本文主要是介绍[数据启示录 01] 线性表及其实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
扩充并填补内容:c语言入门知识
- 结构体
- 存储多个相关的属性,可以理解为一种自定义数据类型.
- 语法
- 定义结构体
struct 结构体名称 {属性名 数据类型;属性名 数据类型;
};
2. //声明结构体变量//struct 结构体名 变量名;
- typedef
- 定义结构体时使用typedef,大括号后是数据类型,不是变量
- 定义变量时可以省略struct关键字
- 作为方法参数时可以省略struct关键字
- 值传递与地址传递
- 指针
- 指针是C语侵权言中重要的概念,它存储了一个变量的地址。
- 使用指针可以直接操作变量的地址,对变量进行间接访问。
- 语法
- 定义指针
数据类型 *指针变量名;
2. 获取变量地址
&变量名;
3. 操作指针
*指针变量名;
- 内存动态分配
- C语言中可以使用malloc函数动态分配内存空间,用完后需要使用free函数释放内存。
- 动态分配内存可以在程序运行时根据需要分配和释放内存,灵活性较高。
- 语法
数据类型 *指针变量名 = (数据类型 *)malloc(所需内存大小);
// 使用指针变量进行操作
free(指针变量名);
- 文件操作
- C语言可以通过文件操作实现对文件的读写。
- 文件操作包括打开文件、读取内容、写入内容和关闭文件等操作。
- 语法
FILE *文件指针名;
文件指针名 = fopen("文件名", "模式");
// 读取或写入文件内容
fclose(文件指针名);
- 函数指针
- 函数指针可以指向函数,允许在运行时动态决定调用哪个函数。
- 函数指针的声明和使用可以增加程序的灵活性和可扩展性。
- 语法
返回类型 (*指针变量名)(参数列表);
// 调用函数指针
指针变量名 = 函数名;
(*指针变量名)(参数);
入门
- 算法研究操作过程与操作方法,关注程序运行时长(时间问题)
- 数据结构研究数据组织与存储方式,重点关注内存(空间问题)
- 二分查找
- 三根线 begin,end,index = (begin + end) / 2
- 小了 begin向后移 begin = index + 1
- 大了 end向前移 end = index - 1
int binarySearch(int nums[], int length, int target) {int index = 0, begin = 0, end = length - 1;do {index = (begin + end) / 2;if(target < nums[index]) {//目标在前面end = index - 1;} else if(target > nums[index]) {//目标在后面begin = index + 1;} else {break;}} while (begin <= end);if(begin > end) index = -1;return index;
}
int main() {int nums[9] = {1,3,4,5,6,8,12,14,16}, target = 14;int index = binarySearch(nums, 9, target);if(index == -1) {printf("%d在数组中不存在!", target);} else {printf("%d在数组中的下标是:%d", target, index);}return 0;
}
- 时间复杂度
- 时间复杂度表示算法处理数据个数与操作次数之间的关系。
- O(1) 常数阶
O(log2n) 对数阶 二分查找
O(n) 线性阶 简单查找
O(nlog2n) 线性对数阶 快速排序
O(n2) 平方阶 冒泡排序
O(n3) 立方阶
O(nk) K次方阶
O(n!) 指数阶 - 无循环顺序执行为常数阶
单层完全循环是线性阶
单层递归减半循环是对数阶
嵌套循环是平方阶
三层循环是立方阶
- 逻辑结构:数据相互关系
- 线性结构 = 线性表(逻辑结构)
- 物理结构:数据在计算机中的存储形式
- 顺序存储 线性结构的顺序存储存储=顺序表 (线性表的顺序存储=顺序表)
- 链式存储 线性结构的链式存储=链表(线性表的链式存储=链表)
计算机上多项式的表示
在计算机上表达多项式有多种方法,常见的包括:
-
数组表示法:
使用数组来存储多项式中的系数,数组的下标表示指数。例如,一个多项式 3x^2 + 2x + 5 可以表示为数组 [5, 2, 3],其中索引 0 对应常数项,索引 1 对应 x 的系数,索引 2 对应 x^2 的系数。 -
链表表示法:
使用链表来存储多项式中的每一项,每个节点包含系数和指数,可以使用单链表或者其他类型的链表结构来表示。 -
哈希表表示法:
使用哈希表来存储多项式中的系数和指数的对应关系,这样可以快速查找特定指数的系数。 -
对象表示法:
可以定义一个多项式类,类中包含成员变量用来存储多项式的系数和指数,以及对应的操作方法。
这些表示方法各有优劣,选择哪种方法取决于具体的需求和实际应用场景。在实际编程中,可以根据具体情况选择最适合的表示方法来实现多项式的计算和操作。




顺序表
- 顺序表 = 线性结构(线性表) + 顺序存储(数组)
- 线性表,栈,队列的关系
- 顺序表的优缺点?
