本文主要是介绍加权准确率WA,未加权平均召回率UAR和未加权UF1,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
加权准确率WA,未加权平均召回率UAR和未加权UF1
- 1.加权准确率WA,未加权平均召回率UAR和未加权UF1
- 2.参考链接
1.加权准确率WA,未加权平均召回率UAR和未加权UF1
from sklearn.metrics import classification_report
from sklearn.metrics import precision_recall_curve, average_precision_score,roc_curve, auc, precision_score, recall_score, f1_score, confusion_matrix, accuracy_scoreimport torch
from torchmetrics import MetricTracker, F1Score, Accuracy, Recall, Precision, Specificity, ConfusionMatrix
import warnings
warnings.filterwarnings("ignore") # 忽略告警pred_list = [2, 0, 4, 1, 4, 2, 4, 2, 2, 0, 4, 1, 4, 2, 2, 0, 4, 1, 4, 2, 4, 2]
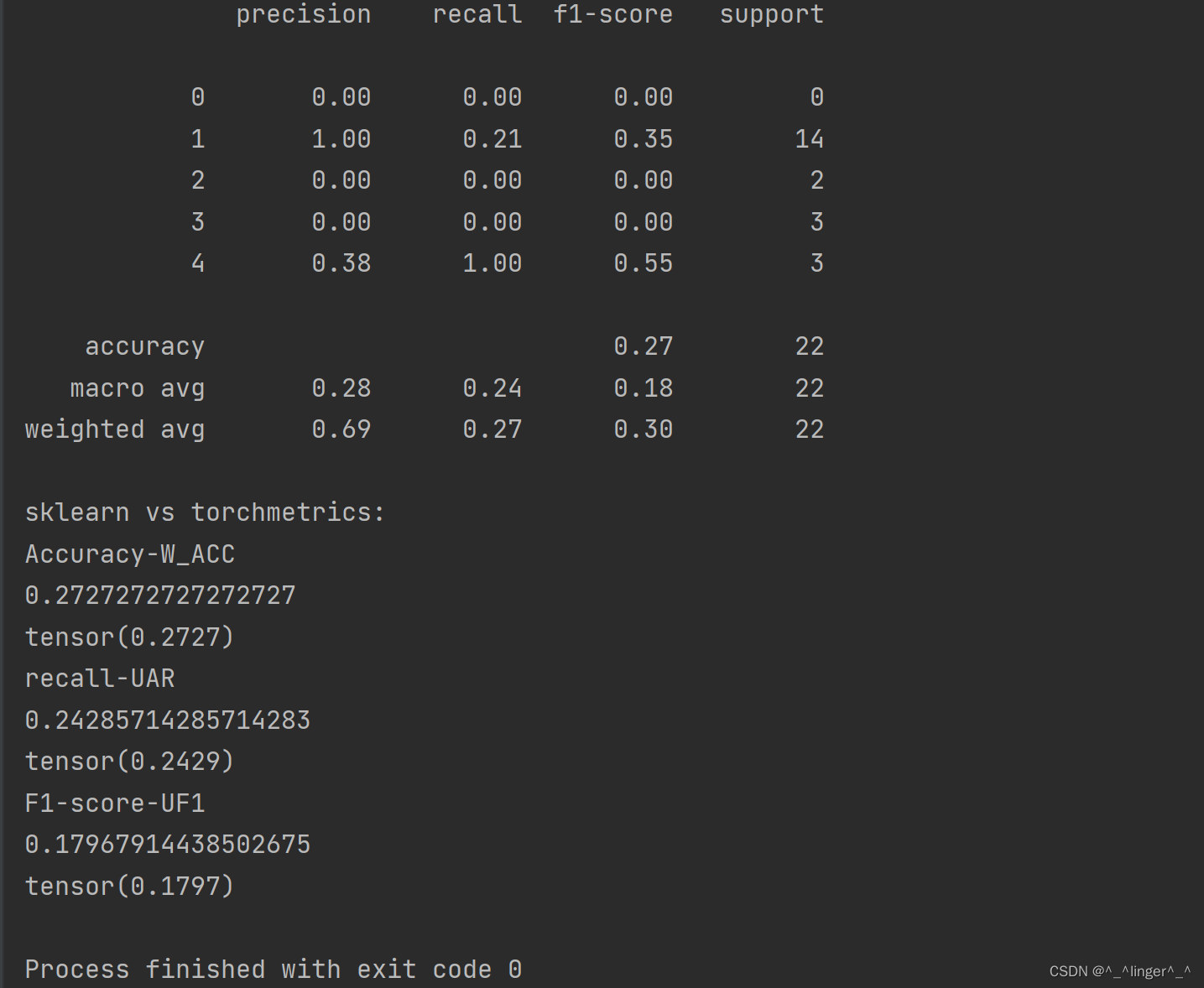
target_list = [1, 1, 4, 1, 3, 1, 2, 1, 1, 1, 4, 1, 3, 1, 1, 1, 4, 1, 3, 1, 2, 1]print(classification_report(target_list, pred_list))# Accuracy # WA(weighted accuracy)加权准确率,其实就是我们sklearn日常跑代码出来的acc
# 在多分类问题中,加权准确率(Weighted Accuracy)是一种考虑每个类别样本数量的准确率计算方式。
# 对于样本不均衡的情况,该方式比较适用。其计算方式是将每个类别的准确率乘以该类别在总样本中的比例(权重),然后求和。
test_acc_en = Accuracy(task="multiclass",num_classes=5, threshold=1. / 5, average="weighted")# Recall macro表示加权的
# UAR(unweighted average recall)未加权平均召回率
# 是一种性能评估指标,主要用于多分类问题。它表示各类别的平均召回率(Recall),在计算时,不对各类别进行加权。对于每个类别,召回率是该类别中真正被正确预测的样本数与该类别中所有样本数的比值。
# UAR在评估一个分类器时,对每个类别都给予相同的重要性,而不考虑各类别的样本数量。这使得UAR在处理不平衡数据集时具有一定的优势,因为它不会受到数量较多的类别的影响。
test_rcl_en = Recall(task="multiclass",num_classes=5, threshold=1. / 5, average="macro") # UAR# F1 score
