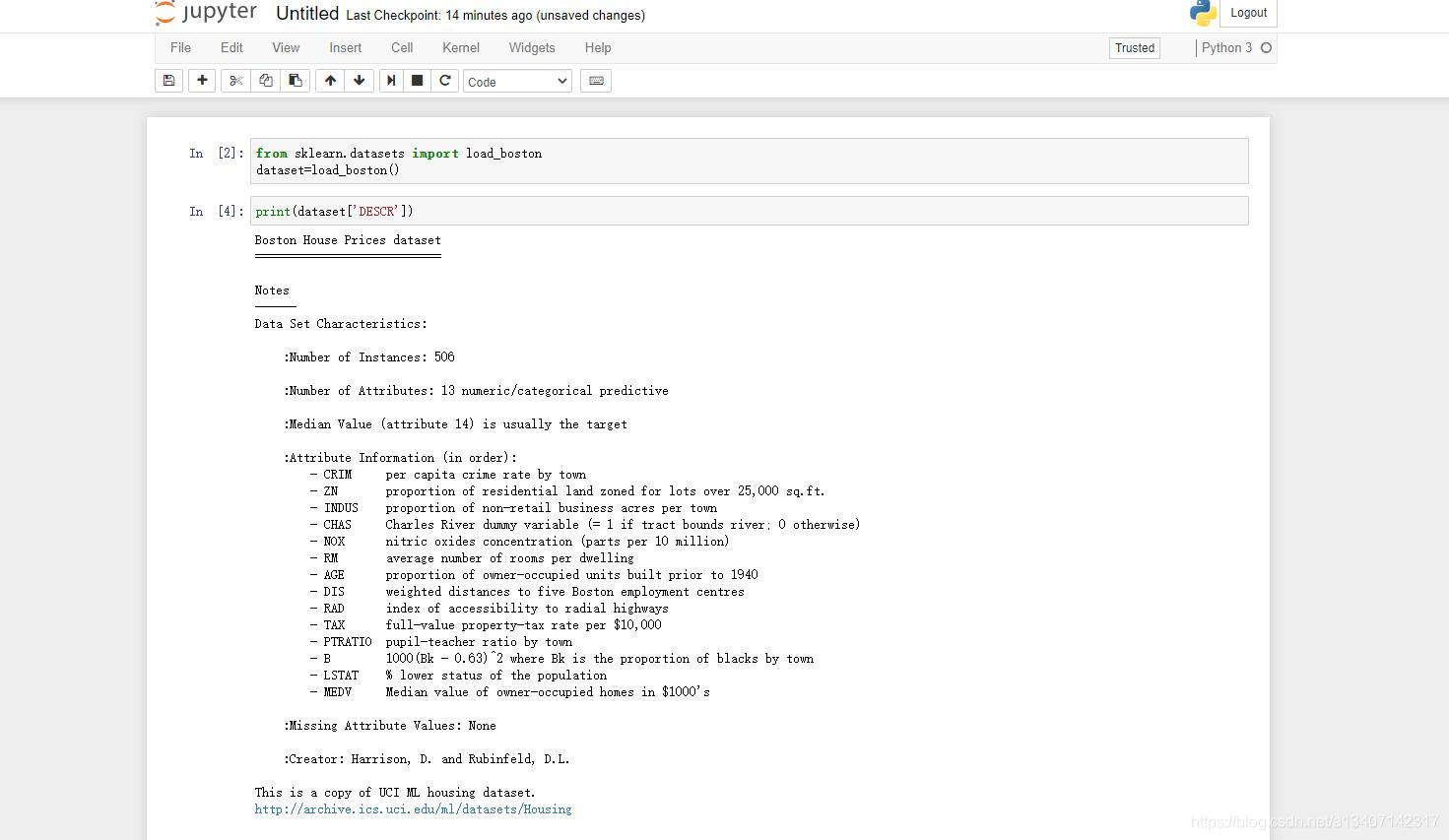
将上面的信息再粘贴一次,描述以下波士顿数据字段的说明信息
- CRIM–城镇人均犯罪率
- ZN - 占地面积超过25,000平方英尺的住宅用地比例。
- INDUS - 每个城镇非零售业务的比例。
- CHAS - Charles River虚拟变量(如果是河道,则为1;否则为0)
- NOX - 一氧化氮浓度(每千万份)
- RM - 每间住宅的平均房间数
- AGE - 1940年以前建造的自住单位比例
