本文主要是介绍论文阅读:MIL-VT: Multiple Instance LearningEnhanced Vision Transformer for FundusImage Classification,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Abstract
本文尝试将Vision Transformer用于视网膜疾病分类任务,通过在大型眼底图像数据库上预先训练变换器模型,然后对下游的视网膜疾病分类任务进行微调。 此外,为了充分利用单个图像块提取的特征表示,我们提出了一种基于多实例学习(MIL)的“MIL head”,它可以方便地以即插即用的方式附加到视觉转换器上,有效地提高了下游眼底图像分类任务的模型性能。
Introduction
(无用)介绍Vision Transformer由NLP到CV的简要情况。
(提出问题一)在医学图像领域应用Transformer的一大痛点在于缺少大量的有标注的数据集。
(提出问题二)单个patch的特征表示是否有助于提高分类性能。
(贡献)本文旨在解决上述两个问题,将Vision Transformer引入医学图像分类任务中,充分利用单个图像块的特征表示。 本文的主要贡献有两个方面。 首先,探讨了Transformer模型在眼底图像视网膜疾病分类中的适用性,这是首次将Vision Transformer用于医学图像分类任务的尝试。 我们用一个大型眼底数据库对Transformer模型进行了预训练,在下游视网膜疾病分类任务中进行微调时,大大提高了模型的性能。 其次,通过引入一个多实例学习头(MIL Head)来充分利用从单个贴片中提取的特征,使这些特征可以方便地以即插即用的方式附加到现有的Vision Transformer中,有效地提高了模型的性能。 最后,将实现代码和预训练权值发布给公众,以促进眼底图像相关任务的视觉变压器的进一步研究。
Method
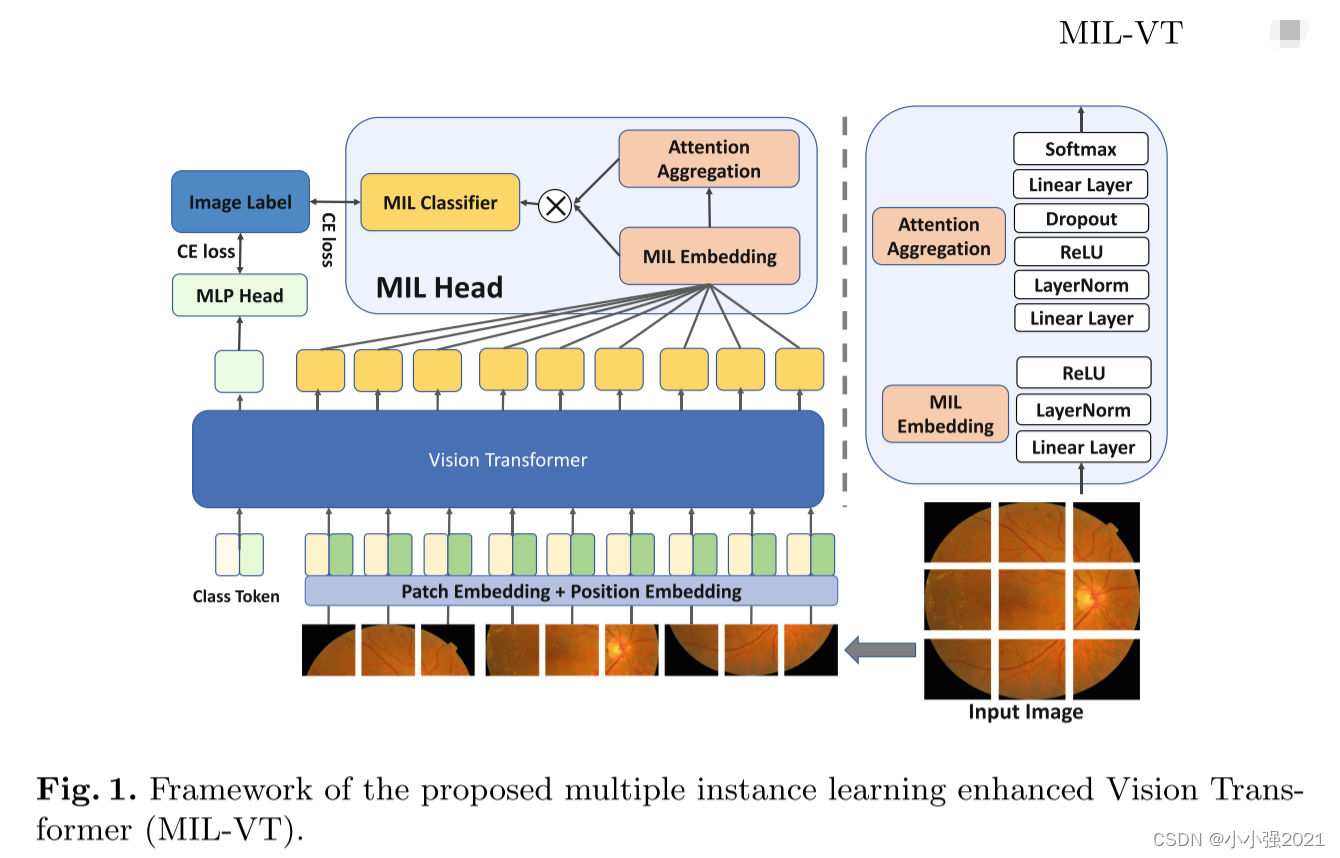
图1显示了所提出的多实例学习增强视觉变压器网络(MIL-VT)的总体框架。 VIT只利用类别令牌的特征表示来进行分类,我们提出了一种新的MIL头来充分利用单个图像块提取的特征。 所提出的“MIL头”基于多实例学习范式,可以方便地以即插即用的方式附加到现有的Vision Transformer结构上,以提高模型的性能。
Vision Transformer
本研究中使用的Vision Transformer的结构与VIT相同,是一种纯基于转换器的结构,没有任何卷积层。 经典的Transformer结构最初是为NLP任务设计的,它以字符或单词的嵌入作为输入,而不是图像。 为了制备与视觉转换格式兼容的眼底图像数据,将输入图像x∈RH×W×C(其中H、W和C分别表示图像的高度、宽度和彩色通道数)分成大小为P×P的单个patch,其中P设置为16。 然后我们可以从一幅图像中得到n=H*W/P*P块。 这些patch被进一步展成一维格式,然后通过线性层嵌入到D维,这是Transformer网络的兼容数据格式。
