本文主要是介绍SSD在AI发展中的关键作用:从高速缓存到数据湖-2,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
二、大规模长期存储数据湖
-
大规模数据集:
-
-
AI应用需要处理大量的数据,这些数据可能来自多个来源,包括图像、视频、文本、音频等。为了有效地管理这些数据,组织通常将其存储在大型的数据湖中。
-
-
容量扩展:
-
-
由于数据集的不断增长,企业级SSD必须提供大容量存储选项,并且能够轻松扩展以满足未来的需求。全闪存阵列(All-Flash Arrays, AFA)和超融合基础设施(Hyperconverged Infrastructure, HCI)都是应对这一挑战的有效解决方案。
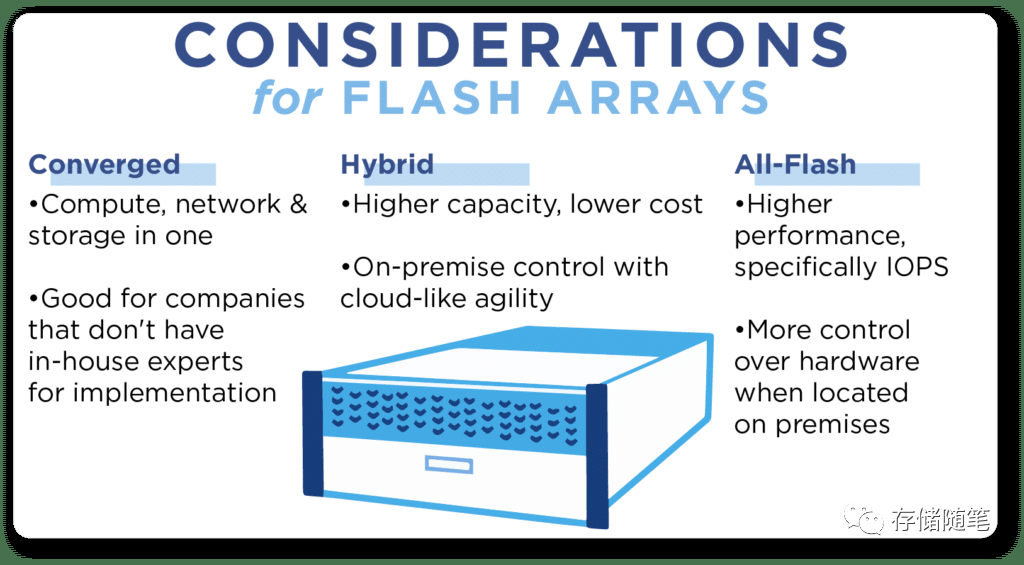
-
-
可靠性与持久性:
-
-
存储系统必须保证数据的完整性和可用性。通过使用RAID(Redundant Array of Independent Disks)、纠删码和其他数据保护机制,企业级SSD确保了数据的可靠存储。
-
三、趋势与展望
-
智能存储:
未来的SSD可能会集成更多的智能化功能,例如基于机器学习的预测性维护、自适应错误纠正以及自动数据优化等。

-
下一代接口与协议
PCIe 5.0/6.0标准将进一步提升SSD的性能,同时新的存储协议如Compute Express Link (CXL) 将使得CPU、GPU和内存之间的通信更为高效。
小编每日撰文不易,如果您看完有所受益,欢迎点击文章底部左下角“关注”并点击“分享”、“在看”,非常感谢!
精彩推荐:
-
浅析不同NAND架构的差异与影响
-
SSD基础架构与NAND IO并发问题探讨
-
字节跳动ZNS SSD应用案例解析
-
SSD数据在写入NAND之前为何要随机化?
-
深度剖析:DMA对PCIe数据传输性能的影响
-
PCIe在狂飙,SAS存储之路还有多远?
-
NAND Vpass对读干扰和IO性能有什么影响?
-
HDD与QLC SSD深度对比:功耗与存储密度的终极较量
-
NVMe SSD:ZNS与FDP对决,你选谁?
-
如何通过优化Read-Retry机制降低SSD读延迟?
-
关于硬盘质量大数据分析的思考
-
存储系统性能优化中IOMMU的作用是什么?
-
全景解析SSD IO QoS性能优化
-
NVMe IO数据传输如何选择PRP or SGL?
-
浅析nvme原子写的应用场景
-
多维度深入剖析QLC SSD硬件延迟的来源
-
浅析PCIe链路LTSSM状态机
-
浅析Relaxed Ordering对PCIe系统稳定性的影响
-
实战篇|浅析MPS对PCIe系统稳定性的影响
-
浅析PCI配置空间
-
浅析PCIe系统性能
-
存储随笔《NVMe专题》大合集及PDF版正式发布!
这篇关于SSD在AI发展中的关键作用:从高速缓存到数据湖-2的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





