高速缓存专题

利用Redis高速缓存实现Tomcat集群在Nginx负载均衡机制下的Session共享
为什么要共享session? 我们使用单台Tomcat的时候不会有共享sesssion的疑虑,只要使用Tomcat的默认配置即可,session即可存储在Tomcat 但是随着业务的扩大,增加Tomcat节点构成Tomcat集群大势所趋,分布式带来了增加更大规模并发请求的优势,但是也随之到来了一个问题,每个Tomcat只存储来访问自己的请求产生的session,如果Tomcat-A已经为客

高速缓存是怎么让CPU找到地址内容的?
这个场景在性能优化下,应该很少会用到。但是还是总结一下。 Input: CPU给的一个地址,例如 0xffads1233423 Out: 这个地址上的值。 WORKFLOW CPU 问高速缓存,高速缓存会拿这个地址的中间几个位置,组成一个key高速缓存拿着这个key去set里面查找,是否有当前的kley false: 高速缓存从L2缓存读取这个地址的信息。同时把这个地址后面的一些位子,也一

OK6410A 开发板 (八) 95 linux-5.11 OK6410A linux高速缓存
高速缓存是什么 存储器在访问(读写)速度上有 金字塔等级架构 高速缓存 其实就是缓存, 高速只是缓存的一个特性(高等级的内存相对于低等级的内存) 缓存 其实 就是 将 低等级存储中的数据 放置到 高等级存储中 可以这么说,高等级存储 就是 低层级存储的缓存 在这里,我们有时候将 缓存 看成一个动词(将 低等级存储中的数据 放置到 高等级存储中 这个动作),有时候也被看成一个名词(高等级存
磁盘缓冲区和页高速缓存的区别
本文转自:linux:磁盘缓冲区和页高速缓存的联系与区别 摘自:http://stackoverflow.com/questions/6345020/linux-memory-buffer-vs-cache 概念上的区别: 1. buffer是块设备的内存读写缓冲区,而page cache是文件系统的概念。 2. A buffer is something that

文件系统专题之 “索引节点高速缓存”
VFS也用了一个高速缓存来加快对索引节点的访问,和块高速缓存不同的一点是每个缓冲区不用再分为两个部分了,因为inode结构中已经有了类似于块高速缓存中缓冲区首部的域。索引节点高速缓存的实现代码全部在fs/inode.c,这部分代码并没有随着内核版本的变化做很多的修改。 1.索引节点链表 每个索引节点可能处于哈希表中,也可能同时处于下列“类型”链表的一种中: ·

Oracle关于高速缓存区应用原理
标签: 缓存oraclesql高速缓存区 2016-03-05 16:09 209人阅读 评论(0) 收藏 举报 分类: Oracle(3) 版权声明:本文为博主原创文章,未经博主允许不得转载。 为什么oracle能够对于大量数据进行访问时候能彰显出更加出色表现,就是通过所谓的高速缓存来实现数据的高速运算与操作。在之前的博文

linux内核原理--页高速缓存,回写,页框回收
1.页高速缓存 我们主要分析下磁盘文件的页高速缓存 struct address_space {struct inode *host; struct radix_tree_root page_tree; spinlock_t tree_lock;unsigned int i_mmap_writable;struct prio_tree_root i_mmap; struct list_he
多核cpu、cpu高速缓存、缓存一致性协议、缓存行、内存
1、cpu高速缓存 工业实践表明,三层最合适 读 l0 >l1 > l2 > 内存 写 内存 > l2 > l1> l0 1、缓存一致性协议 有些指令会触发缓存一致性协议, 有些指令不会触发缓存一致性协议:i++不会。 MESI协议是其中的一种实现,英特尔cpu用的是MESI协议 2、缓存行 一个缓存行64个细节 同一颗cpu可能有多核,他们之间有缓存一致性保障,也就是同一行的数据发生改变后

