本文主要是介绍语音神经科学-01.The cortical organization of speech processing,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
The cortical organization of speech processing: Feedback control and predictive coding the context of a dual-stream model(在双流模型的背景下,语音处理的皮层组织涉及到反馈控制和预测编码。)
想了解双流模型,可以参考:BCI-Two-streams hypothesis(双流假说)
专业术语
speech recognition 语音识别
predictive coding 预测编码
dorsal stream 背侧流
vental stream 腹侧流
conduction aphasia 传导性失语症
feedback control 反馈控制
temporal lobe 颞叶
superior temporal lobe 上颞叶
frontal lobe 额叶
posterior frontal lobe 后额叶
superior temporal sulcus(STS) 上颞沟(颞上沟)
superior temporal gyrus(STG) 上颞回
概述
本文作者概述了语音处理的双流模型,然后讨论了有关语音识别过程中预测编码来源的证据。并且作者总结出,腹侧感觉运动流才是促进语音识别的正向预测的来源。
阅读后读者能够:
解释语音处理的双路模型,包括背侧和腹侧通路在语言处理中的功能。- 理解对背侧通路某些组成部分的干扰如何导致
传导性失语症。 - 解释运动行为中状态
反馈控制的基本原理。 - 理解
预测编码在运动控制和知觉中的作用,以及两个通路中的预测编码可能具有不同的功能后果。
提出问题
Q:为什么语音处理是双路模型?
A: 双路模型的基本假设是,语音处理需要同时进行语言理解和语音产生两个过程,并且这两个过程在大脑中通过不同的通路进行。这种双路模型的观点得到了大量的神经影像学和神经病理学研究的支持。
Q: 什么是双路模型?
A:双路模型是一种描述语音处理组织的理论框架,它将语音处理划分为两个主要的神经通路:腹侧通路(ventral stream)和背侧通路(dorsal stream)。
腹侧通路主要与语言理解和语义处理相关。它负责将声学语音信息与语言的概念-语义表示相连接。在这个通路中,声学信息经过听觉皮层的初步处理,然后传递到颞叶的背侧上颞沟和背侧下颞回,进一步进行语音和语言的分析和解释。腹侧通路的关键区域包括Wernicke区和Broca区,它们在语言理解和产生中起着重要的作用。
背侧通路主要与运动控制和语音产生相关。它负责将声学语音信息与运动言语系统相连接,以便实现语音的再现。在背侧通路中,声学信息通过听觉皮层的处理后,进入到颞叶和顶叶交界处的背侧通路起始部分,然后连接到运动皮层,控制口腔和喉部肌肉的运动,产生语音声音。背侧通路的关键区域包括Sylvian顶颞联合(Spt)和运动皮层。
语音处理中的双流模型
双路模型(下图)认为,腹侧通路涉及颞叶(temporal lobe)的上部和中部结构,参与处理语音信号以进行理解。背侧通路涉及颞叶后部的音障区和额叶后部结构,参与将声学语音信号转化为运动表征,这对于语音产生至关重要。与语音处理主要依赖左半球的典型观点相反,广泛的证据表明,腹侧通路具有双侧组织(尽管两个半球之间存在重要的计算差异)。另一方面,背侧通路在左半球中占主导地位。
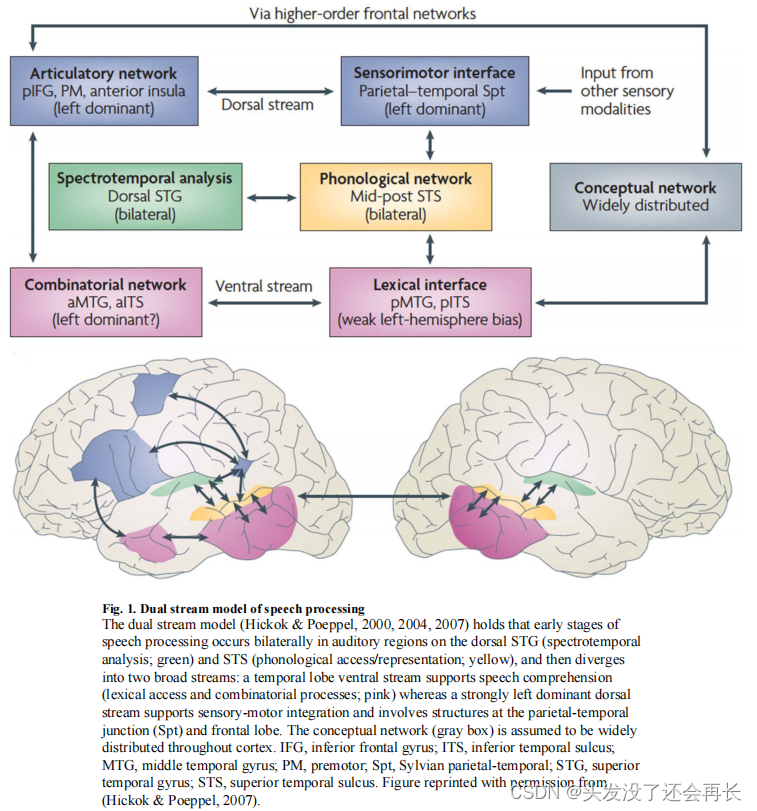
腹侧通路:从声音到意义的映射
双边组织的并行计算
