本文主要是介绍[论文阅读]PKD——基于Pearson相关系数的目标检测器通用蒸馏框架,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
PKD
General Distillation Framework for Object Detectors via Pearson Correlation Coefficient
基于Pearson相关系数的目标检测器通用蒸馏框架
论文网址:PKD
创新点
1.提出FPN特征模仿适用于异构检测器对。之前的工作大多只考虑同质检测器对,很少研究异构情况。
2.指出直接最小化特征图之间的均方误差存在问题,如教师和学生特征幅值不同、FPN不同级别和通道存在主导特征等。
3.提出用Pearson相关系数进行特征模仿,可以关注特征之间的关系信息,而不受幅值的约束。并证明这与高温度下的KL散度最小化等价。
4.在多个检测器和数据集上进行了大量实验,结果显示该方法可以显著提升性能,并且收敛速度快,对超参数不敏感。
具体蒸馏过程
1.获取教师网络和学生网络的多尺度特征图,例如从FPN的P3到P7。
2.对每一个特征图进行归一化,使其均值为0,方差为1。这样可以消除不同特征图之间的量纲差异。
3.计算教师和学生特征图之间的Pearson相关系数,然后将1减去相关系数作为损失函数,最小化这个损失函数。
4.重复上述步骤,通过反向传播更新学生网络的参数,使其特征图与教师网络特征图之间的相关性最大化。
5.同时结合检测网络正常的监督学习损失,最终获得一个蒸馏后的学生检测网络。
具体来说,设教师网络第l层特征为t,学生网络对应层特征为s,则Pearson相关系数定义为:r(s, t) = (s - μ_s)⊤(t - μ_t) / (||s - μ_s|| ||t - μ_t||),这里μ表示均值向量,||·||表示L2范数。通过归一化可以去除量纲影响。然后损失函数为:L = 1 - r(s, t),最小化这个损失函数就是最大化特征图之间的相关性。
摘要
知识蒸馏(KD)是一种广泛使用的技术,用于在目标检测中训练小模型。然而,目前还缺乏关于异构检测器之间如何进行蒸馏的研究。本文凭经验发现,尽管学生的检测头和标签分配不同,但来自异构教师检测器的更好的 FPN 特征可以帮助学生。然而,直接将特征图与蒸馏检测器对齐会遇到两个问题。首先,教师和学生之间特征量级的差异可能会对学生施加过于严格的约束。其次,教师模型中具有较大特征量级的 FPN 阶段和通道可能会主导蒸馏损失的梯度,这将压倒 KD 中其他特征的影响并引入大量噪声。为了解决上述问题,本文建议用Pearson相关系数来模仿特征,以关注来自教师的关系信息,并放松对特征大小的限制。
引言
知识蒸馏(KD)是一种广泛使用的技术,用于在目标检测中训练紧凑模型。然而,目前还缺乏关于异构检测器之间如何进行蒸馏的研究。大多数先前的工作[Distilling object detectors with fine-grained feature imitation, Distilling object detectors with task adaptive regularization, General instance distillation for object detection, Knowledge distillation for object detection via rank mimicking and prediction-guided feature imitation, Distilling object detectors via decoupled features]依赖于特定于检测器的设计,并且只能应用于同构探测器。 [Focal and global knowledge distillation for detectors, Distilling object detectors with feature richness]对具有异构骨干的检测器进行了实验,但是具有异构检测头和不同标签分配的检测器总是被忽略。目标检测正在迅速发展,性能更好的算法不断被提出。然而,在实际应用中,频繁更换检测器对于稳定性而言并不容易。此外,在某些场景下,由于硬件限制,只能部署特定架构的检测器(例如,两阶段检测器很难部署),而大多数强大的教师都属于不同的类别。因此,如果能够在异构检测器对之间进行知识蒸馏,这是有希望的。此外,当前的蒸馏方法,例如[Focal and global knowledge distillation for detectors, Improve object detection with feature-based knowledge distillation],通常引入几个互补的损失函数来进一步提高其性能,因此使用几个超参数来调整每个损失函数的贡献,这严重影响了它们转移到其他数据集。
本文首先凭经验验证 FPN 特征模仿可以成功地提取知识,即使学生-教师检测器对是异构的。然而,直接最小化教师和学生特征之间的均方误差(MSE)会导致次优结果。[Learning efficient object detection models with knowledge distillation, Distilling object detectors via decoupled features, Distilling object detectors with feature richness, Focal
and global knowledge distillation for detectors]中得出了类似的结论。为了探索 MSE 的局限性,我们精心可视化了教师和学生检测器的 FPN 特征响应,如图 1 所示。具体来说,对于第 l 个 FPN 阶段的输出特征 sl ∈ RC×H×W,我们选择每个像素处 C 维的最大值并获得二维矩阵。然后我们根据 l 个二维矩阵的最大值和最小值将值标准化为 0-255。通过这些比较,本文得到以下观察结果:
- 教师和学生的特征值大小不同,特别是对于异构检测器
- 几个 FPN 阶段的值比其他阶段大
- 某些通道的值明显大于其他通道
根据这些观察,本文提出了如图下所示的Pearson系数(PKD)的知识蒸馏,其重点关注教师和学生特征之间的线性相关性。为了消除不同 FPN 阶段和通道之间师生检测器对之间以及检测器内的幅度差异的负面影响,首先对特征图进行归一化,使其均值和单位方差为零,并最小化归一化特征之间的 MSE 损失。从数学上讲,相当于首先计算两个原始特征向量之间的pearson相关系数(r),然后使用 1 − r 作为特征模仿损失。
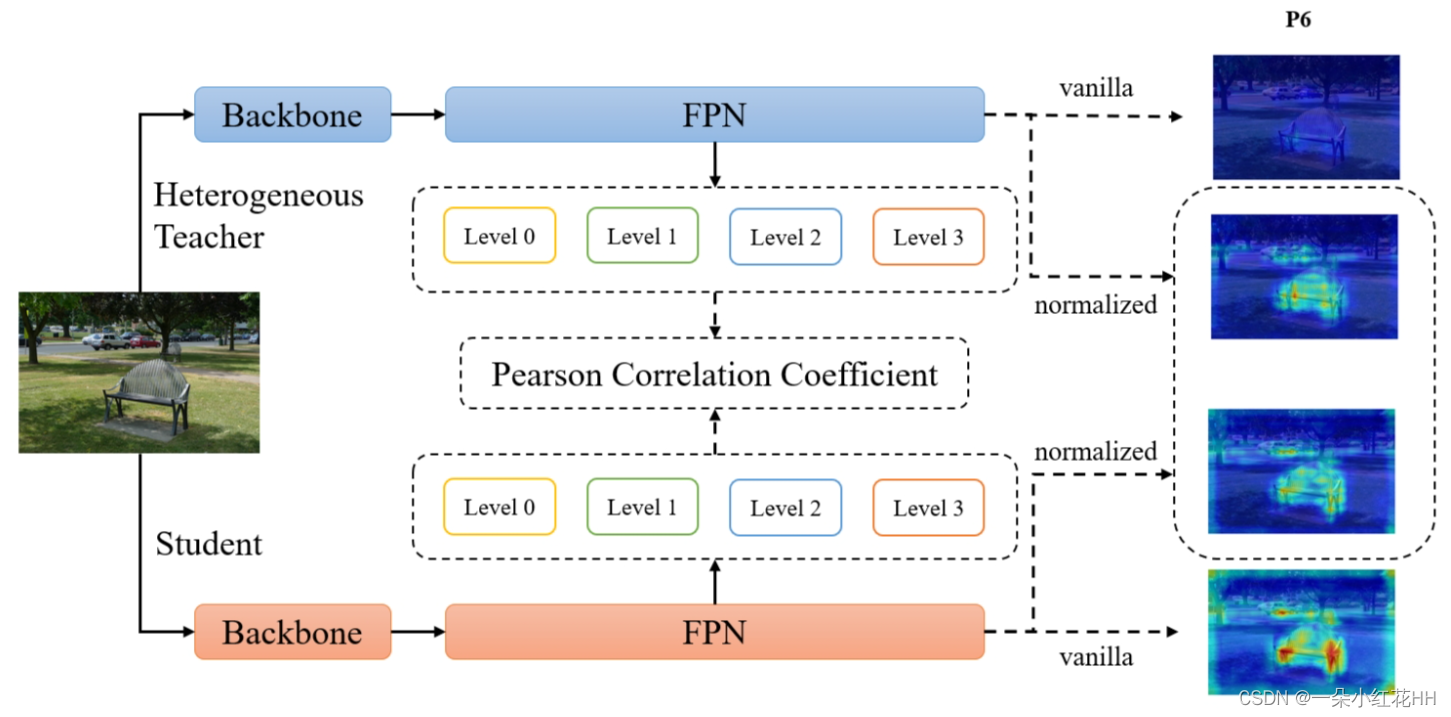