使用esotericsoftware高速缓存(ASM)的BeanUtils.copyProperties!高性能!
一、事出有因 项目中使用BeanUtils.copyProperties但是其性能又不是很满意, 而且阿里发布了阿里巴巴代码规约插件指明了在Apache BeanUtils.copyProperties()方法后面打了个大大的红叉,提示"避免使用Apache的BeanUtils进行属性的copy"。心里确实不是滋味,从小老师就教导我们,"凡是Apache写的框架都是好框架",怎么可能会存在"性
Rails caching(Rails高速缓存)
目录 1. 基本缓存 1.1 page caching 1.2 action caching 1.3 fragment caching 1.4 俄罗斯套娃caching 1.5 共享部分caching 1.6 管理依赖 1.7 低级别caching 1.8 sql caching 2 cache stores 2.1 configuration 2.2 actives
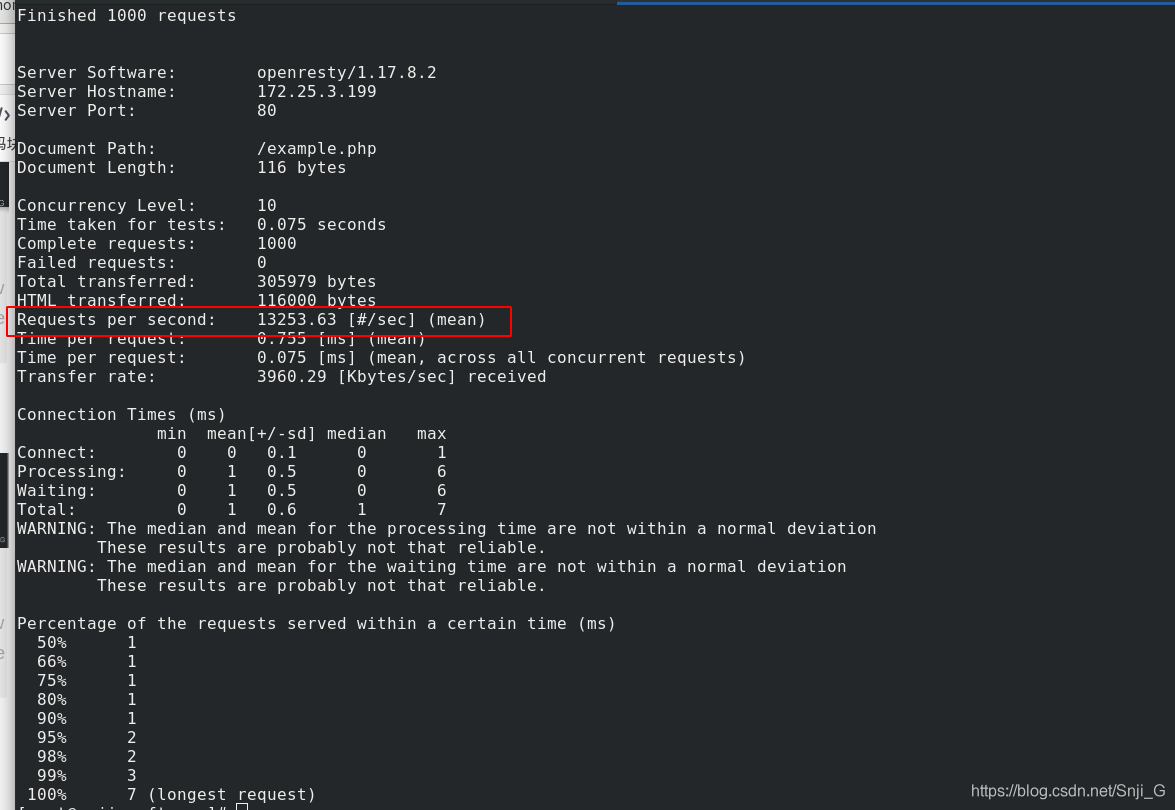
memcached 和 openresty 实现高速缓存机制
什么是memcached? 不支持持久化,没有安全机制。可以用telnet等工具直接连接memcached。memcached是多线程工作,而redis是单线程工作。各个memcached服务器之间互不通信,各自独立存取数据,不共享任何信息。服务器并不具有分布式功能,分布式部署取决于memcache客户端。 定义 :memcached是一个免费开源的、高性能的、具有分布式内存对象的缓存系统,通过

MySQL高速缓存启动方法及参数详解(query_cache_size)
MySQL query cache从4.1版本开始提供了,不过值今天本人才对其进行研究。默认配置下,MySQL的该功能是没有启动的,可能你通过show variables like ‘%query_cache%';会发现其变量have_query_cache的值是yes,MYSQL初学者很容易以为这个参数为YES就代表开启了查询缓存,实际上是不对的,该参数表示当前版本的MYSQL是否支持Quer

linux DNS高速缓存
配置名称服务器(本机ip:172.25.254.117) 1 安装 bind 软件包 – yum install -y bind 2 编辑 /etc/named.conf listen-on port 53 { any; }; ##开启端口allow-query { any; }; ##允许访问forwarders { 172.25.254.250; }
一 程序访问的局部性-cache高速缓存-cache和主存间映射
1.程序访问局部性 计算机存储层次结构 为提高性能/价格,将各存储器组成一个金字塔式的层次结构,取长补短协调工作 寄存器--->cache--->主存储器--->外存(disk,flash menory) 工作过程 •CPU运行时,需要的操作数大部分来自寄存器 •需从(向)存储器中取(存) 数时,先访问cache;若在,取自cache •若不在cache,则访问RAM;若
RH134-第二十三节-DNS高速缓存
DNS的介绍 1.所用端口号 tcp:53 udp:53 2.什么时候用tcp,什么时候用udp? tcp用在区域传送 udp用在域名解析 3.互联网上为什么有dns? 因为互联网的大多通讯都基于tcp/ip,而tcp/ip基于ip地址,但是IP地址对于人类来说没有那么好记,我们给每个IP地址设置一个名字,我们通过名字来访问,有dns服务器来把名字转换成IP地址来与外界通信。 4

