本文主要是介绍100:ReconFusion: 3D Reconstruction with Diffusion Priors,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
官网

少样本重建必然导致nerf失败,论文提出使用diffusion模型来解决这一问题。从上图不难看出,论文一步步提升视角数量,逐步与Zip-NeRF对比。
实现流程
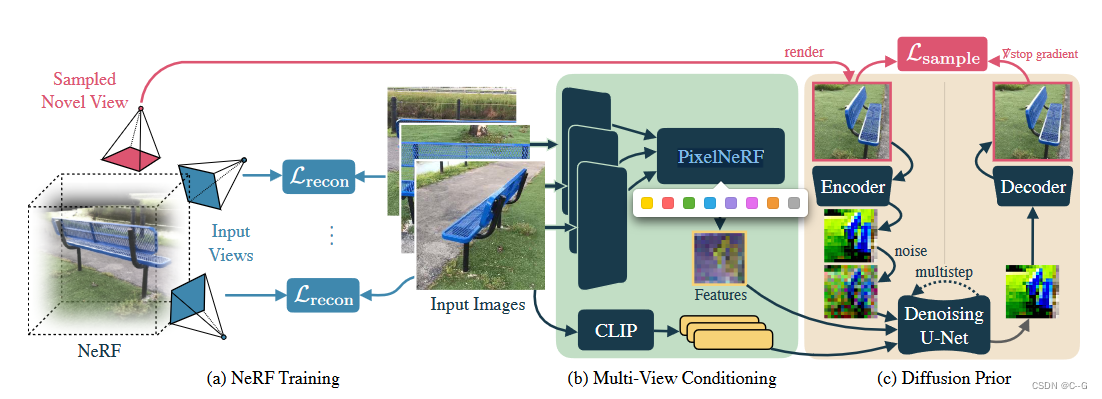
Diffusion Model for Novel View Synthesis
给定一组输入图像 x o b s = { x i } i = 1 N x^{obs}=\{x_i\}^N_{i=1} xobs={xi}i=1N以及对应的相机位姿 π o b s = { π i } i = 1 N \pi^{obs}=\{\pi_i\}^N_{i=1} πobs={πi}i=1N,希望在目标相机位姿 π \pi π下,图片 x 在 新试图的分布 p ( x ∣ x o b s , π o b s , π ) p(x|x^{obs},\pi^{obs},\pi) p(x∣xobs,πobs,π)
这里采用的扩散模型是 LDM(High-Resolution Image Synthesis with Latent Diffusion Models)。
LDM能够有效地模拟高分辨率图像。LDM使用预训练的变分自编码器(VAE) ϵ \epsilon ϵ 将输入图像编码为潜在表示。在这些潜在上进行扩散,其中去噪的U-Net ϵ θ \epsilon_\theta ϵθ将有噪声的潜在映射回干净的潜在。在推理过程中,使用该U-Net对纯高斯噪声进行迭代降噪,得到一个干净的潜在噪声。潜在表示通过VAE解码器D恢复为图像。
实现过程类似于Zero-1-to-3,将输入图像和相机位姿作为一个预训练文本到图像生成的LDM的附加条件。
将文本到图像模型转换为位姿图像到图像模型需要使用附加的条件反射路径来增强U-Net体系结构。
为了修改预训练的架构,以便从多个姿态图像中合成新的视图,向U-Net注入了两个新的条件反射信号。
- 对于输入的高级语义信息,使用CLIP嵌入每个输入图像(表示为 e o b s e^{obs} eobs),并通过交叉注意将该特征向量序列馈送到U-Net中。
- 对于相对相机姿态和几何信息,使用PixelNeRF模型的 R ϕ R_\phi Rϕ来渲染具有与目标视点 π \pi π相同空间分辨率的特征图 f
f = R ϕ ( x o b s , π o b s , π ) f = R_\phi(x^{obs},\pi^{obs},\pi) f=Rϕ(xobs,πobs,π)
特征图 f 是一个空间对齐的条件信号,它隐式地编码了相对相机变换。
沿信道维度将 f 与 噪声潜值 连接起来,并将其送入去噪UNet ϵ θ \epsilon_\theta ϵθ。
这种特征映射调节策略类似于GeNVS、SparseFusion中使用的策略,与直接嵌入相机外部和内部特征本身相比,可以更好地提供新的相机姿势的准确表示。
training
冻结预训练的编码器和解码器的权值,根据预训练的权值初始化U-Net参数θ,并利用简化的扩散损失对改进的视图合成结构进行了优化
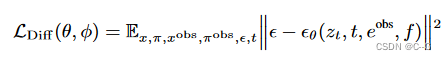
t∈{1,…, T}为扩散时间步长,ε ~ N (0, I), z t = α t ε ( x ) + σ t ϵ z_t = α_t \varepsilon(x) + σ_t \epsilon zt=αtε(x)+σtϵ为该时间步长的噪声潜函数, e o b s e^{obs} eobs 为输入图像 x o b s x^{obs} xobs 的CLIP图像嵌入,f 为PixelNeRF R φ R_φ Rφ 渲染的特征映射。
优化具有光度损耗的PixelNeRF参数φ:
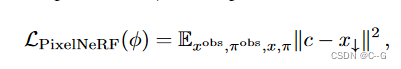
其中 c 是PixelNeRF模型的输出(与特征映射 f 具有相同的分辨率),x↓ 是下采样到 z t z_t zt 和 f 的空间分辨率的目标图像。这种损失鼓励 PixelNeRF重建RGB目标图像,这有助于避免扩散模型无法利用 PixelNeRF 输入的糟糕的局部最小值。
