本文主要是介绍Keil 编译输出信息分析:Program size: Code, RO-data , RW-data, ZI-data,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
 一般 MCU 包含的存储空间有:片内 Flash 与片内 RAM,RAM 相当于内存,Flash 相当于硬盘。编译器会将一个程序分类为好几个部分,分别存储在 MCU 不同的存储区。
一般 MCU 包含的存储空间有:片内 Flash 与片内 RAM,RAM 相当于内存,Flash 相当于硬盘。编译器会将一个程序分类为好几个部分,分别存储在 MCU 不同的存储区。
如图所示,在Keil中编译工程成功后,在下面的Bulid Ouput窗口中会输出下面这样一段信息
Program Size: Code=28866 RO-data=958 RW-data=240 ZI-data=34224
一、这一串字符含义
答:这是keil编译程序后,打印这个程序对应的内存分配信息。
Code:是指 程序所占用的ROM大小,存储在FLASH,程序运行期间 不变,单位为字节(B),28866 B
RO-data:read only,只读常量, 程序中所定义的指令和常量占空间的大小,程序运行期间 不变,如const型,存储在FLASH中。单位为字节(B),958 B
RW-data:read/write,可读可写变量, 已被初始化的可读写变量占空间的大小,存储在FLASH中。程序运行期间 会变,初始化时RW-data从flash拷贝到SRAM。单位为字节(B),240 B
ZI-data:zero initialize, 没有被初始化的可读写变量占空间的大小,就是 程序中用到的变量并且被系统初始化为0的变量的字节数,存储在SRAM中。keil编译器默认把你没有初始化的变量都赋予一个0,这些变量在程序运行时是保存在RAM中的。程序运行期间 会变。单位为字节(B), 34224 B简而言之
1)Code:代码段,存放程序的代码部分;
2)RO-data:只读数据段,存放程序中定义的常量;
3)RW-data:读写数据段,存放初始化为非 0 值的全局变量;
4)ZI-data:0 数据段,存放未初始化的全局变量及初始化为 0 的变量;
二、代码存储位置
答:简单的说就是,在烧写的时候是FLASH( ROM)中的被占用的空间为: Code+RO Data+RW Data
程序运行的时候,芯片内部 RAM使用的空间为: RW Data + ZI Data
一、为什么ROM还要存RW?
答:因为掉电后RAM中的所有数据都丢失了,每次上电RAM中的数据都被重新赋值, 每次这些固定的值就是存储在ROM中的。
二、为什么不包含ZI段呢?
答:是因为ZI 数据都是0,没必要包含,只要程序运行之前将ZI数据所在的区域一律清零即可。包含进去反而浪费存储空间。
三、MCU是怎么样的一个执行过程呢?
答:
①MCU执行过程是 先将RW从ROM中搬到RAM中,因为RW是变量,变量不能存在ROM中。
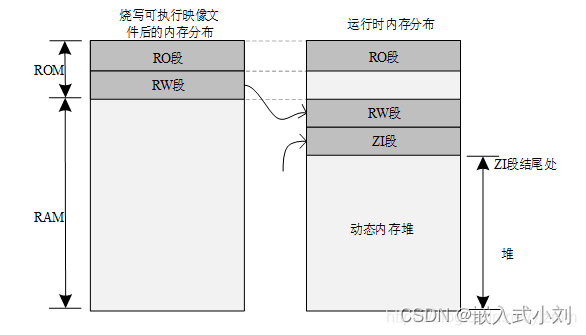
②然后 将ZI所在的RAM区域全部清零,因为ZI区域并不在Image中,所以需要程序根据编译器给出的ZI地址及大小来将相应的RAM区域清零。ZI中也是变量,同理:变量不能存在ROM中。ROM中的指令完成了这两项工作后C程序才能正常访问变量。否则只能运行不含变量的代码。程序运行之前,需要有文件实体被烧录到 STM32 的 Flash 中,一般是 bin 或者 hex 文件,该被烧录文件称为 可执行映像文件。如图左图所示,是可执行映像文件烧录到 STM32 后的内存分布,它包含 RO 段和 RW 段两个部分:其中 RO 段中保存了 Code、RO-data 的数据,RW 段保存了 RW-data 的数据,由于 ZI-data 都是 0,所以未包含在映像文件中。STM32 在上电启动之后 默认从 Flash 启动,启动之后会将 RW 段中的 RW-data(初始化的全局变量)搬运到 RAM 中, 但不会搬运 RO 段,即 CPU 的执行代码从 Flash 中读取,另外根据编译器给出的 ZI 地址和大小分配出 ZI 段,并将这块 RAM 区域清零。其中动态内存堆为未使用的 RAM 空间,应用程序申请和释放的内存块都来自该空间。
参考文章
http://t.csdn.cn/j7fQn
http://t.csdn.cn/Fo6oJ
这篇关于Keil 编译输出信息分析:Program size: Code, RO-data , RW-data, ZI-data的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