SSD在AI发展中的关键作用:从高速缓存到数据湖-2
二、大规模长期存储数据湖 大规模数据集: AI应用需要处理大量的数据,这些数据可能来自多个来源,包括图像、视频、文本、音频等。为了有效地管理这些数据,组织通常将其存储在大型的数据湖中。 容量扩展: 由于数据集的不断增长,企业级SSD必须提供大容量存储选项,并且能够轻松扩展以满足未来的需求。全闪存阵列(All-Flash Arrays, AFA)和超融合基础设施(Hyper
页高速缓存学习2 关于buffer_head
page_has_buffers等在buffer_head.h里面定义 基数搜索32,64=2^6 而32/6=5余2,2^2=4,所以顶层最多4个节点 《深入理解linux内核》p616关于基数的理解 buffer_head里面包换逻辑块号,因为页里面逻辑块号连续,但是物理块号可能不连续,这是由FS决定
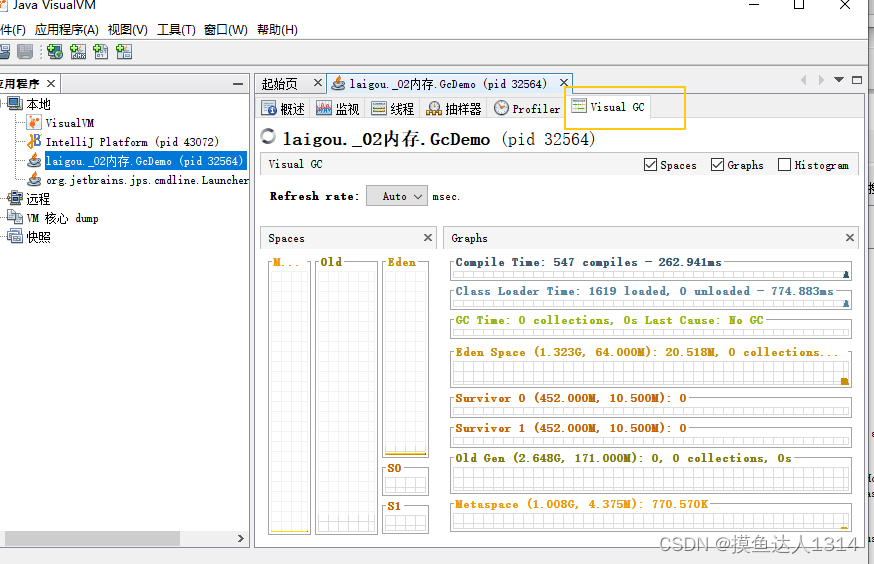
jdk安装Visual Gc,报错检查代理设置或稍后重试。服务器目前可能不可用。 您可能还需要确保防火墙不会阻塞网络通信。 您的高速缓存可能已过期。请单击“检查更新”以刷新内容。解决
安装Visual Gc 1.到jdk8\bin,双击 2.点击工具->插件 VisualVM-Classfish安装报错 报错 https://github.com/visualvm/visualvm.src/releases/download/1.3.9/com-sun-tools-visualvm-modules-visualgc.nbm中出现网络问题检查代
【浅谈】计算机存储 寄存器,高速缓存,内存和硬盘 栈区,堆区和静态区
https://blog.csdn.net/m0_66300397/article/details/130020405 计算机上的存储 数据在计算机中,存储在硬盘,内存,高速缓存和寄存器上。 四者根据速度和存储量,有如下表示: 寄存器上,一般都是字节大小的存储空间;高速缓存器上的存储空间要相对大一点,可以达到MB,但是也只是很小的存储空间。 电脑大部分的数据都存储在内存上,一般电脑
上海沙龙回顾 | Redis 高速缓存在大数据场景中的应用
10月26日,字节跳动技术沙龙 | 大数据架构专场 在上海字节跳动总部圆满结束。我们邀请到字节跳动数据仓库架构负责人郭俊,Kyligence 大数据研发工程师陶加涛,字节跳动存储工程师徐明敏,阿里云高级技术专家白宸和大家进行分享交流。 以下是阿里云高级技术专家白宸的分享主题视频:《Redis 高速缓存在大数据场景中的应用》。 更多精彩分享: 上海沙龙回顾 | 字节跳动在Spark SQL上的核心

死磕Java多线程(五)---理解CPU高速缓存的工作原理
我们说了Java内存模型是一个语言级别的内存模型抽象,它屏蔽了底层硬件实现内存一致性需求的差异,提供了对上层的统一的接口来提供保证内存一致性的编程能力。 在一致性这个问题域中,各个层面扮演的角色大致如下: 一致性模型,定义了各种一致性模型的理论基础硬件层,提供了实现某些一致性模型的硬件能力。硬件在默认情况下按照最基本的方式运行,比如 对同一个线程没有数据依赖的指令可以重排序优化执行,有数据依赖