3D Reconstruction with Diffusion Priors
第一步的NeRF重建的光度损失
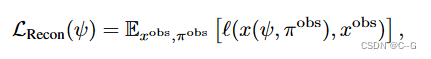
在每次迭代中,对随机视图进行采样,并从扩散模型中生成图像以生成目标图像。(通过从中间噪声水平开始采样过程来控制目标图像与当前渲染图像的接地程度。)
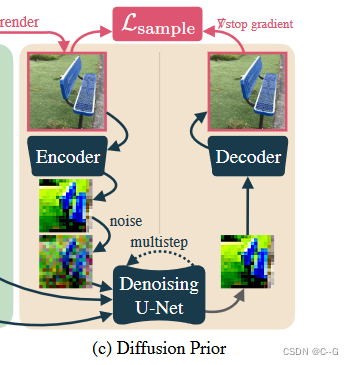
具体来说,从采样的新视点 π \pi π呈现图像 x ( ψ , π ) x(ψ, π) x(ψ,π),并将其编码和扰动为噪声潜码为 t U [ t m i n , t m a x ] t ~ U [t_{min}, t_{max}] t U[tmin,tmax]的噪声潜码 z t z_t zt。然后,通过运行DDIM采样,在最小噪声潜码和 t 之间均匀间隔 k 个中间步骤,从潜在扩散模型生成一个样本,从而得到一个潜在样本 z 0 z_0 z0。这个潜信号被解码以产生一个目标图像 x ^ π = D ( z 0 ) \hat{x}_\pi=D(z_0) x^π=D(z0):
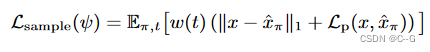
其中,$L_p¥为感知距离LPIPS, w(t)为依赖于噪声水平的加权函数。这种扩散损失最类似于SparseFusion,也类似于InstructNeRF2NeRF的迭代数据集更新策略,只不过在每次迭代时都采样一个新的图像。从经验上发现,这种方法比分数蒸馏取样更有效。
当使用扩散先验时,我们不想在物体内部或墙后放置新的视图,视图的放置通常取决于场景内容和捕获类型。与RegNeRF等先前的工作一样,希望根据已知的输入姿势和捕获模式定义一个分布,该分布将包含一组合理的新相机姿势,大致与期望观察重建场景的位置相匹配。
通过确定场景中的基本姿势集或路径来实现这一点,可以随机采样和扰动以定义新视图的完整姿势分布。在LLFF和DTU等前向捕获或mip-NeRF 360等360度捕获中,定义了一条适合训练视图的椭圆路径,面向焦点(与训练相机的焦轴平均距离最小的点)。在更多的非结构化捕获中,如CO3D和RealEstate10K,拟合b样条来大致遵循训练视图的轨迹。在任何一种情况下,对于每个随机的新视图,统一地选择路径中的一个姿态,然后扰动它的位置,向上向量,并在一定范围内查看点。
Implementation Details
基本扩散模型是对潜在扩散模型的重新实现,该模型在输入分辨率为512×512×3的图像-文本对的内部数据集和维度为64×64×8的潜在空间上进行了训练。
PixelNeRF的编码器是一个小的U-Net,它将分辨率为512×512的图像作为输入,并输出分辨率为64 × 64的128通道的特征图
联合训练PixelNeRF和微调去噪U-Net,批处理大小为256,学习率为 1 0 − 4 10^{−4} 10−4,共进行250k次迭代。为了实现无分类器制导(CFG),以10%的概率将输入图像随机设置为全零。
使用Zip-NeRF作为主干,并对NeRF进行了总共1000次迭代的训练。重构损失 L r e c o n L_{recon} Lrecon 与 Zip-NeRF一样使用Charbonnier损失。 L s a m p l e L_{sample} Lsample的权重在训练过程中从1线性衰减到0.1,采样使用的无分类器指导尺度设置为 3.0。将所有训练步骤的 t m a x = 1.0 t_{max} = 1.0 tmax=1.0 固定,并将 t m i n t_{min} tmin 从1.0线性退火到0.0。无论 t 如何,总是以k = 10步对去噪图像进行采样。在实践中,用于视图合成的扩散模型可以以少量观察到的输入图像和姿势为条件。给定一个新的目标视图,从观察到的输入中选择3个最近的相机位置来调节模型。这使模型能够在选择对采样的新视图最有用的输入时缩放到大量的输入图像。

Limitation
重量级扩散模型成本高,并且显著减慢了重建速度;研究结果表明,与图像模型在2D中产生的幻觉相比,3D绘制能力有限;调整重构和样本损失的平衡是繁琐的等。
这篇关于100:ReconFusion: 3D Reconstruction with Diffusion Priors的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







