本文主要是介绍Ai 算法之Transformer 模型的实现: 一 、Input Embedding模块和Positional Embedding模块的实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一 文章生成模型简介
比较常见的文章生成模型有以下几种:
- RNN:循环神经网络。可以处理长度变化的序列数据,比如自然语言文本。RNN通过隐藏层中的循环结构来传递时间序列中的信息,从而使当前的计算可以参照之前的信息。但这种模型有梯度爆炸和梯度消失的风险,所以只能做简单的生成任务。
- LSTM:长短记忆网络。通过引入门控制机制来控制信息传递。有效避免了梯度消失和梯度保障的问题。LSTM可以做些复杂的生成任务。
- Transformer:目前最火的,一种基于自注意力机制(self-attention mechanism)的神经网络模型。Transformer 和 以上所述的几个生成模型主要的区别是,RNN、LSTM的训练迭代是串行的,必须要处理完当前字才可以处理下一个。而 Transformer 所有字符是同时训练的,也就是并行的。因此它效率更高,同样,由于参考了全文位置信息,因此效果更好。
值得一提的是这几个模型的价值并不仅限于在文章生成中。所有需要"经验值"的应用场景应该都适合借鉴。比如19年我曾尝试用LSTM来实现物联网小车自动驾驶。将操作指令转换为文字编码,实现了自动巡航、避障、撞墙倒车等操作。效果还不错。相信更换为注意力机制效果会更好
本文无意重塑轮子,纯是基于兴趣学习,尝试复现模型构造过程,本文所使用环境为python3.9+pytorch,参考论文为Google的Attention Is All You Need 2017。欢迎骚扰探讨
关于RNN和LSTM的实现代码,请查看我博客中的相关文章
1.1 Transformer 结构图
左侧为外国原版,右侧为在下翻译版

Transformer 模型主要分为两大部分,分别是 Encoder 、 Decoder,即组码器和解码器。组码器负责把输入语言序列映射成隐藏层,然后解码器再把隐藏层映射为其他自然语言序列。在原文中解码器和编码器都被设为6层(N = 6)。据说这个6没有特殊的含义。只是根据经验平衡了训练和精度的尝试数字。
在输入语句进入组码器前需要对数据进行预处理。这就是本章的主要内容:Embedding模块的实现
二 Input Embedding 字符编码模块的实现
字符编码本质上就相当于映射,将现实中的物体用数学的方式映射到计算机中。以翻译任务为例,我们需要准备两种不同的语言数据,并使用索引将他们一一对应。比如英文字符[i, eat, shit], 中文[我,吃,屎],这就相当于我们知道了问题和答案,剩下的就是训练隐藏层的参数了。
在npl中,为了使字符可以计算,首先要先将输入的词汇进行数学转化。在比较在其的语言处理中,一般使用one hot(独热)编码。即指定一个表值范围数组,单独改变某个位置上的值来决定其特征。
独热编码示例:
[1,0 ,0 ,0] = 我
[0,1 ,0 ,0] = 吃
[0,0, 1 ,0] = 屎
独热编码简单清晰,但无法对比两个值之间的相似性,无法进行降维操作。所以在tranfomer中 使用多维向量来表示单词的编码信息。一个向量表示一个单词。多个单词在一起就是一个矩阵。相比较以前的独热编码,词向量可以便于计算单词之间的相似性(点积),也可以进行降维操作。
单词向量示例:
[11,23,31,32]
[23,21,31,23]
[13,32,33,93]
单词的 Embedding 有很多种方式可以获取,例如可以采用 Word2Vec、Glove 等算法预训练得到,也可以在 Transformer 中训练得到。以下是使用pythoch获取Embedding向量的代码脚本,复制可用。
