本文主要是介绍KNN(K近邻,K Nearest Neighbour)算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、定义:
如果一个样本在一个特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。通俗来讲,就是找出和被预测点离得最近的k个邻居,然后这k个邻居中的大多数属于哪个类别,则我们就预测这个预测点也是属于这个类别。
注意:通常我们不会将k值取1,因为有肯能那个最近邻的样本是一个异常值(点),那么预测的结果就会受到异常值的影响。
2、那么,如何确定谁是我的邻居呢?
既然要判定谁是我的邻居,那就要计算距离,计算距离的公式有很多,常用的并且好理解的有:欧式距离,曼哈顿距离
2-1 欧式距离:
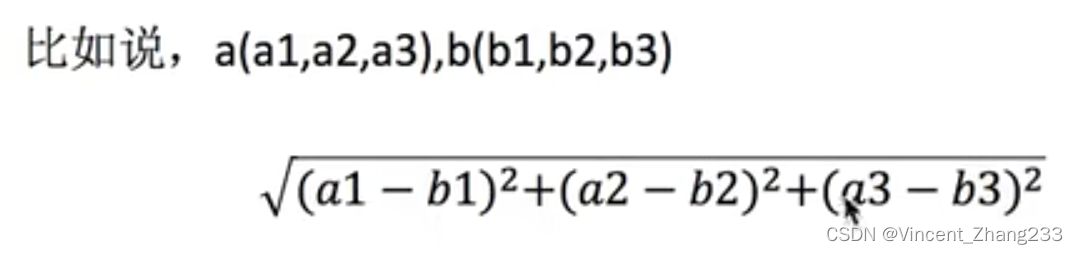
2-2 曼哈顿距离(绝对值距离)
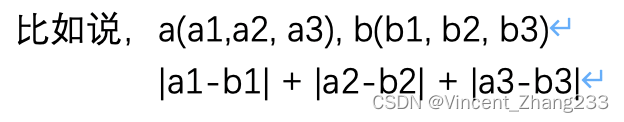
3、KNN应用举例:电影类型预测
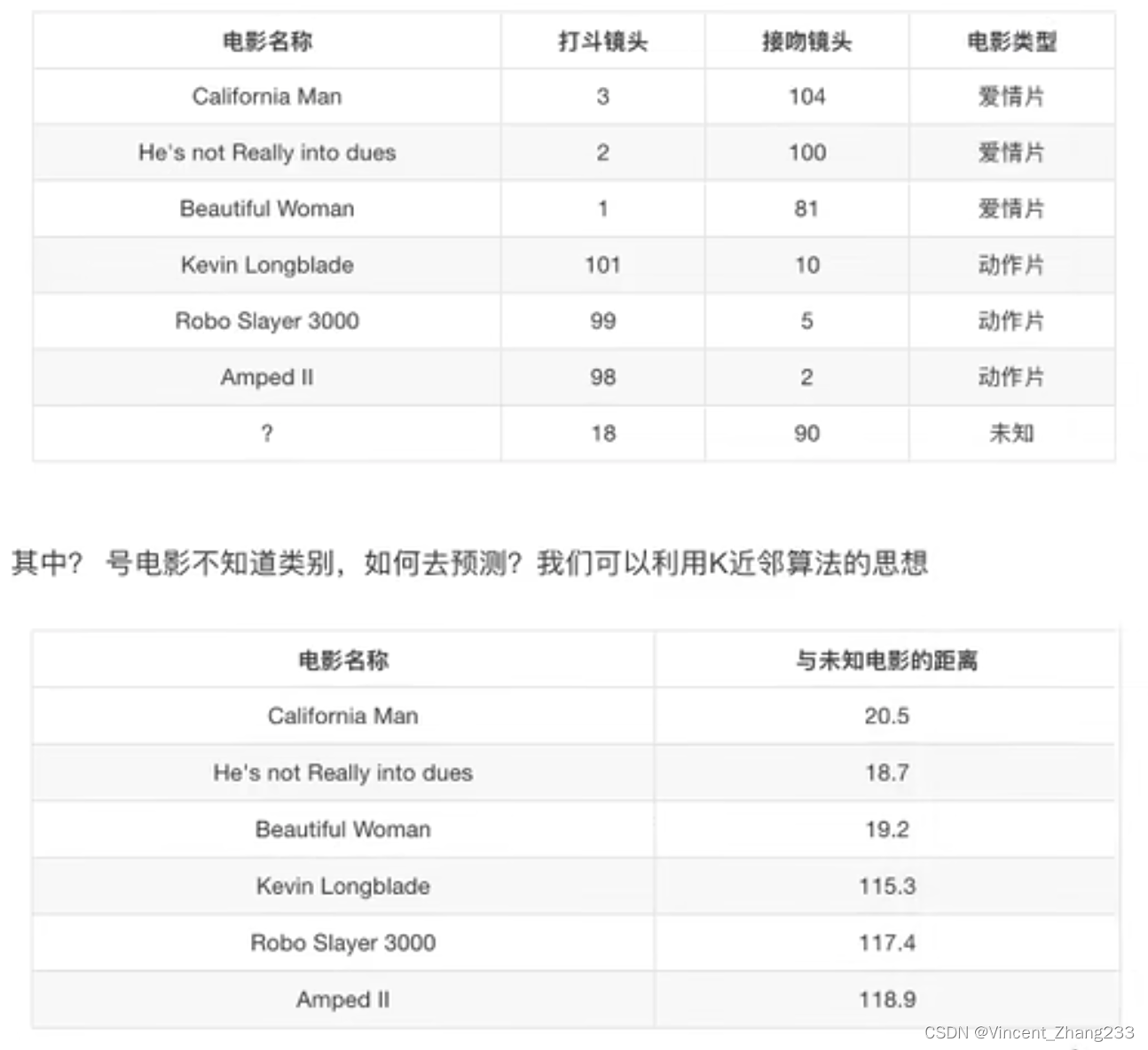
k=1 爱情片
k=2 爱情片
...
k=6 近邻中爱情片和动作片各占一半,无法确定电影类型
k=7 假设表中再加了一个动作片电影电影,则预测电影为动作片,可是该电影中却有90个接吻镜头,明显应该是爱情片。所以,如果k值取的过大,当样本不均衡的时候,就容易分错。即:k值过大,容易受到样本不均衡的影响。
总结:
k值如果取得过小,容易受到异常值的影响;
k值取得过大,容易受到样本不均衡的影响
4、KNN算法API

5、KNN算法优缺点:
优点:
简单,易于理解,易于训练,无需训练
缺点:
1)必须选择K值,如果K值选择不当,则分类精度不能保障
2) 是懒惰算法,对测试样本分类时的计算量大,内存开销大
这篇关于KNN(K近邻,K Nearest Neighbour)算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