- DIS加权距离波士顿的五个就业中心
- RAD - 径向高速公路的可达性指数
- TAX - 每10,000美元的全额物业税率
- PTRATIO - 城镇的学生与教师比例
- B - 1000(Bk - 0.63)^ 2其中Bk是城镇黑人的比例
- LSTAT - 人口状况下降%
- MEDV - 自有住房的中位数报价, 单位1000美元
1. 预测房价
首先我们基于上述波士顿数据,来预测房价,由于波士顿数据具有多个维度,且上述的维度过多,故我们将暂时只基于影响最为明显的维度来预测
1.1 使用pandas来加载和分析数据。
有时间我来总结以下pandas工具包,一直帮别人看代码,看书中有很多重要的都是介绍pandas的,但是一直没有系统的总结,后续有时间我来梳理以下pandas工具包,现在我们使用pandas包来辅助分析我们的波士顿数据。
- 加载数据
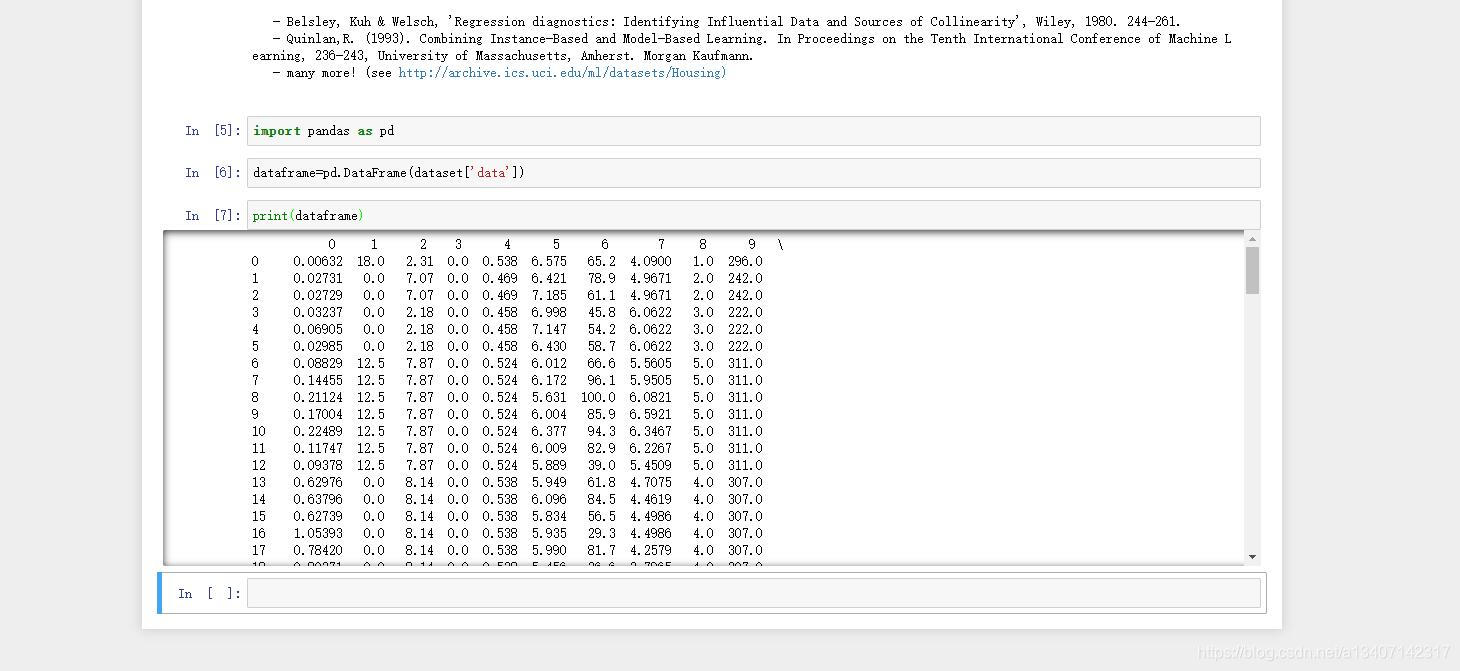
import pandas as pd
dataframe=pd.DataFrame(dataset['data'])print(dataframe)
