本文主要是介绍End-to-End Reconstruction-Classification Learning for Face Forgery Detection,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、研究背景
现有模型主要通过提取特定的伪造模式进行深度伪造检测,导致学习到的表征与训练集中已知的伪造类型高度相关,因此模型难以泛化到未知的伪造类型上使用。
二、研究动机
1.真实样本的特征分布相对更为紧凑,因此学习真实人脸之间的共同特性比学习训练集呈现出的过拟合伪造特性更为合适。
2.为习得真实人脸与伪造人脸的本质区别,需要提高对伪造线索的推理能力。
3.不同的伪造技术会产生不同尺度的伪造痕迹,因此需要设置多尺度机制。
4.伪造区域会产生重构差异,因此可利用重构差异引导分类学习。
5.伪造线索往往出现在连续区域,因此在对信息进行聚合时需要保持空间一致性( N \mathcal{N} N)。
6.经过损失的约束,decoder层也具有鉴别性信息,因此可以用decoder特征对encoder特征进行丰富。
三、研究目标
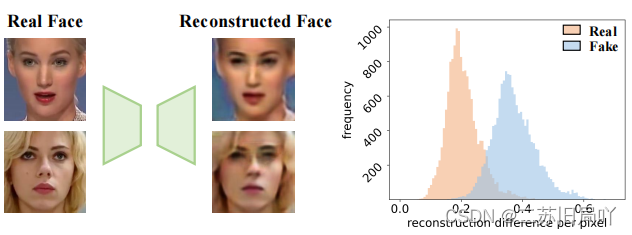
只对真实样本进行重建学习以习得真实图像的紧凑表示,通过真实人脸与伪造人脸在分布上的重构差异进行伪造检测。
四、技术路线
提出基于重构-分类学习的伪造检测框架,着重学习真实人脸的紧凑表征,一从真实人脸中区分出未知模式的伪造人脸。
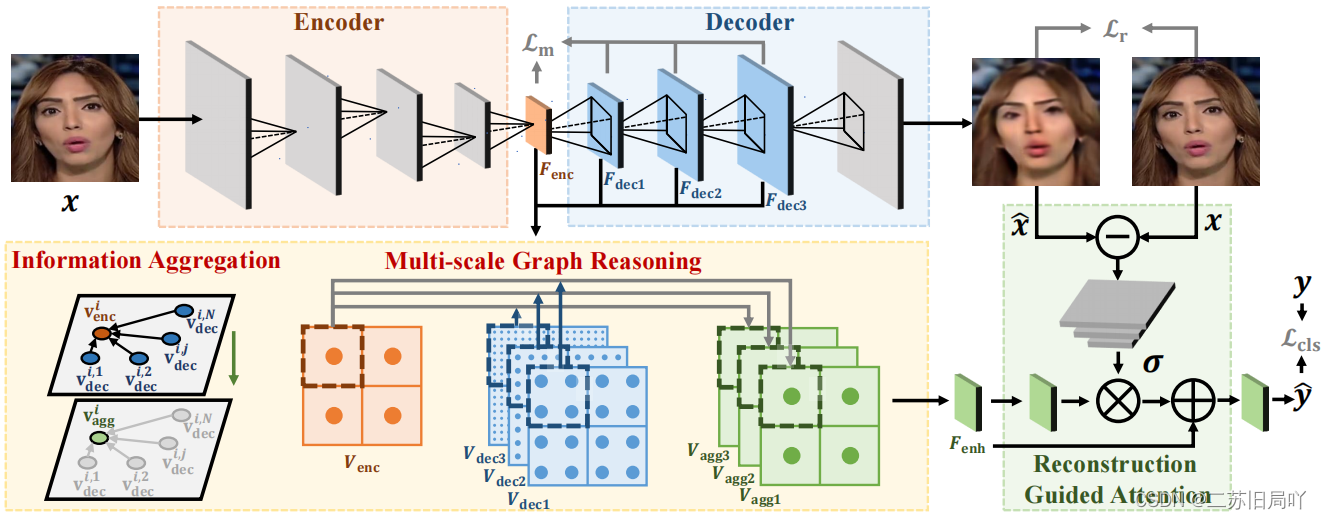
1.重建学习:通过重建学习建模真实人脸的分布,以此发现未见的伪造模式。构建度量学习损失,增加重建区分度。
- 重建真实图片

- 计算重建损失
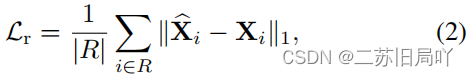
- 计算度量学习损失:增强真实样本类内紧凑性和真假样本样本类间区分性,促进重建学习。
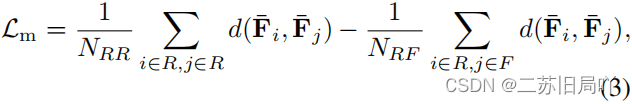