腹侧通路是并行计算的,证据是观察到左脑损伤不会导致患者在理解过程中处理语音信息的能力急剧下降。然而,累积到颞上叶的双侧病变会导致严重的语音知觉缺陷。
从医学成像中也发现,听取语音会在双侧激活包括背侧颞回和上颞沟(STS)在内的颞叶上部回旋(STG)。
计算不对称
声音识别中的音素级过程双侧组织的假设并不意味着两个半球在计算上完全相同。事实上,有强有力的证据表明在处理声学/语音信息时存在半球间的差异
音韵处理和STS
Q: 什么是音韵?
A: 音韵是语言学中研究语音结构和音位系统的分支。它关注的是语言中的音素(phoneme)和音位(allophone),以及它们在词汇和语法中的组合和变化规律。
在语言中,音素是最小的语音单位,它们可以区分词义。例如,在英语中,/p/和/b/是两个不同的音素,因为它们可以使词的意义发生变化,如"pat"和"bat"。而音位是音素的具体发音方式或变体,它们在不同的语音环境中可能会有一些细微的差异,但不会改变词的意义。
除了语音识别的最早阶段,越来越多的证据表明STS的某些部分对于表示和/或处理音韵信息非常重要。STS在需要访问音韵信息的语言任务中被激活,包括语音的感知和产生,以及音素信息的主动维持。与复杂的非语音信号相比,STS的某些部分似乎对包含音韵信息的声学信号相对选择性较高。
词汇语义访问
在听觉理解过程中,语音处理的目标是利用音韵信息来访问对理解至关重要的概念-语义表示。双流模型认为,虽然概念-语义表示在大脑皮层中广泛分布,但一个更集中的系统作为计算接口,将音韵层次的表示与分布式的概念表示进行映射。这个接口并不是存储概念信息的地方。相反,它被假设为存储有关音韵信息与概念信息之间关系(或对应关系)的信息。大多数作者都同意颞叶在这个过程中起着关键作用。但关于是颞叶前部和后部的作用仍存在歧义。
背侧通路:从声音到行为的映射
背侧通路支持听觉和言语运动表示之间的接口,用于言语的感觉-运动整合。这一观点与背侧视觉通路具有感觉-运动整合功能的主张相似。
对听觉运动整合的需要
Wernicke的经典语言神经回路模型包括了感觉和运动言语表示之间的连接,并明确认为感觉系统参与了言语产生。
在视觉-手动领域中,我们通过视觉方式识别杯子的位置和形状(感觉目标),然后生成一个运动指令,使我们的肢体朝着那个位置移动,并塑造手的形状以匹配物体的形状。在言语领域中,目标并不是外部对象,而是单词声音模式(音韵形式)的内部表示。我们知道,这些目标具有听觉性质,因为在言语产生中操纵自己的听觉反馈会导致运动言语行为的补偿性变化。
在过去的十年中,在对言语的感觉运动整合的神经组织进行映射方面取得了很大的进展。这项工作确定了一个包括上颞沟区(superior temporal sulcus)的听觉区域、左侧额下回(left inferior frontal gyrus)(Broca区的一部分)的运动区域、更背侧的左侧前运动区以及左侧颞叶平面(left planum temporale)区域的网络区域,该区域被称为Spt区域。
传导性失语症是一种语言障碍,其特点是患者在理解语言方面表现出良好的能力,但在语音产生过程中会频繁出现音素错误。
研究发现,传导性失语症患者的语音产生缺陷与负荷敏感性相关。这意味着在处理较长、较低频的单词以及具有较少语义约束的连续语音重复时,患者更容易出现错误。这表明在传导性失语症中,语音产生过程中的缺陷与语言负荷有关。
这些损伤的影响可以理解为在听觉目标和能够实现这些目标的运动语音行动之间提供接口的系统中断。
传导性失语症的病变分布已被证明与听觉-运动整合区Spt的位置重叠,这与传导性失语是由该界面系统损伤引起的观点一致。
语音感知的前向预测
对文献中关于言语知觉的当前讨论的审视给人的印象是,言语知觉中的前向预测几乎是公理性的。可以明显地看出,知道要听什么可以增强我们感知言语的能力。然而,这些预测的来源还不太清楚。
Q: 什么是预测编码?