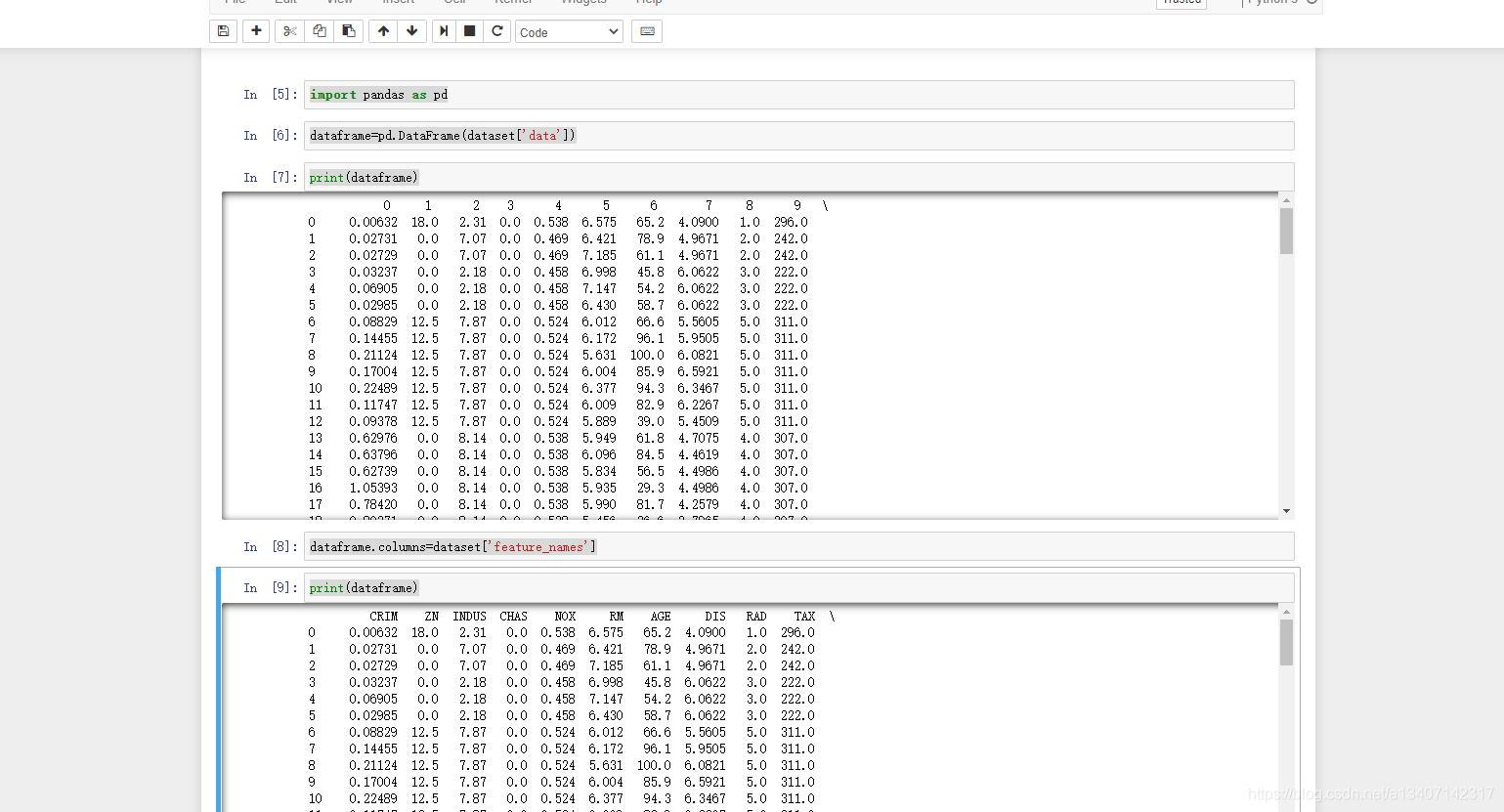
- 修改字段别名
dataframe.columns=dataset['feature_names']
print(dataframe)
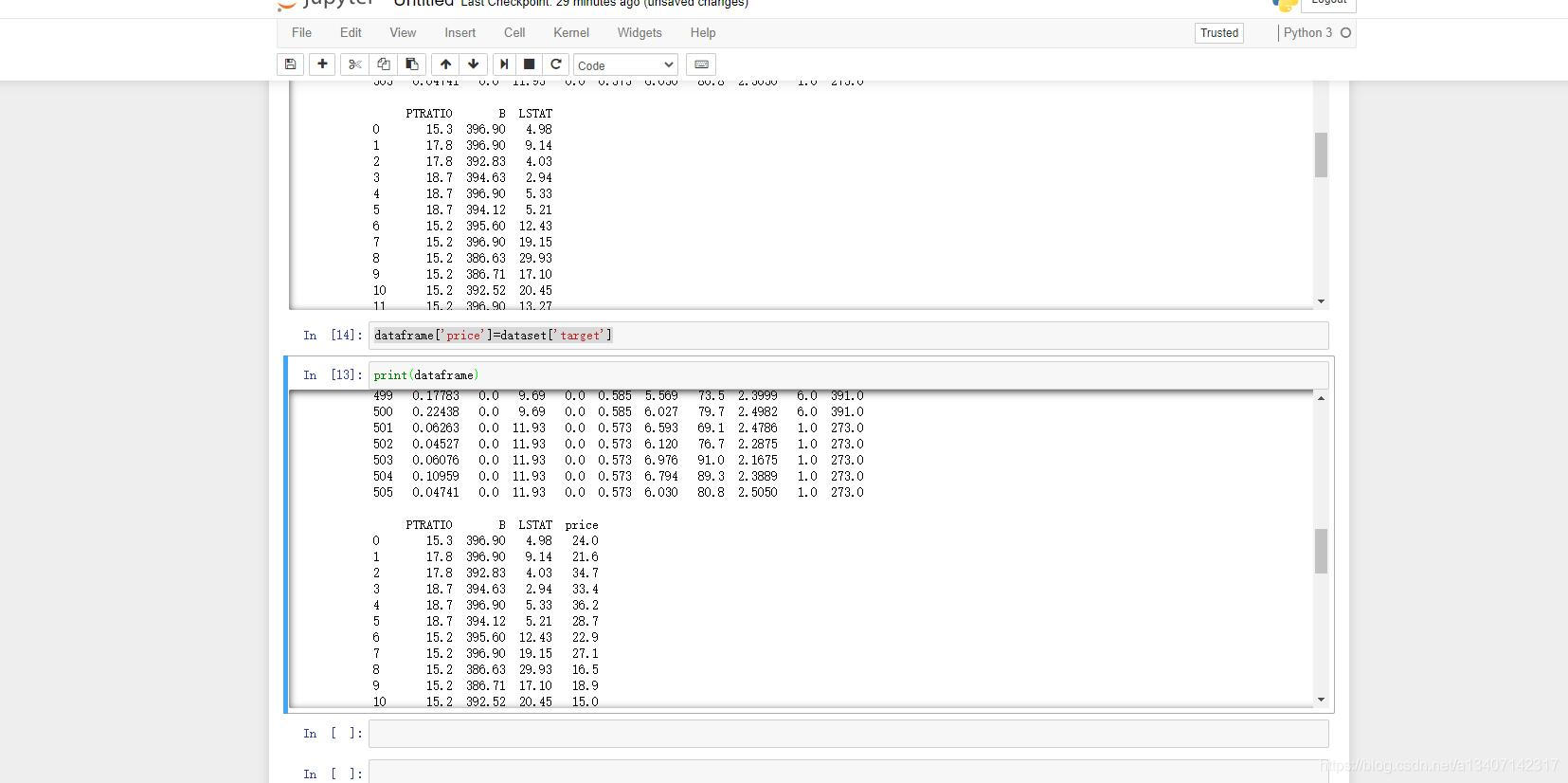
- 联合数据的价格
dataframe['price']=dataset['target']
print(dataframe)
- 分析对房价影响最大的显著特征是什么?
即分析数据中各个维度中对于房价的影响是最大的维度是什么?
