priors专题

DynamiCrafter:Animating open-domain images with video diffusion priors
1.Method 图像条件视频生成, 1.1 Image Dynamics from Video Diffusion Priors 1.1.1 文本对齐的上下文表征 文本嵌入通过clip构建,图像通过clip编码,主要代表语义层面的视觉内容,未能捕获图像的完整信息,为了提取更完整的信息,使用来自clip图像vit最后一层的全视觉标记,该token在条件图像生成时表现出了高保真度,为

2009-CVPR - Image deblurring and denoising using color priors
项目地址:http://neelj.com/projects/twocolordeconvolution/ 没有代码=_= 微软研究院 非盲去模糊基于MAP超拉普拉斯先验+颜色先验 文章首先分析了Levin等人使用超拉普拉斯分布惩罚图像梯度(次线性惩罚函数),相比高斯分布更能建模自然图像0峰重尾梯度分布(the zero-peaked and heavy tailed gradient dis
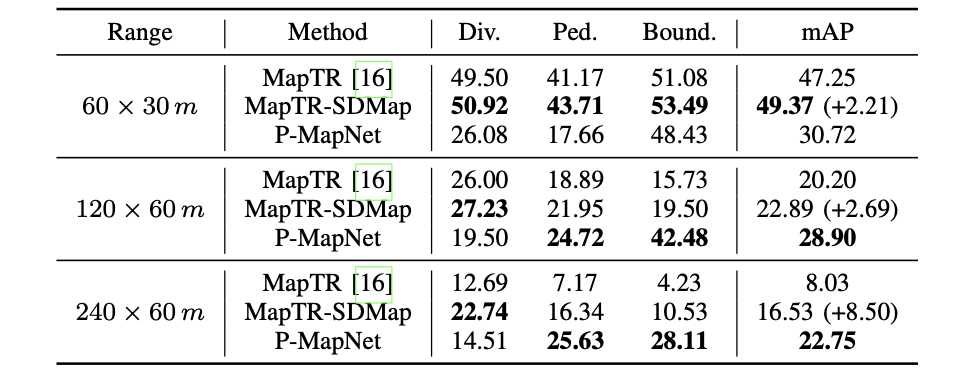
P-MapNet:Far-seeing Map Generator Enhanced by both SDMap and HDMap Priors
主页:homepage 参考代码:P-MapNet 动机与出发点 在感知系统中引入先验信息是可以提升静态元素感知网络的上限的,这篇文章对SD地图采用栅格化表示(也就是图像形式),之后用CNN网络去抽取栅格化SD地图的信息,将其作为BEV特征优化时额外信息的来源(也就是做key和val)。其实还有一种SD地图表示的方法,那就是向量化描述,目前现有的文献还没有对这两种模态表示更好做过细致分析。感知的

Priors in Deep Image Restoration and Enhancement: A Survey
深度图像恢复和增强中的先验:综述 论文链接:https://arxiv.org/abs/2206.02070 项目链接:https://github.com/VLIS2022/Awesome-Image-Prior (Preprint. Under review) Abstract 图像恢复和增强是通过消除诸如噪声、模糊和分辨率退化等退化来提高图像质量的过程。深度学习(DL)最近被应用

100:ReconFusion: 3D Reconstruction with Diffusion Priors
简介 官网 少样本重建必然导致nerf失败,论文提出使用diffusion模型来解决这一问题。从上图不难看出,论文一步步提升视角数量,逐步与Zip-NeRF对比。 实现流程 Diffusion Model for Novel View Synthesis 给定一组输入图像 x o b s = { x i } i = 1 N x^{obs}=\{x_i\}^N_{i=1} xobs=