A: 预测编码(Predictive coding)是一种神经信息处理框架,用于解释和理解外部世界。它基于大脑通过生成对感知输入的预测来进行感知和认知的假设。
预测编码的基本原理是,大脑通过生成对感知输入的预测来解释外部世界,并通过比较预测和实际感知输入之间的差异来更新和调整神经活动。 具体来说,大脑会生成多个层次的预测,从低层次的感知特征到高层次的语义和概念。这些预测通过反馈连接传递到较低层次的感知区域,与实际的感知输入进行比较。如果预测与实际感知输入相符,那么大脑会减少对该信息的处理,从而提高信息处理的效率。如果预测与实际感知输入不符,那么大脑会增加对该信息的处理,以更好地解释和理解外部世界。
Q: 什么是感知?
A: 感知是指通过感觉器官接收和获取外部刺激的过程,以及将这些刺激转化为神经信号并传递到大脑中进行处理和解释的过程。它是我们对外部世界的感知和认知的基础。
感知涉及感觉器官(如眼睛、耳朵、皮肤、鼻子和舌头)的功能,它们能够接收不同类型的刺激,如光线、声音、触觉、气味和味道。当这些刺激作用于感觉器官时,它们会转化为神经信号,并通过神经途径传递到大脑中的相应感觉区域。
Q: 预测编码在感知中的作用?
A:预测编码在感知中起着重要的作用。它是一种神经信息处理框架,通过生成对感知输入的预测来解释和理解外部世界。
在感知过程中,大脑会不断生成对感知输入的预测。这些预测可以基于先前的经验、内部模型和上下文信息。预测编码的基本原理是,大脑通过比较预测和实际的感知输入之间的差异来更新和调整神经活动。如果预测与实际感知输入相符,那么大脑会减少对该信息的处理,从而提高信息处理的效率。如果预测与实际感知输入不符,那么大脑会增加对该信息的处理,以更好地解释和理解外部世界。
预测编码的作用是减少感知误差。通过不断生成和更新对感知输入的预测,大脑可以预测到即将发生的感知输入,并将注意力和资源集中在与预测不符的信息上。这种预测编码的过程使大脑能够更加高效地处理感知信息,并产生对外部世界的准确认知。
Q: 前向预测在运动控制中的作用?
A: 前向预测在运动控制中起着重要的作用。它是指在进行运动之前,大脑会通过内部模型生成预测,预测运动的结果和感觉后果。这些预测可以帮助调节和优化运动执行过程。
前向预测在运动控制中的作用可以总结如下:
运动计划和执行:前向预测可以帮助大脑规划和执行运动。通过预测运动的结果,大脑可以调整肌肉活动和运动轨迹,以实现预期的目标。
- 运动校正:如果前向预测与实际感觉结果不一致,大脑可以使用预测误差来进行运动校正。这可以帮助纠正运动中的错误,使运动更加准确和精确。
- 运动流畅性:前向预测可以提高运动的流畅性。通过提前预测感觉结果,大脑可以调整运动速度和力度,以使运动过程更加平滑和连贯。
- 运动感知:前向预测可以影响感知过程。当大脑预测到自己的运动时,它可以抑制对相应感觉的敏感性,从而减少感知上的干扰。
而言语控制也是运动控制的一种。
最近,几个研究小组提出,来自运动系统的前向预测可能有助于言语知觉。这个想法的逻辑是:如果运动系统能够为自己的言语行为的感觉后果生成预测,那么也许这个系统可以用来预测他人言语的感觉后果,从而促进知觉。然而,这个想法存在概念上和实证上的问题。
最新的研究表明,在视听语音整合中,影响语音识别和理解的并非来自运动预测,而是来自腹侧通路中的跨感觉整合。这些发现对我们理解语音处理的机制和神经基础提供了重要的线索。
文献总结
背侧流正向预测主要服务于运动控制功能,并不促进对他人的语音识别,而腹侧流正向预测功能可以增强语音识别。
这篇关于语音神经科学-01.The cortical organization of speech processing的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