由于patch嵌入不包含关于单个patch的空间位置的信息,因此需要对位置信息进行位置嵌入编码。 对于VIT,位置嵌入被编码为一个可学习的一维向量,并添加到patch嵌入中,以获得单个patch的最终嵌入。 在嵌入序列的开始处,除了嵌入单个块外,还添加了一个具有相应位置嵌入的可学习类标记,作为整个图像的全局特征表示。 对于DEIT[14],在图像补丁序列之前附加一个额外的可学习的蒸馏标记,以在CNN teacher model的监督下学习另一个全局特征表示。
到目前为止,原始眼底图像是以适合视觉变换的格式进行处理的,其维数为B×(n+1)×D,其中B为batch size,N为单幅图像的patch数,D为嵌入维数。 处理后的数据进一步送入Transformer编码器,其由重复的Transformer块组成。 更具体地说,每个块由多头关注(MHA)和前馈网络(FFN)组成,分别在MHA和FFN之前和之后通过跳过连接进行层归一化和残差运算。
Multiple Instance Learning
对于VIT结构,只有对应于类令牌的特征表示被馈送到多层感知器(MLP Head)用于图像的最终分类。 同时,从单个patch中提取的特征被丢弃,无法对最终分类做出贡献。 然而,单个patch可能包含重要的互补信息,这些信息被类标记的特征表示所忽略或不能完全表达,特别是关于视网膜疾病的病理可能分布在不同的位置[9],因此不同patch的贡献可能不同。 在MIL方案中,它将图像看作一个包,包由一组像素或图像patch格式的实例组成。 MIL中的包-实例关系与Vision Transformer中的图像-patch关系非常相似。 因此,在本文中,我们建议将经典的MIL公式[7,12]引入到Vision Transformer结构中,以便充分利用来自单个patch的特征。
我们将MIL方案引入VIT网络包括三个步骤,即:1)从每个patch中为VIT特征建立低维嵌入;2)通过聚合函数获得Bag表示;3)通过Bag级分类器获得最终的Bag级概率。
(1)假设单个图像中的包-实例关系表示为X={x1,x2,···,xn}。 经过Trans-
former blocks处理后,实例(图像patch)xi被编码为维数为D的特征向量Vi,即Vi=T(xi)。 通过线性层、层归一化和RELU激活,将得到的特征向量Vi转移为低维嵌入。 这个嵌入过程可以表示为:
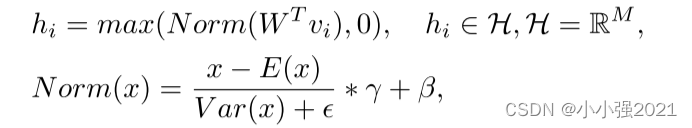
其中M是嵌入H的维数; W∈RD×M表示线性层投影运算的权重; γ和β表示层归一化操作的可学习参数。
(2)由于不同的图像patch对包的贡献不同,为了充分利用所有patch的贡献,同时区分它们的差异,我们在框架中使用了两层线性的注意力模块来提取实例嵌入的空间权重矩阵。 为了进一步归一化隐藏特征并防止潜在的过拟合,在两个线性层之间插入层归一化、RELU激活和Dropout层,如图所示 1. 此过程可以表示为
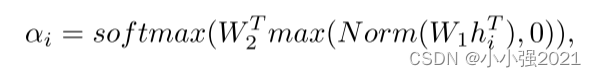
其中W1∈RL×m和W2∈RL×1是两个线性层的参数。 softmax表示softmax函数,以确保所有实例的权重总和为1。
然后,我们的聚合函数将上述关注权重分配给实例嵌入,以突出不同实例的不同贡献,并提供一种可行的端到端训练方法。 它的工作方式如下:
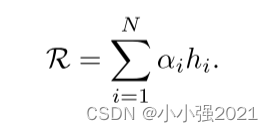
(3)聚合的包表示R进一步被输入到线性分类器中,以获得最终的包级概率,如下所示