- 结构体struct使用
- typedef含义
- 顺序表结构体中为什么使用DataType?
- 顺序表开发步骤?
什么是线性表

线性表是一种常见的数据结构,它是由一组数据元素组成的有序序列。线性表中的数据元素之间存在一对一的关系,即每个元素只有一个直接前驱和一个直接后继(除了第一个元素没有前驱,最后一个元素没有后继)。线性表中的元素可以是任意类型,例如整数、字符、对象等。
线性表具有以下特点:
- 元素之间的顺序是确定的,每个元素都有一个唯一的位置。
- 可以根据元素在线性表中的位置进行访问和操作。
- 除第一个元素和最后一个元素外,其他元素都有前驱和后继。
线性表可以用多种方式实现,常见的包括数组、链表和向量等。不同的实现方式对于插入、删除、查找等操作的效率有所差异。
线性表的应用非常广泛,常见的线性表有数组、链表、栈、队列等。它们在算法和数据结构中起着重要的作用,被广泛应用于计算机科学的各个领域。

线性表的抽象数据描述
线性表的抽象数据描述可以定义如下:
- 数据对象:线性表是由一组数据元素组成的有序序列,每个元素可以是任意类型。
- 数据操作:
- 初始化操作:创建一个空的线性表。
- 销毁操作:释放线性表占用的内存空间。
- 插入操作:在线性表的指定位置插入一个新元素。
- 删除操作:删除线性表中指定位置的元素。
- 查找操作:根据元素的值或位置来查找元素。
- 修改操作:修改线性表中指定位置的元素的值。
- 获取操作:获取线性表中指定位置的元素的值。
- 判空操作:判断线性表是否为空。
- 获取长度操作:获取线性表中元素的个数。
线性表的抽象数据描述定义了线性表的基本操作,通过这些操作可以对线性表进行初始化、插入、删除、查找、修改等操作,以及获取线性表的长度和判断线性表是否为空。
具体实现线性表时,可以使用数组、链表、向量等不同的数据结构来表示和操作线性表。不同的实现方式对于操作的效率和灵活性可能有所差异,因此在选择实现方式时需要根据具体应用场景和需求进行权衡。
线性表的顺序存储实现通常使用数组来存储数据元素,每个元素占据数组中的一个位置。下面是线性表的顺序存储实现的一般步骤:
- 定义结构体:首先定义一个结构体来表示线性表,结构体中包含一个数组和记录线性表长度的变量。
#define MAXSIZE 100 // 假定线性表的最大长度typedef struct {ElementType data[MAXSIZE]; // 用数组存放线性表的数据元素int length; // 记录线性表的当前长度
} SqList; // 结构体名为 SqList
- 初始化操作:创建一个空的线性表,并进行初始化。
void InitList(SqList *L) {L->length = 0; // 初始化线性表长度为0
}
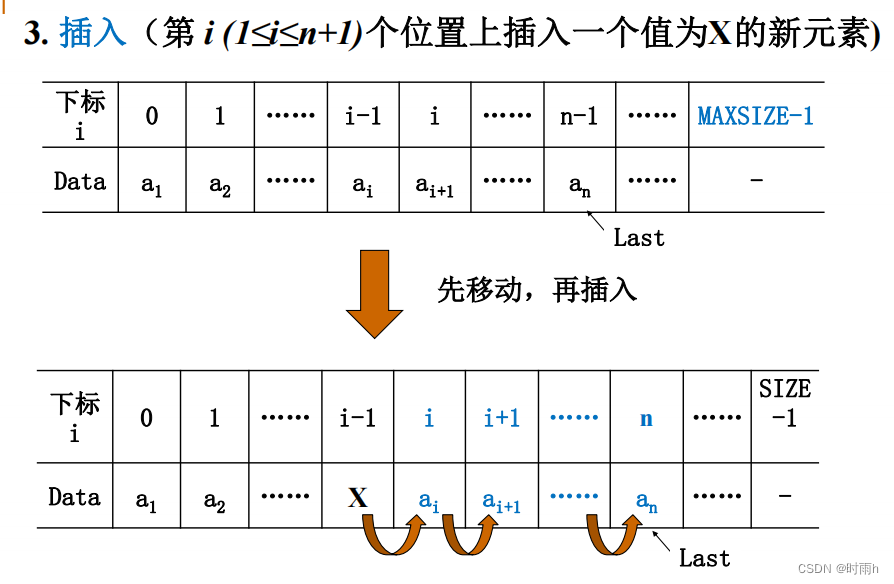
- 插入操作:在指定位置插入一个新元素。
Status ListInsert(SqList *L, int i, ElementType e) {if (i < 1 || i > L->length + 1) {return ERROR; // 插入位置不合法}if (L->length >= MAXSIZE) {return ERROR; // 线性表已满}for (int j = L->length; j >= i; j--) {L->data[j] = L->data[j - 1]; // 将第i个位置及之后的元素后移}L->data[i - 1] = e; // 将新元素插入到位置iL->length++; // 线性表长度加1return OK;
}
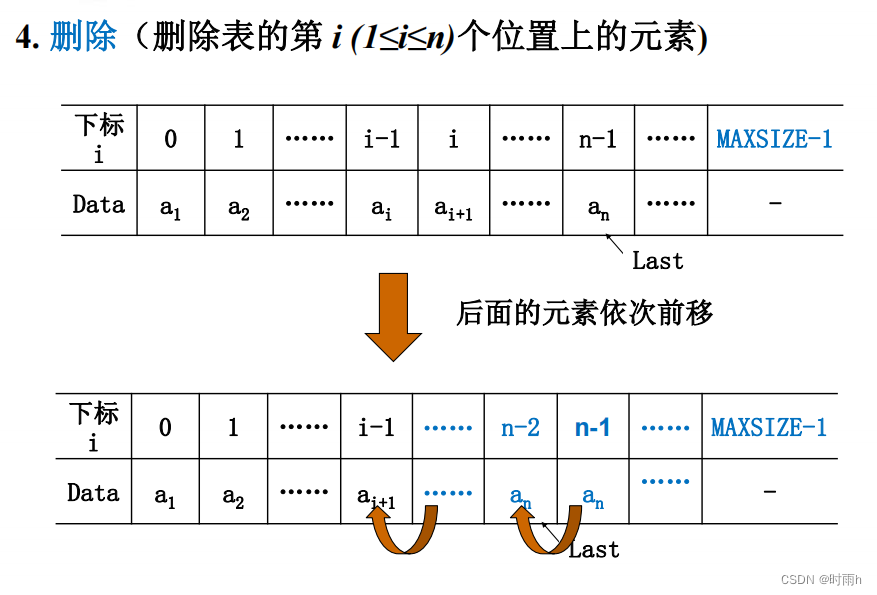
- 删除操作:删除线性表中指定位置的元素。
Status ListDelete(SqList *L, int i, ElementType *e) {if (i < 1 || i > L->length) {return ERROR; // 删除位置不合法}*e = L->data[i - 1]; // 将被删除的元素赋值给efor (int j = i; j < L->length; j++) {L->data[j - 1] = L->data[j]; // 将第i个位置之后的元素前移}L->length--; // 线性表长度减1return OK;
}
- 其他操作:根据需要实现获取、修改、判空、获取长度等其他操作。
顺序存储实现的线性表具有简单、易于实现的特点,但在插入和删除元素时需要移动大量元素,因此效率较低。对于大规模的数据插入和删除操作,可能不太适合使用顺序存储实现。

