本文主要是介绍PostgreSQL向量数据插件--pgvector安装(附PostgreSQL安装),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
PostgreSQL向量数据插件--pgvector安装
- 一、版本
- 二、数据库安装
- 1. 在官网下载PostgreSQL14.0的安装包
- 2.增加用户postgres
- 3.解压安装
- 三、pgvector安装
- 1. 从github上克隆下来
- 2. 安装pgvector插件
- 3. 开始使用pgvector
- 启用pgsql命令行
- 创建扩展
本文为本人在安装pgvector中踩过的坑,已找到解决方法,现向大家分享。
一、版本
- pgvector:0.5.1
- PostgreSQL数据库:14.0
- 操作系统:Ubuntu18.04
二、数据库安装
因为在此之前安装过PostgreSQL8.4.1,而pgvector只只支持11.0及以后的版本,因此安装PostgreSQL14.0
1. 在官网下载PostgreSQL14.0的安装包
PostgreSQL官网

2.增加用户postgres
adduser postgres
3.解压安装
解压压缩包
tar zxvf postgresql-14.0.tar.gz
安装依赖包
sudo apt-get install gcc
sudo apt-get install g++
sudo apt-get install make
sudo apt install libreadline-dev
sudo apt-get install zlib1g-dev
编译
cd postgresql-14.0
./configure --prefix=/usr/local/pgsql --enable-debug
sudo make && sudo make install
cd contrib #插件
sudo make && sudo make install
数据目录创建
sudo mkdir -p /var/postgresql/data
chown postgres:postgres /var/postgresql -R
chown postgres:postgres /usr/local/pgsql -R
切换用户
su postgres
环境变量设置
vi ~/.bash_profile
在~/.bash_profile中写入:
export PGHOME=/usr/local/pgsql
export PGDATA=/var/postgresql/data
export PATH=$PGHOME/bin:$PATH
export MANPATH=$PGHOME/share/man:$MANPATH
export LANG=en_US.utf8
export DATE=`date +"%Y-%m-%d %H:%M:%S"`
export LD_LIBRARY_PATH=$PGHOME/lib:$LD_LIBRARY_PATH
alias rm='rm -i'
alias ll='ls -lh'
#alias pg_start='pg_ctl start -D $PGDATA'
#alias pg_stop='pg_ctl stop -D $PGDATA -m fast'
初始化数据库
initdb -D /var/postgresql/data
连接数据库服务
pg_ctl -D /var/postgresql/data start
三、pgvector安装
github上的pgvector
1. 从github上克隆下来
首先要安装git,详细可参考:安装Git
cd /tmp
git clone --branch v0.5.1 https://github.com/pgvector/pgvector.git
此时可能会遇到拒绝连接

等待即可,因为可能是网络不好。。
2. 安装pgvector插件
cd pgvector/
make && sudo make install
此时可能会遇到Makefile:48: /usr/lib/postgresql/10/lib/pgxs/src/makefiles/pgxs.mk: 没有那个文件或目录
make: *** 没有规则可制作目标“/usr/lib/postgresql/10/lib/pgxs/src/makefiles/pgxs.mk”。 停止。

这是因为环境配置没有配置好,查看pg_config在哪
which pg_config

可以看到我的pg_config的绝对地址,但其实它应该在==/usr/local/pgsql/bin/pg_config==
所以以下有两种方法可以解决:
- 在命令行export设置临时环境变量
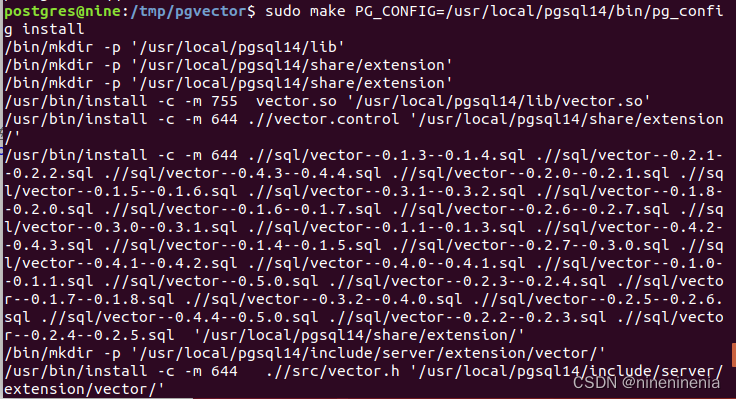
sudo make PG_CONFIG=/usr/local/pgsql14/bin/pg_config
sudo make PG_CONFIG=/usr/local/pgsql14/bin/pg_config install
- 在~/.bash_profile修改环境变量
vi ~/.bash_profile
在文件内加入
export PG_CONFIG=/usr/local/pgsql/bin/pg_config
安装成功如图
3. 开始使用pgvector
启用pgsql命令行
psql
或
pgsql
创建扩展
CREATE EXTENSION vector;
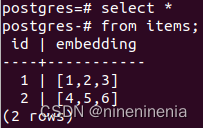
CREATE TABLE items (id bigserial PRIMARY KEY, embedding vector(3));
INSERT INTO items (embedding) VALUES ('[1,2,3]'), ('[4,5,6]');
此处有一个特别提醒,不是pgvector,而是vector
运行CREATE成功后

查看items表
这篇关于PostgreSQL向量数据插件--pgvector安装(附PostgreSQL安装)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






