本文主要是介绍Meta开源最大多模态视频数据集—Ego-Exo4D,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
社交、科技巨头Meta联合15所大学的研究机构,经过两年多的努力发布了首个多模态视频训练数据集和基础套件Ego-Exo4D,用于训练和研究AI大模型。
据悉,该数据集收集了来自13个城市839名参与者的视频,总时长超过1400小时,包含舞蹈、足球、篮球、攀岩、音乐、烹饪、自行车维修等8大类,131个复杂场景动作。这使得AI模型更好地理解人类的行为,有助于开发出更强大的多模态大模型。

Ego-Exo4D也是目前最大的公开第一人称和第三人称视频训练集。Meta已经准备开源该数据集,最晚12月底开放下载。
Ego-Exo4D下载地址:https://ego-exo4d-data.org/
论文地址:https://ego-exo4d-data.org/paper/ego-exo4d.pdf
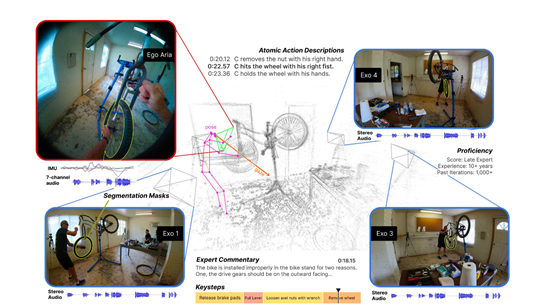
与其他视觉数据集不同的是,Ego-Exo4D最大技术特点在于数据的多模态性。基于Aria智能眼镜平台,第一人称视频带有丰富的同步录制信息,包括七通道音频、眼动追踪状态、头部运动测量(IMU)、双目RGB-D摄像视频、周围三维环境点云等。
此外,数据集中所有视频都配有三种不同的语言描述,分别是领域专家对表现的评论、参与者自身对所做活动的叙述以及第三方对各个原子操作的文字描述。
第一人称和第三人称摄像机设置
Ego-Exo4D数据集使用了一款名叫Aria的眼镜。该眼镜可以拍摄第一人称视频,记录运动员自己的视角。
同时场外还有4-5个GoPro摄像机,拍摄第三人称视频,记录教练的视角。这些摄像机使用了定制的QR码进行时间同步,确保第一人称视频和第三人称视频能精确匹配上,然后进行比较。
Aria眼镜内置丰富的传感器,提供RGB、深度、音频、IMU、眼动等多模态数据。Ego-Exo4D充分利用这些硬件优势,为每段第一人称视频同步捕获了七通道音频、眼动追踪、IMU动作数据、两个RGB-D SLAM摄像头以及周围3D点云环境。这些数据可支持多种新颖的多模态视频理解研究。
精准文本描述
Ego-Exo4D视频数据还匹配了三种不同形式的语言描述,均与视频时间轴对齐:第一是领域内资深专家对执行者表现的评价性解说,揭示非专业人士不易察觉的技巧和方法;

第二是执行者对自己所做活动的第一人称叙述;第三是外部标注人员对每个行为操作的简要文字描述。这些丰富的语言资源可以大幅推动视频理解中的语言参照和示教相关应用。
四大类基准测试
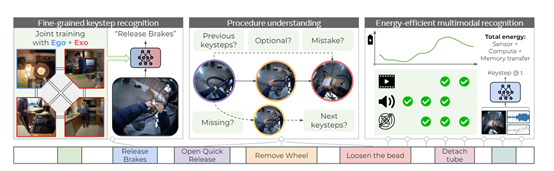
为了验证数据集的有效性,研究人员在四类基准测试上进行第一人称视频理解和多模态识别测试,用于评估在复杂视角转换、细粒度操作检测、示范者评级等方面的表现。
1)跨视角对应和迁移基准测试
该基准测试任务利用第一、三人称视频,研究跨视角的目标匹配和新视角合成问题。考察点包括:在极端视角、严重遮挡下的稀疏对应问题;合成新视角图像时运用姿态、语义先验的有效性等。
2)细粒度操作识别基准测试
该任务需要区分复杂顺序活动中语义相近的细粒度操作,如识别折叠被褥还是整理被褥。训练阶段允许使用配对的第一、三人称视频,以学习视角不变的表示。测试阶段仅给第一人称视频,考察跨视角特征迁移的效果。

3)示范者熟练度评估基准测试
这项基准测试要求对整个视频中的示范者进行整体熟练度评级,同时需要识别视频中局部段落的正确/错误执行。这可驱动人类行为质量分析以及教练系统的研究。
4)第一人称姿态估计基准测试
这项基准测试目标是从第一人称视频中恢复三维的手部和身体关键点,解决动态场景中严重遮挡、模糊、大姿态变化等难题。

结果显示,Ego-Exo4D皆获得了不错的成绩。例如,在第一人称和第三人称视角之间的目标追踪和姿态预测任务上,方法可以达到38%的平均IoU;而在识别17种顺序活动中689种细粒度操作的任务上,方法可以获得58%的准确率。
研究人员表示,传统的训练数据多数都是重复和模拟,很难让AI从更深度的角度去理解人类的行为和动作。
Ego-Exo4D提供了一个前所未有的大规模第一人称和第三人称视角视频数据集。该数据集和基准测试填补了现有数据集的空白,可推动更强的多模态大模型研究。
未来,数据集、文本标注和基准代码将完全开源以供研究人员使用。
本文素材来源Ego-Exo4D论文,如有侵权请联系删除
END
这篇关于Meta开源最大多模态视频数据集—Ego-Exo4D的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