线性表的链式存储
线性表的链式存储实现通常使用链表来存储数据元素,每个节点包含数据和指向下一个节点的指针。下面是线性表的链式存储实现的一般步骤:
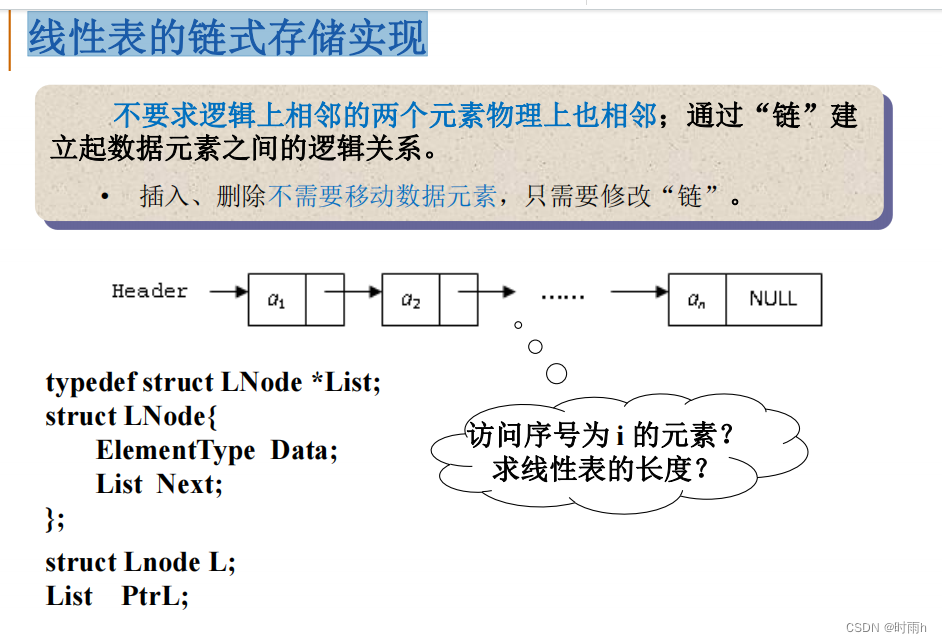
- 定义结点类型:首先定义一个结点类型来表示链表中的节点。
typedef struct LNode {ElementType data; // 数据域struct LNode *next; // 指针域,指向下一个结点
} LNode;
- 初始化操作:创建一个空的链表,并进行初始化。
LNode* InitList() {LNode *L;L = (LNode*)malloc(sizeof(LNode)); // 分配头结点空间if (!L) {printf("内存分配失败");return NULL;}L->next = NULL; // 头结点的指针域置空return L;
}
- 插入操作:在指定位置插入一个新元素。
Status ListInsert(LNode *L, int i, ElementType e) {LNode *p, *s;int j = 0;p = L;while (p && j < i - 1) {p = p->next;++j;}if (!p || j > i - 1) {return ERROR; // 插入位置不合法}s = (LNode*)malloc(sizeof(LNode)); // 分配新结点空间if (!s) {printf("内存分配失败");return ERROR;}s->data = e; // 将新元素赋值给新结点的数据域s->next = p->next; // 新结点指向原来的后继结点p->next = s; // 前驱结点指向新结点return OK;
}
- 删除操作:删除链表中指定位置的元素。
Status ListDelete(LNode *L, int i, ElementType *e) {LNode *p, *q;int j = 0;p = L;while (p->next && j < i - 1) {p = p->next;++j;}if (!(p->next) || j > i - 1) {return ERROR; // 删除位置不合法}q = p->next; // q指向被删除的结点*e = q->data; // 将被删除的元素赋值给ep->next = q->next; // 将被删除结点的前驱结点指向被删除结点的后继结点free(q); // 释放被删除结点的空间return OK;
}
- 其他操作:根据需要实现获取、修改、判空、获取长度等其他操作。
链式存储实现的线性表具有插入和删除操作简单、灵活的特点,但由于需要动态分配和释放内存,可能会带来一定的额外开销。另外,链表在查找特定位置的元素时需要遍历整个链表,效率相对较低。
广义表

广义表是一种扩展了线性表的数据结构,它可以包含元素和子表。广义表是一个递归定义的结构,可以无限嵌套,并且每个节点可以是原子元素或者是另一个广义表。
广义表的形式可以用以下的语法来表示:
广义表 ::= 原子 | ( 广义表的表头 广义表的表尾 )
其中,原子表示广义表中的一个单独的元素,而表头和表尾则分别表示广义表中的第一个元素和剩余的部分(一个广义表)。
举个例子,下面是一个包含原子元素和子表的广义表的示例:
A = (1, (2, 3), (4, (5, 6)), 7)
在这个示例中,广义表A包含了四个元素:1、(2, 3)、(4, (5, 6))和7。其中,(2, 3)和(4, (5, 6))都是广义表,它们作为A的子表存在。
广义表可以通过递归的方式进行遍历和操作。例如,可以通过递归函数来计算广义表中元素的个数、深度,或者进行遍历、查找等操作。
需要注意的是,广义表与传统的线性表(如数组、链表)不同,它具有更高的表达能力,但同时也增加了处理的复杂性。

下面是一个使用C语言实现广义表的简单示例:
#include <stdio.h>
#include <stdlib.h>// 定义广义表结点类型
typedef struct GLNode {int tag; // 结点标志,0表示原子,1表示子表union {char data; // 原子结点的数据struct GLNode *sublist; // 子表结点的指针};struct GLNode *next; // 指向下一个结点
} GLNode;// 创建广义表函数