以下使用的方式是采用手工的方式确定的,在大数据和人工智能中存在一定的算法做到自动推算出对房价影响最大的显著特征,由于此处是一个切入点话题,故在此将问题简单化
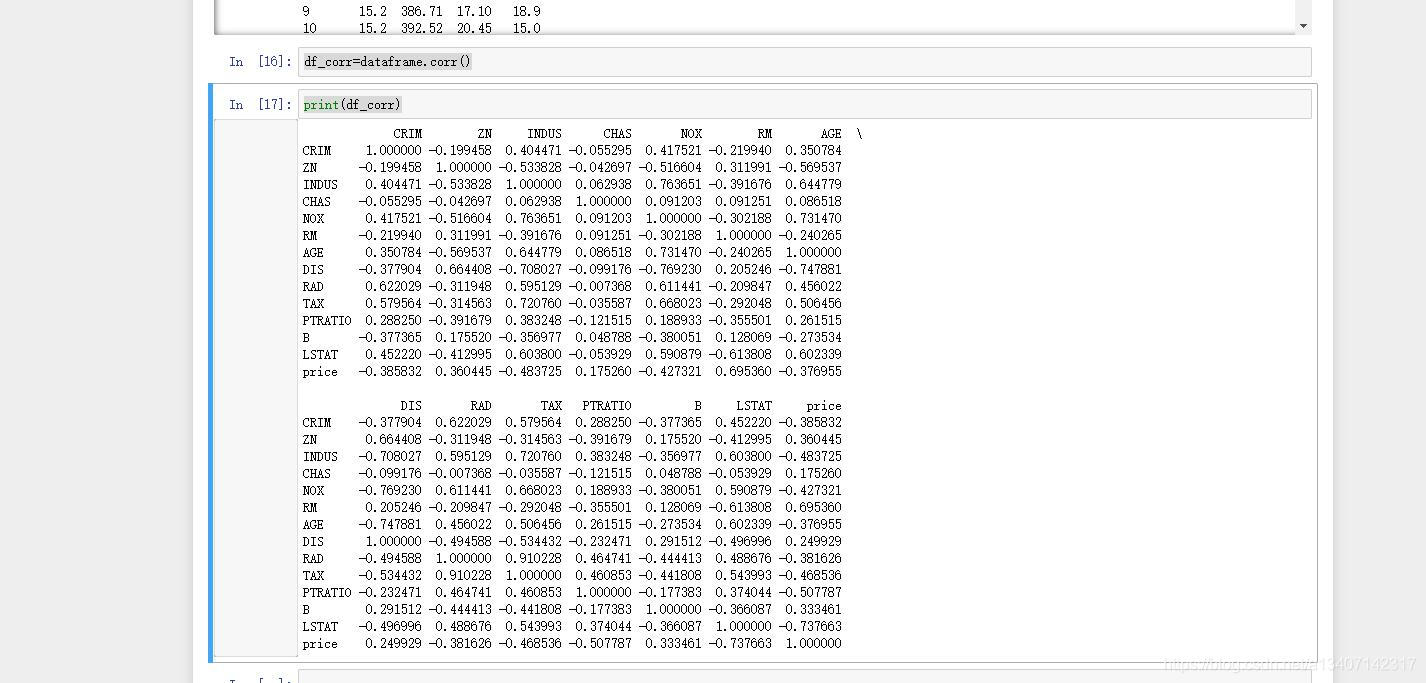
4.1 获取房价中的显著特征矩阵
df_corr=dataframe.corr()
print(df_corr)
4.2 使用matplotlib包显示特征举证
%matplotlib inline
import seaborn as snssns.heatmap(dataframe.corr(),annot=True,fmt='.1f')
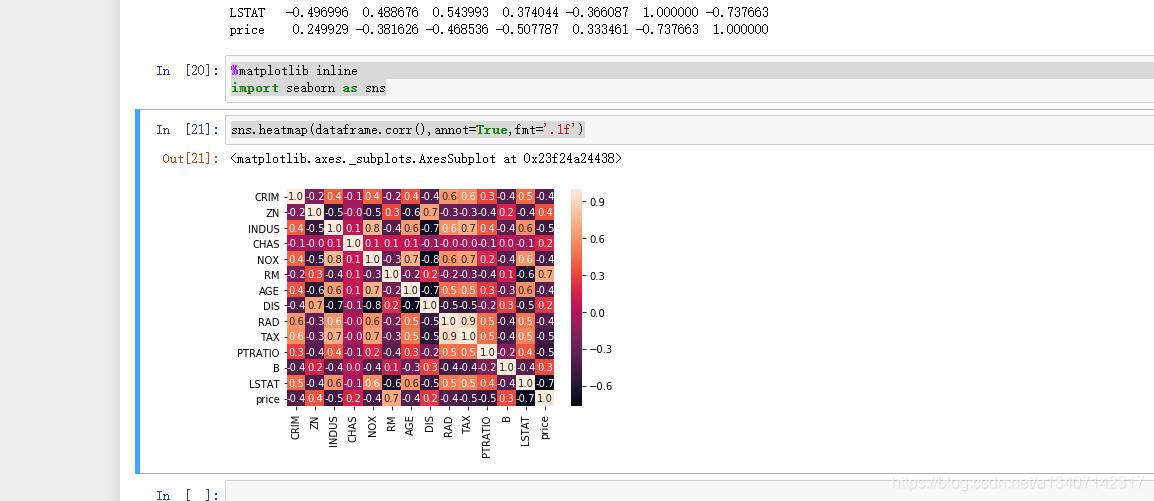
- 确认在特征矩阵中[RM - 每间住宅的平均房间数]是房价的显著特征
在4的分析中我们发现卧室的个数与房屋价格成正相关