# F1分数是精确率(Precision)和召回率(Recall)的调和平均值。
# 在多分类问题中,通常会计算每个类别的F1分数,然后取平均值作为总体的F1分数。
# 平均方法可以是简单的算术平均(Macro-F1)(常用),也可以是根据每个类别的样本数量进行加权的平均(Weighted-F1)
test_f1_en = F1Score(task="multiclass", num_classes=5, threshold=1. / 5, average="macro") # UF1preds = torch.tensor(pred_list)
target = torch.tensor(target_list)
print("sklearn vs torchmetrics: ")
print("Accuracy-W_ACC")
print(accuracy_score(y_true=target_list, y_pred=pred_list))
print(test_acc_en(preds, target))print("recall-UAR")
print(recall_score(y_true=target_list,y_pred=pred_list,average='macro')) # 也可以指定micro模式
print(test_rcl_en(preds, target))print("F1-score-UF1")
print(f1_score(y_true=target_list, y_pred=pred_list, average='macro'))
print(test_f1_en(preds, target))
2.参考链接
- 一文看懂机器学习指标:准确率、精准率、召回率、F1、ROC曲线、AUC曲线
- 多分类中TP/TN/FP/FN的计算
- 多分类中混淆矩阵的TP,TN,FN,FP计算
- TP、TN、FP、FN超级详细解析
- 一分钟看懂深度学习中的准确率(Accuracy)、精度(Precision)、召回率(Recall)和 mAP
- 深度学习评价指标简要综述
- 深度学习 数据多分类准确度 多分类的准确率计算
- Sklearn和TorchMetrics计算F1、准确率(Accuracy)、召回率(Recall)、精确率(Precision)、敏感性(Sensitivity)、特异性(Specificity)
这篇关于加权准确率WA,未加权平均召回率UAR和未加权UF1的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