GLNode* CreateGLNode(char *str) {GLNode *L, *p;L = (GLNode*)malloc(sizeof(GLNode));p = L;while (*str != '\0') {if (*str == '(') { // 遇到'(',表示子表开始p->tag = 1;p->sublist = CreateGLNode(str + 1); // 递归创建子表while (*str != ')') {str++; // 跳过子表内容}} else if (*str == ',') { // 遇到',',表示元素分隔p->next = (GLNode*)malloc(sizeof(GLNode));p = p->next;p->tag = 0;p->data = *(str + 1);p->next = NULL;}str++;}return L;
}// 打印广义表函数
void PrintGLNode(GLNode *L) {if (L == NULL) {return;}if (L->tag == 1) { // 子表printf("(");PrintGLNode(L->sublist);printf(")");} else if (L->tag == 0) { // 原子printf("%c", L->data);}if (L->next != NULL) {printf(",");PrintGLNode(L->next);}
}// 释放广义表函数
void FreeGLNode(GLNode *L) {if (L == NULL) {return;}if (L->tag == 1) { // 子表FreeGLNode(L->sublist);}FreeGLNode(L->next);free(L);
}int main() {char str[] = "(1,(2,3),(4,(5,6)),7)";GLNode *L;L = CreateGLNode(str);printf("创建的广义表为: ");PrintGLNode(L);printf("\n");FreeGLNode(L);return 0;
}
该示例中,我们使用递归的方式创建和打印广义表。通过传入一个字符串表示广义表的内容,程序会按照广义表的语法规则进行解析,并创建相应的广义表数据结构。然后,我们可以调用PrintGLNode函数来打印创建的广义表。
多重链表

多重链表是一种特殊的链表结构,其中每个节点包含多个指针字段,用于链接不同级别的节点。
在多重链表中,每个节点可以有多个后继节点,称为下一级节点。这些后继节点可以通过不同的指针字段进行链接,形成多个链表。
多重链表的结构可以根据实际需求进行设计。例如,可以使用双向链表或者带有指针数组的链表来实现多重链表。
下面是一个使用双向链表实现简单多重链表的示例:
#include <stdio.h>
#include <stdlib.h>typedef struct Node {int data;struct Node *next; // 同一级别下一个节点struct Node *down; // 下一级别的节点
} Node;// 创建多重链表
Node* CreateMultiLinkedList(int *arr, int m, int n) {Node *head = NULL;Node *levelHead = NULL;Node *prev = NULL;int i, j;for (i = 0; i < m; i++) {levelHead = NULL;for (j = 0; j < n; j++) {Node *newNode = (Node*)malloc(sizeof(Node));newNode->data = arr[i * n + j];newNode->next = NULL;newNode->down = NULL;if (levelHead == NULL) {levelHead = newNode;} else {prev->next = newNode;}prev = newNode;}if (head == NULL) {head = levelHead;} else {prev->down = levelHead;}}return head;
}// 打印多重链表
void PrintMultiLinkedList(Node *head) {Node *levelNode = head;while (levelNode != NULL) {Node *node = levelNode;while (node != NULL) {printf("%d ", node->data);node = node->next;}printf("\n");levelNode = levelNode->down;}