与以前的方法相比,本文的方法具有以下优点。首先,由于蒸馏损失仅根据 FPN 特征计算,因此它可以轻松应用于异构检测器对,包括具有异构主干、异构检测头和不同训练策略(例如标签分配)的模型。其次,由于不需要训练教师的检测头,因此可以显著减少训练时间,特别是对于那些具有级联头的模型。此外,PKD 比以前的方法收敛得更快。最后也很重要的一点是,它只有一个超参数——蒸馏损失权重,并且对此不敏感。因此它可以很容易地应用于其他数据集。本文进行了大量的实验来验证本文的方法在 COCO 数据集上带来的显着性能提升 。使用与老师相同的两阶段检测器,基于 ResNet50 的 RetinaNet 和 FCOS 实现了 41.5% mAP 和 43.9% mAP,分别超出基线 4.1% 和 4.8%。
贡献:
- 本文认为,即使学生-教师检测器对是异构的,FPN 特征模仿也可以成功地提取知识。
- 本文建议用 PCC 来模仿 FPN 特征,以关注关系信息并放宽学生特征大小的分布约束。它能够提取同构和异构检测器对的知识。
- 通过 COCO 上的大量实验验证了本文的方法在各种探测器上的有效性,并在没有花哨的情况下实现了最先进的性能。此外,本文的方法收敛速度更快,并且对唯一一个超参数蒸馏损失权重不敏感,简单而有效。
相关工作
目标检测
目标检测被认为是最具挑战性的视觉任务之一,旨在检测图像中某一类的语义对象。检测器大致分为两阶段探测器和一阶段探测器。在两阶段检测器中,通常采用区域提议网络(RPN)来生成用于特定任务的检测头细化的初始粗略预测。一个典型的例子是 Faster R-CNN。相比之下,RetinaNet 和 FCOS 等单级检测器可以直接、密集地预测输出特征图上的边界框。在这些工作中,通常采用多尺度特征来处理各种尺度的对象,例如FPN。所提出的 PKD 仅提取中间特征,不依赖于特定于检测器的设计,因此可以直接在各种检测器上使用。
知识蒸馏
知识蒸馏(KD)是一种模型压缩和加速方法,旨在将知识从教师模型转移到学生模型。它由[Distilling the knowledge in a neural network]推广,随后的工作[Fitnets, Like what you like, Knowledge transfer via distillation of activation boundaries formed by hidden neurons, Variational information distillation for knowledge transfer, A gift from knowledge distillation, Relational knowledge distillation, Knowledge distillation via instance relationship graph, Contrastive representation distillation, Similarity-preserving knowledge distillation]探索了它在图像分类中的有效性。然而,使 KD 适应目标检测器并非易事,因为最小化分类头输出之间的 Kullback-Leibler (KL) 散度无法传输来自教师的空间信息,并且只能为学生带来有限的性能增益。先前的检测方法通常采用以下三种策略来应对上述挑战。首先,蒸馏通常在多尺度中间特征之间进行[Mimicking very efficient network for object detection],这为检测提供了丰富的空间信息。其次,提出了不同的特征选择方法来克服前景背景不平衡。这些工作大多数可以根据特征选择方法分为三类[Instance-conditional knowledge distillation for object detection]:基于提案的,基于规则的和基于注意力的。第三,由于不同对象之间的关系包含有价值的信息,许多先前的工作试图通过使检测器能够捕获和利用这些关系来提高检测器的性能,例如非局部模块[ Improve object detection with feature-based knowledge distillation]和全局蒸馏[Focal and global knowledge distillation for detectors]。