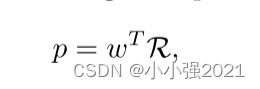
其中p为最终预测概率; W∈RL×C表示袋级分类器的参数,C表示分类器的类别数。
总而言之,经典的MIL公式是在我们的整个框架中打包和模块化的,我们在图1称之为“MIL头” 。所提出的“MIL头”可以方便地以即插即用的方式连接到视觉变压器结构上,并充分利用了单个贴片的特征表示。
Framework Pre-training and Fine-Tuning
为了提高眼底图像视觉变换器的性能,本研究利用一个大型眼底图像分类数据库对变换器结构进行预训练。 注意,在训练变压器结构时,使用来自ImageNet的预训练权值初始化模型参数,以充分利用学习到的视觉任务归纳偏差,加快训练过程。
经过预训练后,提出的MIL-VT结构在下游的眼底图像疾病分类任务上进行微调。 变压器结构可以处理任意数目的输入片,但位置嵌入需要进行插值,以处理由于图像大小与训练前大小不同而导致的较长或较短的片序列。 对于下游模型的训练,“MLP头”和“MIL头”都接受分类标签的监督,并使用交叉熵损失函数:
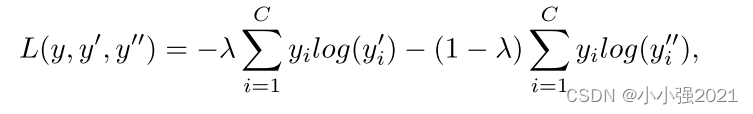
其中Y表示地面真理标签; Y'和Y''分别表示MLP头和MIL头的预测; c表示下游任务的类别数; λ是控制两个头之间相对重量的超参数,经验上设为0.5。 在推理阶段,用λ加权平均两个头的输出,得到最终的预测结果。
Experiments
为了对视觉变压器结构进行预训练,从远程眼科平台上收集了一个大型眼底图像数据集,该数据集包含总共345,271幅眼底图像。 五种常见的视网膜疾病被标记,包括正常(208,733)、糖尿病视网膜病变(DR,38,284)、老年性黄斑变性(21,962)、青光眼(24,082)和白内障(67,230)。 在同一眼底图像上可能同时出现多种视网膜疾病,因此将预训练设置为一个基于二值交叉熵损失函数的多标记分类问题。 我们随机分割95%的数据集用于训练,其余5%用于验证。 所有眼底图像调整到384×384的尺寸进行预训练。 使用ImageNet预先训练的权值初始化模型参数[5],以加快收敛速度。
对于下游任务,使用了两个公开可用的基准数据库来评估所提出的MIL-VT框架的有效性,包括APTOS2019失明检测(APTOS2019)[1]和2020视网膜眼底多疾病图像数据集(RFMID2020)[2]。 APTOS2019总共包含3662张用于DR分级的眼底图像,有5个标签类别,范围从0到4,代表DR严重程度。 RFMID2020数据集包含1900幅图像,提供了二值疾病标签:0用于正常图像,1用于病理图像。 对于这两个数据集,图像被分成5个折叠进行交叉验证,并在输入网络之前调整到512×512的尺寸。
所有实验都是在一个GPU集群上进行的,该集群有四个英伟达特斯拉P40 GPU,每个GPU有24 GB的内存。 采用ADAM优化器对模型参数进行优化,最大训练时间为30个,批量为16个。 初始学习速率设置为2×10-4,每2000次迭代减半。 在训练过程中采用了随机裁剪、旋转、水平翻转和颜色Jitting等数据增强策略,以增加训练数据的多样性。
Ablation Studies