sparse linear regression with beta process priors
虽然翻译水平有限,但是看原文虽然看得懂,但是在词汇的问题上,会导致看了后面忘了前面,所以先蹩脚的翻译成中文,然后在仔细思考论文的思想(当然不能翻译成中文就不看英文原本了,得两者一起看,这样不会丢失前面的思路,加快论文理解速度),我想随着不断的翻译,应该会提升效果吧。希望不会误导别人才好。 sparse linear regression with beta process priors(2010
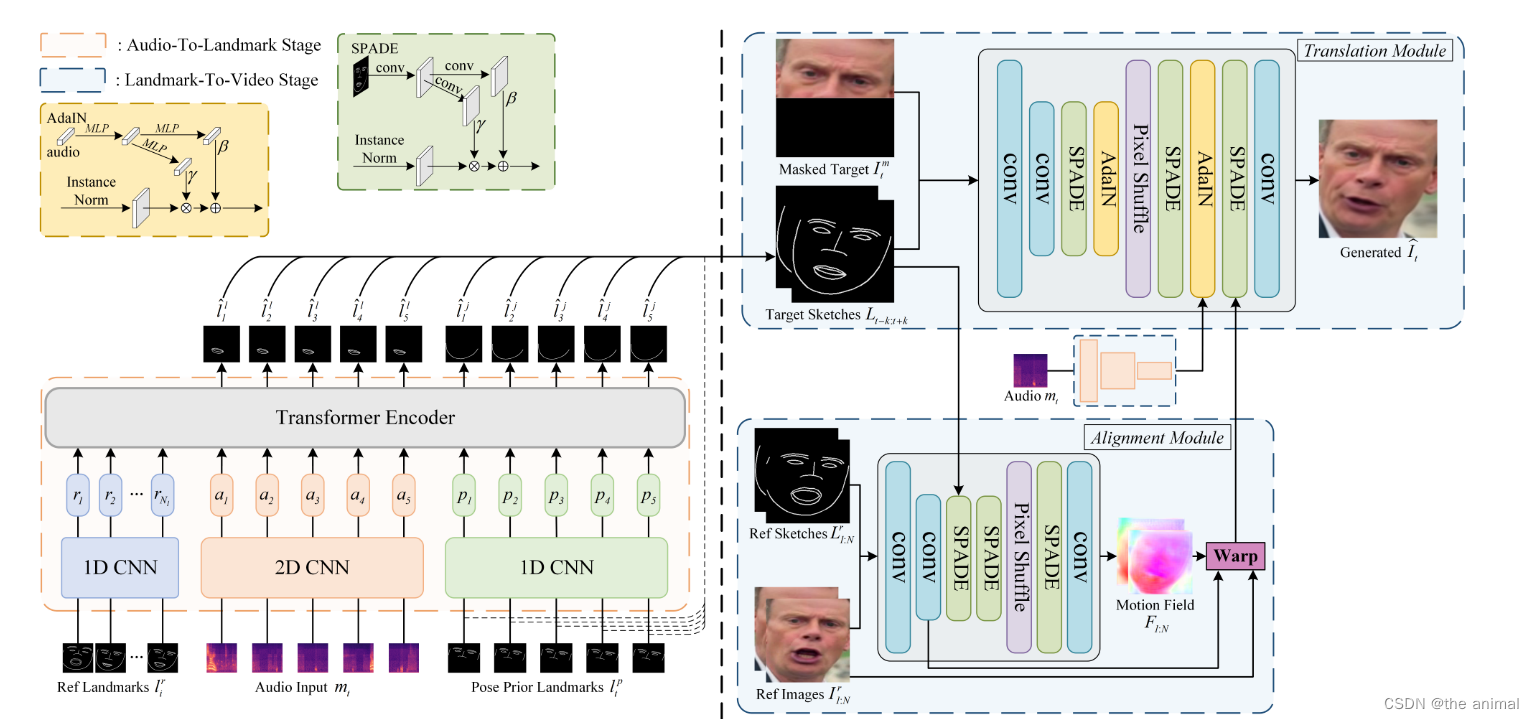
Identity-Preserving Talking Face Generation with Landmark and Appearance Priors
主要问题:1)模型如何生成具有与输入音频一致的面部运动(特别是嘴部和下颌运动)的视频?2)模型如何在保留身份信息的同时生成视觉上逼真的帧? 摘要: 从音频生成说话脸部视频引起了广泛的研究兴趣。一些特定个人的方法可以生成生动的视频,但需要使用目标说话者的视频进行训练或微调。现有的通用方法在生成逼真和与嘴唇同步的视频同时保留身份信息方面存在困难。为了解决这个问题,我们提出了一个两阶段的框架,包括从音频
![[23] SweetDreamer: Aligning Geometric Priors in 2D Diffusion for Consistent Text-to-3D](https://img-blog.csdnimg.cn/1ce2c5e53abb4414a8704faa5a00692a.png)
[23] SweetDreamer: Aligning Geometric Priors in 2D Diffusion for Consistent Text-to-3D