}// 释放多重链表内存
void FreeMultiLinkedList(Node *head) {Node *levelNode = head;while (levelNode != NULL) {Node *node = levelNode;Node *nextLevelNode = levelNode->down;while (node != NULL) {Node *nextNode = node->next;free(node);node = nextNode;}levelNode = nextLevelNode;}
}int main() {int arr[] = {1, 2, 3, 4, 5, 6, 7, 8, 9};int m = 3; // 高度int n = 3; // 宽度Node *head = CreateMultiLinkedList(arr, m, n);printf("多重链表内容:\n");PrintMultiLinkedList(head);FreeMultiLinkedList(head);return 0;
}
在上面的示例中,我们使用双向链表来实现多重链表。每个节点包含一个指向下一个节点的指针next和一个指向下一级节点的指针down。通过逐层遍历,我们可以打印出多重链表的内容。

回答:
-
顺序表是一种线性结构,它通过顺序存储的方式来组织和存储数据。顺序表使用数组作为底层数据结构,通过连续的内存空间来存储数据元素。
-
线性表、栈和队列都属于线性结构。
- 线性表是最基本的线性结构,其中的数据元素按照线性的顺序排列。
- 栈是一种特殊的线性表,它只能在表的一端进行插入和删除操作,遵循先进后出的原则。
- 队列也是一种特殊的线性表,它只能在表的一端进行插入操作,在另一端进行删除操作,遵循先进先出的原则。
-
顺序表的优点:
- 随机访问:可以通过下标直接访问任意位置的元素,时间复杂度为O(1)。
- 空间效率高:除了数据元素本身的存储空间外,不需要额外的空间。
- 实现简单:使用数组作为存储结构,操作简单直观。
顺序表的缺点:
- 插入和删除操作需要移动大量的元素,时间复杂度为O(n)。
- 固定大小:顺序表的大小在创建时需要确定,并且不能动态地改变大小。
-
结构体(struct)是一种用来组织不同类型数据的自定义数据类型。通过结构体,可以将多个不同类型的数据组合在一起形成一个逻辑上的整体。例如,定义一个学生结构体,可以包含姓名、年龄、性别等属性。
结构体的定义方式如下:
struct Student {char name[20];int age;char gender; }; -
typedef 是 C 语言中的关键字,用于给已有的数据类型起一个新的别名。通过 typedef,可以简化代码,并提高代码的可读性。例如,可以使用 typedef 将 int 命名为 MyInt,这样以后就可以用 MyInt 来代替 int。
typedef 的使用方式如下:
typedef int MyInt; -
在顺序表的结构体中使用 DataType 是为了方便地修改数据类型。通过在结构体中使用 DataType,可以通过修改 DataType 的定义来改变顺序表中元素的数据类型,而不需要修改顺序表的其他代码。
-
顺序表的开发步骤如下:
- 定义结构体:定义顺序表的结构体,包含存储数据的数组和记录当前元素个数的变量。
- 初始化顺序表:创建一个空的顺序表,并初始化相关变量。
- 插入操作:实现向顺序表中插入元素的操作,需要考虑插入位置、元素移动等问题。
- 删除操作:实现从顺序表中删除元素的操作,需要考虑删除位置、元素移动等问题。
- 查找操作:实现在顺序表中查找指定元素的操作,可以使用遍历或二分查找等算法。
- 销毁顺序表:释放顺序表所占用的内存空间。
二分查找算法的应用
当使用二分查找算法时,我们首先需要确定数组的起始位置(begin)和结束位置(end)。然后,通过计算中间位置(index = (begin + end) / 2),将目标数字与中间位置的元素进行比较。
- 如果目标数字小于中间位置的元素(target < nums[index]),表示目标数字在数组的前半部分,更新结束位置为 index - 1。
- 如果目标数字大于中间位置的元素(target > nums[index]),表示目标数字在数组的后半部分,更新起始位置为 index + 1。
- 如果目标数字等于中间位置的元素(target == nums[index]),表示找到了目标数字,返回 index 作为结果。