消融研究已经进行,以评估在一个大的眼底数据集上进一步预训练的性能,与ImageNet的原始预训练相比较。 此外,通过引入“MIL头”,对所提出的MIL-VT结构的可行性进行了评估。 我们采用嵌入尺寸为384、多头数为6的VIT-Small结构和12个叠置变压器块作为实验的骨干。 消融研究在APTOS2019和RFMID2020数据集上进行。 在APTOS2019中,作为一个多类分类问题,我们使用了精确度、曲线下面积(AUC)、加权F1和加权Kappa等评价指标。 对于RFMID2020,由于它只包含疾病或正常两类,使用了AUC、准确性、F1、召回率和精确度的评估指标。
如表1和表2所示,在APTOS2019和RFMID2020的所有指标下,使用眼底数据库的进一步预训练显著提高了视觉变压器的性能。 具体而言,对于APTOS2019,DR分级的F1和Kappa指标分别提高了2.3%和2.1%。 与此同时,在RFMID2020中,通过眼底数据集的预训练,AUC提高了1.5%,F1得分提高了1.4%。
更重要的是,通过在经典视觉变压器中现有的MLP头的基础上引入MIL头,进一步提高了模型的性能。 对于APTOS2019的DR分级,F1和Kappa评分分别提高1.5%和0.9%。 同时,在RFMID2020中,在VIT结构的基础上增加了MIL头,使AUC和F1分别提高了1.4%和1.8%,最终达到AUC和F1分别提高了95.9%和94.4%的性能。 实验结果表明,所提出的MIL-HEAD算法能够充分利用单个斑块的特征表示,有效地提高现有视觉变压器的模型性能。
Comparison to State-of-the-art Methods
我们将所提出的MIL-VT框架与其他DR分级的研究工作进行了比较,包括典型的CNN模型RESNET34[6](有和没有眼底预训练)和所提出的方法。 除此之外,我们还将APTOS2019数据集的DR分级与最近的出版物进行了比较。 如表3所示,拟议的MIL-VT的加权F1和Kappa评分超过了Green[11],后者是专门为具有强大主干的DR评分设计的,是APTOS2019的当前最先进的方法。 此外,在相同的预训练设置下进行训练和测试时,所提出的MIL-VT的性能也优于RESNET34。 同样,对于表4所列RFMID2020的性能比较,所提出的MIL-VT也超过了RESNET34,表明变压器结构在适当的预训练下可以获得比CNNS更好的性能。、

Conclusion
本文探讨了Vision Transformer在视网膜疾病分类任务中的适用性,在一个大型眼底数据库上进行适当的预训练,在相同的预训练设置下,其性能优于CNN。 此外,我们提出了基于多实例学习方案的MIL-VT框架,该框架具有一个新的MIL头,以充分利用视觉转换器通常忽略的从单个斑块中提取的特征表示。 所提出的“MIL头”可以通过即插即用的方式方便地连接到现有的视觉变压器结构上,有效地提高了模型的性能。 在APTOS2019和RFMID2020眼底图像分类数据集上,与RESNET和文献中的其他比较方法相比,所提出的MIL-VT达到了最先进的性能。
这篇关于论文阅读:MIL-VT: Multiple Instance LearningEnhanced Vision Transformer for FundusImage Classification的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)