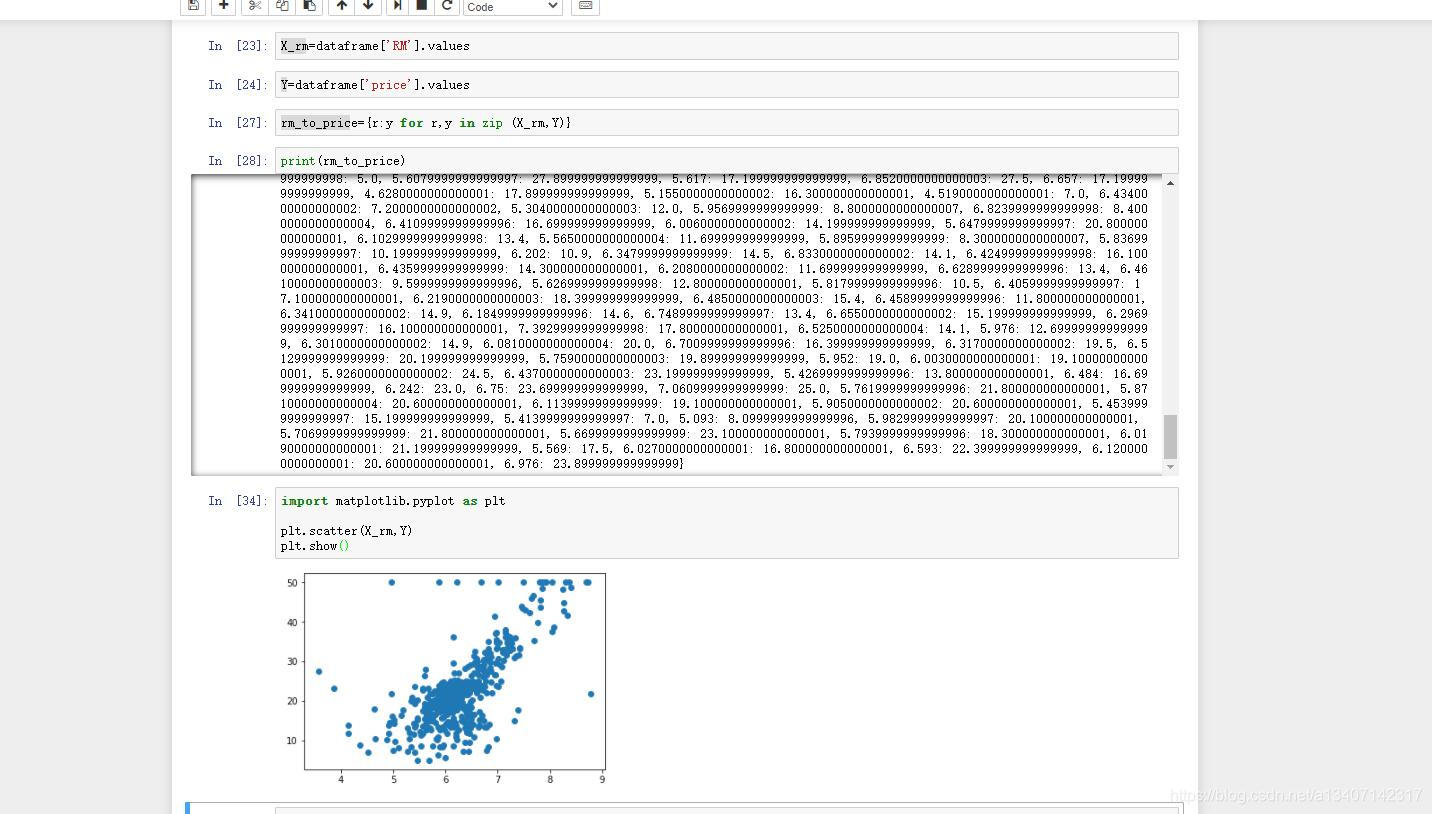
- 输出RM与房价的关系
X_rm=dataframe['RM'].values
Y=dataframe['price'].values
rm_to_price={r:y for r,y in zip (X_rm,Y)}
print(rm_to_price)
import matplotlib.pyplot as pltplt.scatter(X_rm,Y)
plt.show()
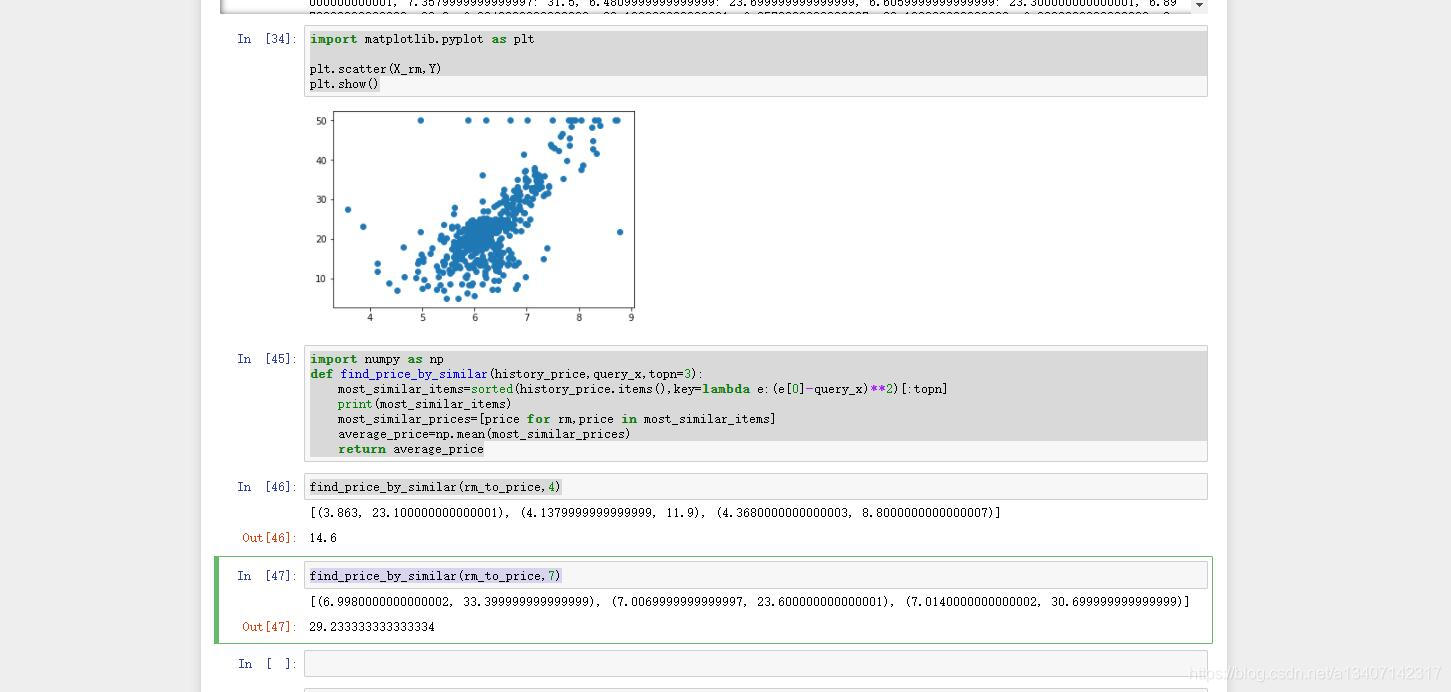
- 传统分析方法
当需要咨询房价是,输入RM信息,在上述的对应关系中查找,如果有则返回该信息,如果没有则返回该RM信息的相关信息值得算式值
import numpy as np
def find_price_by_similar(history_price,query_x,topn=3):most_similar_items=sorted(history_price.items(),key=lambda e:(e[0]-query_x)**2)[:topn]print(most_similar_items)most_similar_prices=[price for rm,price in most_similar_items]average_price=np.mean(most_similar_prices)return average_pricefind_price_by_similar(rm_to_price,4)find_price_by_similar(rm_to_price,7)
代码是给人看的,只是偶尔给机器运行一下
这篇关于神经网络从小白到入门:一、从波士顿房价问题切入TF神经网络:KNN算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