上述步骤会在一个循环中不断执行,直到起始位置大于结束位置(begin > end)。这表示目标数字不在数组中,此时返回 -1。
int binarySearch(int nums[], int length, int target) {int index = 0, begin = 0, end = length - 1;// 使用 do-while 循环确保至少查找一次do {index = (begin + end) / 2; // 计算中间位置if (target < nums[index]) {// 目标在前面,更新结束位置end = index - 1;} else if (target > nums[index]) {// 目标在后面,更新起始位置begin = index + 1;} else {// 找到目标数字,返回下标break;}} while (begin <= end);if (begin > end) {// 目标数字不存在于数组中index = -1;}return index;
}
在主函数中,我们创建了一个示例数组nums和要查找的目标数字target。然后调用binarySearch函数,并根据返回结果打印相应的信息。
int main() {int nums[9] = {1, 3, 4, 5, 6, 8, 12, 14, 16};int target = 14;int index = binarySearch(nums, 9, target);if (index == -1) {printf("%d在数组中不存在!", target);} else {printf("%d在数组中的下标是:%d", target, index);}return 0;
}
当运行代码时,如果目标数字存在于数组中,将打印出目标数字在数组中的下标;如果目标数字不存在于数组中,将打印出不存在的提示信息。
#include <stdio.h>
#include <string.h>
struct Student {int id;int age;char name[11];//赋值 strcpy
} lisi;//全局变量
void method1() {printf("%d %d %s \n", lisi.id, lisi.age, lisi.name);
}
void printMsg(struct Student stu) {printf("%d %d %s \n", stu.id, stu.age, stu.name);
}
int main() {printf("演示结构体:\n");//声明结构体变量//struct 结构体名 变量名;struct Student zhangsan;zhangsan.id = 1;zhangsan.age = 18;strcpy(zhangsan.name, "张三");printf("%d %d %s \n", zhangsan.id, zhangsan.age, zhangsan.name);lisi.id = 2;lisi.age = 28;strcpy(lisi.name, "李四");printf("%d %d %s \n", lisi.id, lisi.age, lisi.name);method1();printf("--------------------------------\n");printMsg(zhangsan);printMsg(lisi);return 0;
}```c
#include <stdio.h>
struct Student {int id;int age;
} lisi;//全局变量
//Type Define
typedef struct Teacher1 {int id;int age;
} Teacher2;
typedef struct {int id;int age;
} Teacher3;
void method1(struct Teacher1 t1, Teacher2 t2, Teacher3 t3) {}
int main() {printf("演示结构体:\n");struct Student zhangsan;struct Teacher1 lisi;Teacher2 wangwu;zhangsan.id = 10;lisi.id = 10;wangwu.id = 10;return 0;
}如何定义结构体类型、使用typedef创建别名以及包含头文件
#include <stdio.h>
//告诉编译器,本文件DataType是int类型
typedef struct {int id;int age;