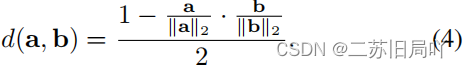
2.多尺度图推理:在编码器与解码器之间构建双向图以聚合编码器输出和解码器特征,促进完整表征的学习,挖掘本质的鉴别性特征。
- 计算不同 d d e c i , j d^{i,j}_{dec} ddeci,j结点的重要性权重: N \mathcal{N} N为一组与 e e n c i e^i_{enc} eenci相关的 e d e c i , j e^{i,j}_{dec} edeci,j结点。
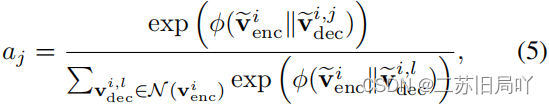
- 聚合特征: ψ \psi ψ计算 v ~ d e c i , j \tilde{v}^{i,j}_{dec} v~deci,j的丰富程度,丰富程度越小的通道拥有更大的权重(1- ψ \psi ψ)。
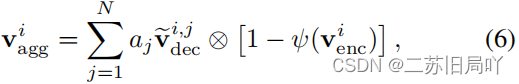
- 拼接 v a g g i v^i_{agg} vaggi与编码器输出 v e n c i v^i_{enc} venci得到 v e n h i v^i_{enh} venhi
- 聚合 v e n h i v^i_{enh} venhi得到增强后的特征图 F e n h F_{enh} Fenh
3.重建引导注意力:利用重构差异引导网络关注伪造痕迹。
- 计算输入图片与重建图片的像素级差异

- 根据差异计算注意力图,并将注意力图作用于增强后的特征图,最后做残差连接
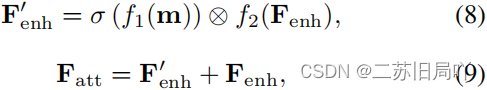
4.损失函数
![]()
五、实验结果
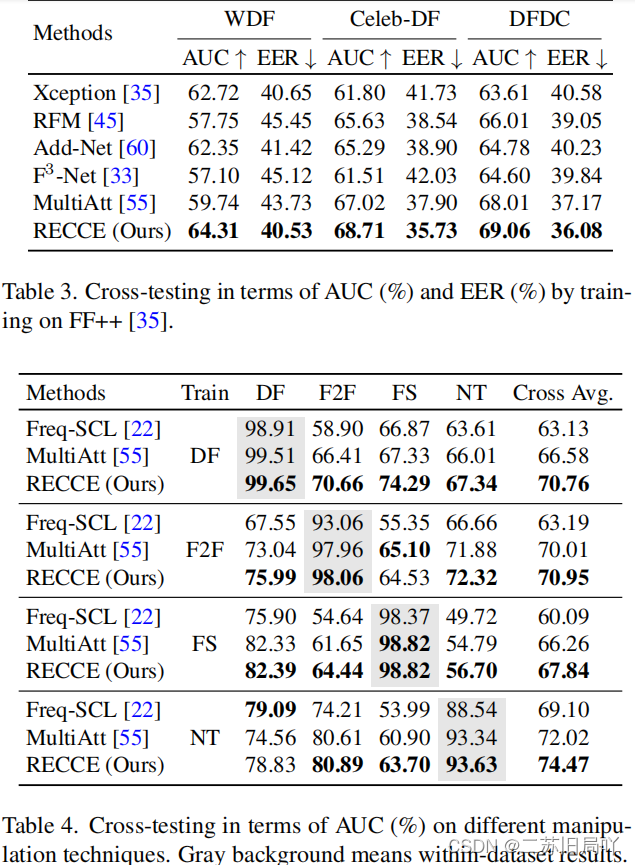
这篇关于End-to-End Reconstruction-Classification Learning for Face Forgery Detection的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