SWEETDREAMER: ALIGNING GEOMETRIC PRIORS IN 2D DIFFUSION FOR CONSISTENT TEXT-TO-3D pdf | project 目录 Method Alignning Geometric Priors in 2D Diffusion Integration into Text-to-3D Text-to-3D Ge
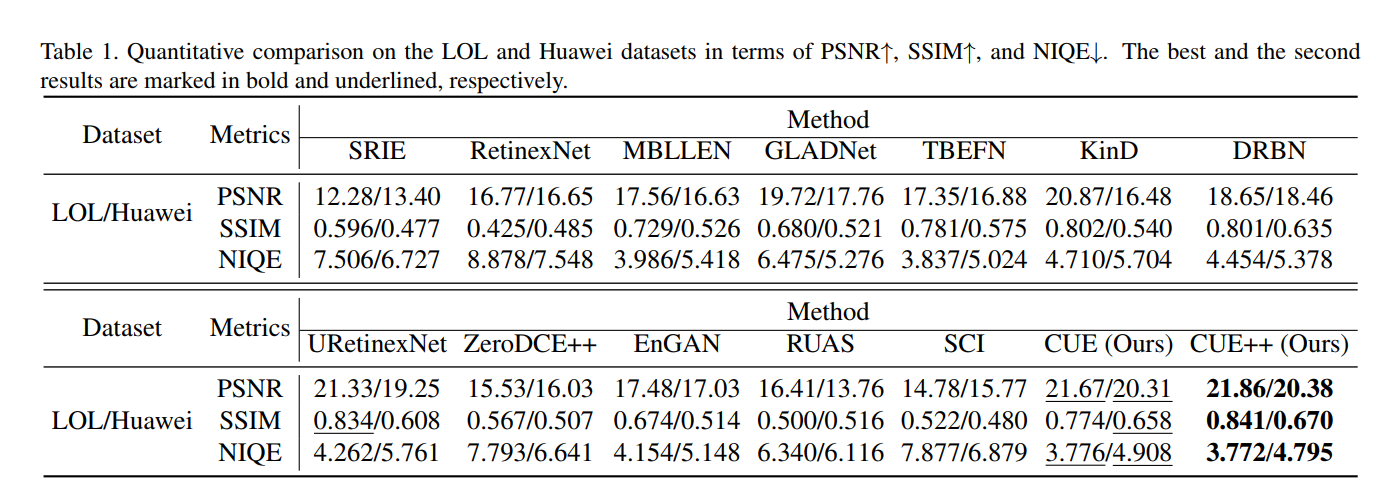
Empowering Low-Light Image Enhancer through Customized Learnable Priors 论文阅读笔记
中科大、西安交大、南开大学发表在ICCV2023的论文,作者里有李重仪老师和中科大的Jie Huang(ECCV2022的FEC CVPR2022的ENC和CVPR2023的ERL的一作)喔,看来可能是和Jie Huang同一个课题组的,而且同样代码是开源的,我很喜欢。文章利用了MAE的encoder来做一些事情,提出了一个叫customized unfolding enhancer (CUE

Unsupervised CT Metal Artifact Reduction by Plugging Diffusion Priors in Dual Domains
通过在双域中插入扩散先验来减少无监督 CT 金属伪影 论文链接:https://arxiv.org/abs/2308.16742 项目链接:https://github.com/DeepXuan/DuDoDp-MAR Abstract 在计算机断层扫描(CT)过程中,患者体内的金属植入物通常会导致重建图像中的破坏性伪影,从而阻碍准确诊断。许多基于监督深度学习的方法被提出用于金属伪影还原