与之前的工作不同,本文将幅度差异、占主导地位的 FPN 阶段和通道视为关键问题。本文希望本文的方法可以作为一个坚实的基线,并有助于简化目标检测器知识蒸馏的未来研究。
Method
Preliminaries
目标检测的传统知识蒸馏。最近,采用基于多尺度特征的特征蒸馏来处理丰富的空间信息以进行检测。提出了不同的模仿掩模M来形成前景特征的注意机制并滤除背景中的噪声。目标可以表述为:
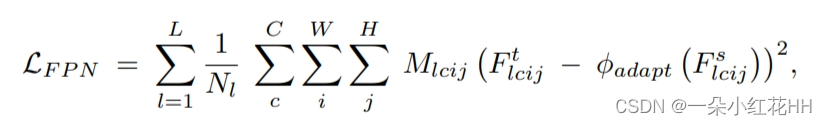
其中L是FPN层数,l表示第l个FPN层。Ft l 和 Fs l 分别是学生和教师检测器的第 l 层特征。函数 φadapt 是一个 1x1 卷积层,用于在教师和学生之间的通道数不匹配时对学生网络的通道数进行上采样。
这些方法中M的定义是不同的。例如,FRS使用来自相应 FPN 层的聚合分类得分图,而 FGD同时考虑空间注意力、通道注意力、对象大小和前景-背景信息。
Is FPN feature imitation applicable for heterogeneous detector pairs?
之前的大部分工作都是在 FPN 上进行蒸馏,因为 FPN 集成了多个主干层并提供了多尺度对象的丰富空间信息。强迫学生模仿同构教师的 FPN 特征是合理的,因为他们具有相同的检测头和标签分配,并且更好的特征可以带来更好的性能。然而,目前还缺乏关于异构检测器之间如何进行蒸馏的研究。 [Focal and global knowledge distillation for detectors, Distilling object detectors with feature richness]对具有异构主干的检测器进行了实验,但是具有异构检测头和不同标签分配的检测器总是被忽略。因此,本文有动力研究 FPN 特征模仿对于这些异构检测器对是否仍然有意义。
本文在三种流行的检测器上进行了骨干和颈部替换实验:GFL 、FCOS 和 RetinaNet 。首先,用经过良好训练(经过 12 epochs)的 GFL 的骨干和颈部替换 FCOS 的骨干和颈部。由于基于特征的蒸馏方法的主要思想是直接对齐教师和学生的特征激活,因此可以将其视为 FCOS 和 GFL 之间 FPN 特征模仿的极端情况。然后用FCOS更换的 GFL 骨干和颈部对 FCOS 头部进行微调。实验显示,通过更换GFL的骨干和颈部,探测器获得了更高的性能(从36.5到37.6)。一定程度上验证了FPN特征模仿在异构检测器之间的适用性。相比之下,将 RetinaNet 的主干和颈部替换为 FCOS 训练有素(经过 12 个 epoch)的主干和颈部。由于 FCOS 头部中的组归一化导致两个模型之间的特征值幅度差异,可以观察到显着的 mAP 下降(从 36.3 到 35.2)。这意味着特征值大小差异可能会干扰两个异构检测器之间的知识蒸馏。
使用pearson相关系数进行特征模仿
一种有前景的特征蒸馏方法在将它们构建成对进行模仿时需要考虑数量级差异。此外,本文发现主要的 FPN 阶段和通道会对学生的训练阶段产生负面干扰,并导致次优结果,而这一点被以前的工作所忽略。