} Student;
typedef Student DataType;
#include "SequenceTable.h"int main() {printf("存储字符串苹果!\n");return 0;
}#include <stdio.h>
//告诉编译器,本文件DataType是int类型
typedef int DataType;
#include "SequenceTable.h"int main() {printf("存储int书本类型!\n");return 0;
}typedef struct {DataType list[20];int length;//当前有多少个元素
} SequenceTable;//顺序表
void add() {}
void update() {}
如何使用顺序表
#include <stdio.h>
//1 定义处理的数据类型
typedef char DataType;
//2 定义处理数据的最多个数
#define MaxLength 10
//3 包含顺序表头文件
#include "SeqList.h"
int main() {printf("Hello, World!\n");return 0;
}
顺序表的初始化、插入、删除和清空
#include <stdio.h>
//1 定义处理的数据类型
typedef int DataType;
//2 定义处理数据的最多个数
#define MaxLength 15
//3 包含顺序表头文件
#include "SeqList.h"void printList(SeqList L) {printf("顺序表现有数据为%d个:\n", L.length);printf("下标:\t");for (int i = 0; i < L.length; ++i) {printf("%d \t", i);}printf("\n数据:\t");for (int i = 0; i < L.length; ++i) {printf("%d \t", L.list[i]);}printf("\n");
}
int main() {int type = 0;int value1, index;SeqList seqList;ListInitiate(&seqList);for (int i = 1; i < 10; ++i) {ListAdd(&seqList, i);}printf("顺序表初始化完毕!\n");printList(seqList);do {printf("/*******************顺序表演示****************************/\n");printf("/* 1 显示所有元素 */\n");printf("/* 2 向最后插入元素 */\n");printf("/* 3 向指定位置插入元素 */\n");printf("/* 4 删除指定位置元素 */\n");printf("/* 5 清空顺序表 */\n");printf("/* 0 退出 */\n");printf("/*****************************************************/\n");printf("请选择操作:\n");scanf("%d", &type);switch (type) {case 1:printList(seqList);break;case 2:printf("请输入要插入的数值:\n");scanf("%d", &value1);if(ListAdd(&seqList, value1) == 1) {printf("插入成功!\n");} else {printf("插入失败!\n");}break;case 3:printf("请输入要插入的数值:\n");scanf("%d", &value1);printf("请输入要插入的位置:\n");scanf("%d", &index);if(ListInsert(&seqList, index, value1) == 1) {printf("插入成功!\n");} else {printf("插入失败!\n");}break;case 4:printf("请输入要删除元素的位置:\n");scanf("%d", &index);if(ListDelete(&seqList, index, &value1) == 1) {printf("删除成功,删除的元素值为:%d!\n", value1);} else {printf("删除失败!\n");}break;case 5:break;}} while (type != 0);return 0;
