本文主要是介绍2002-2021年全国各地级市环境规制18个相关指标数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2002-2021年全国各地级市环境规制18个相关指标数据
1、时间:2002-2021年
2、来源:城市年鉴
3、指标:行政区划代码、地区、年份、工业二氧化硫排放量(吨)、工业烟粉尘排放量(吨)、工业废水排放量(万吨)、工业废水排放达标量(万吨)、工业二氧化硫去除量(吨)、工业烟尘去除量(吨)、工业二氧化硫产生量(吨)、工业烟粉尘去除量(吨)、工业氮氧化物排放量(吨)、生活污水处理率(%)、生活垃圾无害化处理率(%)、工业固体废物综合利用率(%)、一般工业固体废物综合利用率(%)、污水处理厂集中处理率(%)、可吸入细颗粒物年平均浓度(微克/立方米)
4、缺失情况说明:缺失情况参看下文链接内数据预览,缺失值已标黄:
链接:https://pan.baidu.com/s/1zw1DW-ytgq5JYmQT-jNMKQ
提取码:n96h
5、用途:可用于衡量地级市环境污染排放水平及环境规制效果。
6、下载链接:
2002-2021年全国各地级市环境规制18个相关指标数据![]() https://download.csdn.net/download/m0_71334485/88561800
https://download.csdn.net/download/m0_71334485/88561800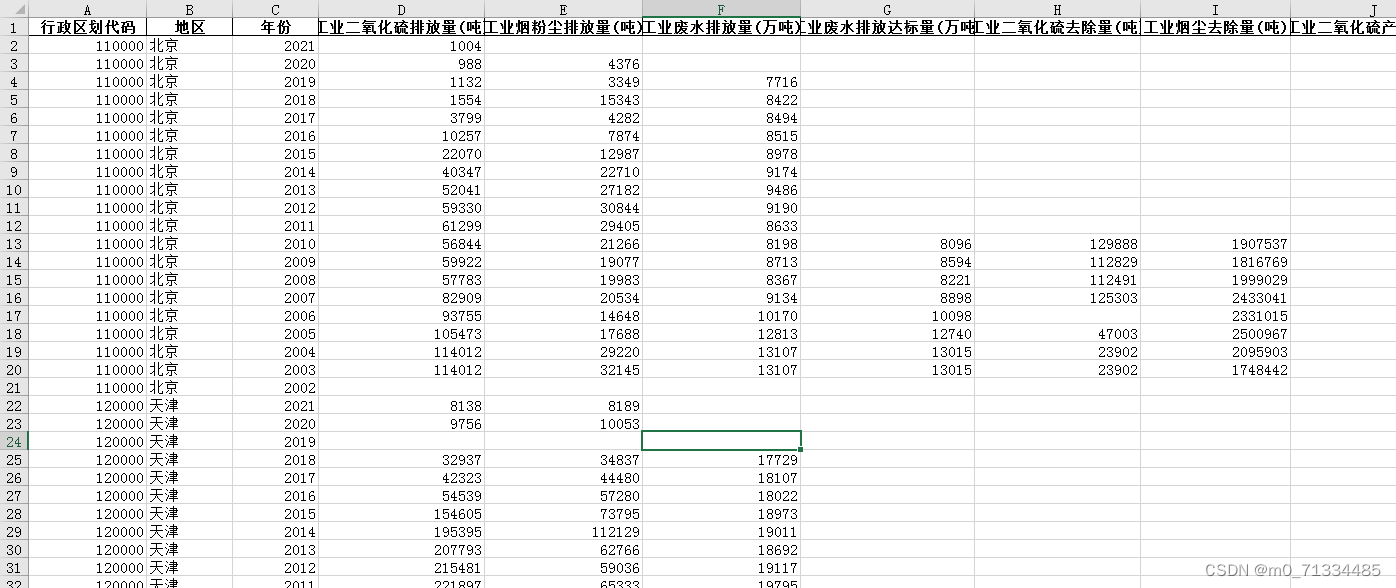
这篇关于2002-2021年全国各地级市环境规制18个相关指标数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