为了解决上述问题,本文建议首先将教师和学生的特征归一化,使其均值和单位方差为零,并最小化归一化特征之间的 MSE。此外,希望归一化遵循卷积属性 - 以便同一特征图的不同元素在不同位置以相同的方式归一化。令 B 为特征图中跨小批量元素和空间位置的所有值的集合。因此,对于大小为 b 的小批量和大小为 h ×w 的特征图,使用大小为 m = ||B|| = b · hw 的有效小批量。令 s© ∈ Rm 为一批 FPN 输出的第 c 个通道,为了清楚起见,省略 c。然后分别从学生和老师那里得到标准化值 ˆs1…m 和 ˆt1…m 而不是精心设计等式1中的仿掩模M. 选择重要的特征,benwen 的PKD在完整的特征图上运行。也就是说,仿掩模 M 填充了标量值 1。因此可以将蒸馏损失公式如下:
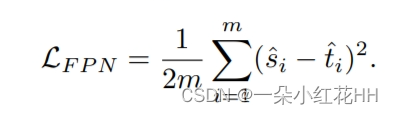
最小化上面的损失函数相当于最大化学生和教师的预归一化特征之间的 PCC。 PCC 可以计算为:
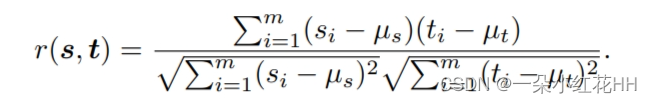
Pearson 相关系数本质上是协方差的归一化测量,因此结果始终具有介于 -1 和 1 之间的值。因此,LFPN = 1 − r 始终具有介于 0 和 2 之间的值。它侧重于教师和学生的特征,并放宽对特征大小的限制。实际上,特征图 s, t ∈ Rm 可以被视为 m 个数据点 (si, ti)。 LFPN = 0 意味着所有数据点都位于 s 随着 t 增加而增加的线上。因此,该学生训练有素。 LFPN = 2 时反之亦然。值为 1 意味着学生和教师的特征之间不存在线性相关性。
在训练期间,PCC 的梯度,∂L/∂si,相对于每个 FPN 输出 si,由下式给出:
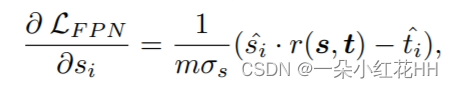
总之,PCC关注来自教师的关系信息,放宽了对学生特征大小的分布约束。此外,它消除了主要 FPN 阶段和通道的负面影响,从而带来更好的性能。因此,规范化机制弥合了学生和教师激活模式之间的差距。因此,PCC 的特征模仿适用于异构检测器对。本文用总损失训练学生检测器如下:
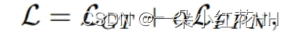
其中LGT是检测训练损失,α是平衡检测训练损失和蒸馏损失的超参数。
PCC和KL散度的连接
规范化机制是解决上述三个问题的关键。在之前的工作中,KL散度已广泛应用于蒸馏中。他们首先使用 softmax 函数将激活转换为概率分布,然后最小化归一化激活图的不对称 KL 散度。
在这里,实验表明,在高温极限下最小化归一化特征之间的 KL 散度相当于最小化归一化特征之间的 MSE,因此相当于最大化原始特征之间的 PCC。
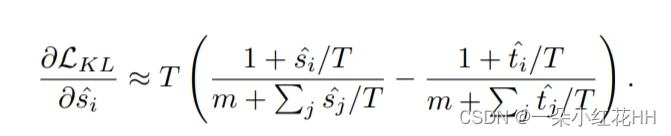
结论
本文根据经验发现 FPN 特征模仿适用于异构检测器对,尽管它们的检测头和标签分配不同。然后,提出使用pearson相关系数的特征模仿,以关注来自教师的相关信息,并放松学生特征值大小的分布约束。此外,还提出了一个通用的 KD 框架,能够提取同构和异构检测器对的知识。它收敛速度更快,并且只引入一个超参数,可以轻松应用于其他数据集。然而,本文对提出的 PKD 是否能够执行文本识别等其他任务的理解还处于初步阶段,留待未来的工作。
这篇关于[论文阅读]PKD——基于Pearson相关系数的目标检测器通用蒸馏框架的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