}int main1() {printf("顺序表方法演示!\n");SeqList seqList;//因为是按地址传递,所有变量加&取地址符ListInitiate(&seqList);//1 初始化 按值传递printf("l = %d \n", seqList.length);printf("l = %d \n", ListLength(seqList));//添加到最后int o1 = 95; DataType o2 = 27;int result = ListAdd(&seqList, o1);printf("result = %d\n", result);printf("result = %d\n", ListAdd(&seqList, o2));return 0;
}
顺序表(SeqList)的实现,用于存储数据元素
typedef struct {DataType list[MaxLength];//1 存储数据的具体数组int length; //2 当前的元素个数
} SeqList;
//0 错误写法,按值传递,形参L值改变,不会修改实参的值
void ListInitiate2(SeqList L) {L.length = 0;//默认0个元素
}
//1 初始化:因为需要修改实参的数值,所以形参按地址传递
void ListInitiate(SeqList *L) {//(*L).length = 0;//原始写法L->length = 0;//默认0个元素 精简写法
}
//2 返回当前元素个数
int ListLength(SeqList L) {return L.length;
}
//3 添加数据元素到最后
//返回1 添加成功 0 添加失败
int ListAdd(SeqList *L, DataType o) {//objectif(L->length == MaxLength) {//已经满了printf("元素已满,添加失败!");return 0;}L->list[L->length] = o;//把元素放入空位置L->length++;//长度加1return 1;
}
//4 插入数据元素到指定位置
int ListInsert(SeqList *L,int i, DataType o) {if(L->length == MaxLength) {printf("元素已满,添加失败!");return 0;}if(i < 0 || i > L->length) {//1) 范围是否正确printf("位置错误,插入失败!");return 0;}if(i == L->length) {//2)如果位置刚好是最后L->list[L->length] = o;//把元素放入空位置} else {//3)不是最后,需要后移for (int j = (L->length - 1); j >= i; --j) {//元素后移L->list[j + 1] = L->list[j];}L->list[i] = o;//新元素插入i的位置}L->length++;//长度加1return 1;
}
//5 删除指定位置的数据元素,把删除的元素带出去
int ListDelete(SeqList *L, int i, DataType *o) {//1) 范围是否正确if(i < 0 || i >= L->length) {printf("删除失败,下标为%d的元素不存在!", i);return 0;}*o = L->list[i];//2) 得到要删除的元素的值for (int j = i + 1; j <= L->length - 1; ++j) {//3) 前移L->list[j - 1] = L->list[j];}L->length --;//4)长度减1return 1;
}
//6 将已知的线性表 L 置为空表。
void ClearLis(SeqList *L) {L->length = 0;
}
//7 得到指定位置的数据元素
int ListGet(SeqList *L, int i, DataType *o) {//1) 范围是否正确if(i < 0 || i >= L->length) {printf("错误,下标为%d的元素不存在!", i);return 0;}*o = L->list[i];//2) 得到元素的值return 1;
}这篇关于[数据启示录 01] 线性表及其实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