import torch
import torch.nn as nn# padding:当句子长度不一,有空白时用0补缺
embedding = nn.Embedding(单词数量, 向量维度,padding=0)
# 根据索引获取8个单词向量
input = torch.LongTensor([[1, 2, 3, 4], [11, 12, 13, 13]])
print(embedding(input))
print(embedding(input).shape)
三 Positional Embedding 位置编码模块的实现
位置编码模块负责将输入序列中的位置信息写入词向量,输入到transformer中的句子没有顺序信息,因此需要通过计算句子的长度,单词长度以及单词所在的位置通过编码来为输入系列添加位置信息。Tranformer原文作者使用的是正弦余弦编码
位置 Embedding 用 PE表示,PE 的维度与单词 Embedding 是一样的。PE 可以通过训练得到,也可以使用某种公式计算得到。在 Transformer 中采用了后者,计算公式如下:
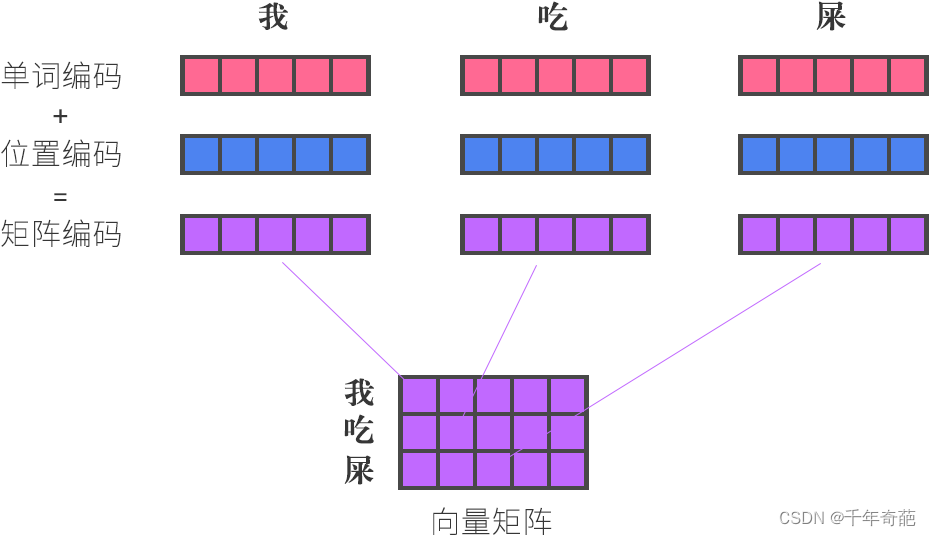
那么单词向量是怎么得来的呢?
单词向量 = 原始单词编码 + 单词位置编码
举个例子:我吃屎 = i eat shit
位置编码计算公式
偶数索引: P E ( p o s , 2 i ) = s i n ( p o s / 1000 0 2 i / d ) 偶数索引:PE(pos,2i)=sin(pos/10000^2i/d) 偶数索引:PE(pos,2i)=sin(pos/100002i/d)
单数索引: P E ( p o s , 2 i ) = c o s ( p o s / 1000 0 2 i / d ) 单数索引:PE(pos,2i)=cos(pos/10000^2i/d) 单数索引:PE(pos,2i)=cos(pos/100002i/d)
import torch
import torch.nn as nn
import ludash as ld
import cv2
import seaborn
import matplotlib.pyplot as pltterm = (10000**2/i)
pe[:, 0::2] = torch.sin(position * term )
pe[:, 1::2] = torch.cos(position * term )四 获取预处理数据
获取到字符编码和位置编码后,就可以计算出参考了字符位置的权重矩阵
公式: [ q , k , v ] = ( I n p u t E m b e d d i n g + p o s i t i o n a l E m b e d d i n g ) ∗ [ W q , W k , W v ] 公式: [q, k, v] =(Input Embedding + positional Embedding)* [Wq, Wk, Wv] 公式:[q,k,v]=(InputEmbedding+positionalEmbedding)∗[Wq,Wk,Wv]
q = 查询向量, k = 键值向量, v = 值向量 q = 查询向量,k = 键值向量,v = 值向量 q=查询向量,k=键值向量,v=值向量
取得这个值后就可以进行下一步:传入Transfrom的组码器进行组码处理了。
这篇关于Ai 算法之Transformer 模型的实现: 一 、Input Embedding模块和Positional Embedding模块的实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




