本文主要是介绍知识蒸馏的蒸馏损失方法代码总结(包括:基于logits的方法:KLDiv,dist,dkd等,基于中间层提示的方法:),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
有两种知识蒸馏方法:一种利用教师模型的输出概率(基于logits的方法)[15,14,11],另一种利用教师模型的中间表示(基于提示的方法)[12,13,18,17]。基于logits的方法利用教师的输出作为辅助信号来训练一个较小的模型,即学生模型:
利用教师模型的输出概率(基于logits的方法)
该类方法损失函数为:
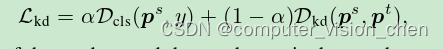
DIST
Tao Huang,Shan You,Fei Wang,Chen Qian,and Chang Xu.Knowledge distillation from a strongerteacher.In Advances in Neural Information Processing Systems,2022.
import torch.nn as nndef cosine_similarity(a, b, eps=1e-8):return (a * b).sum(1) / (a.norm(dim=1) * b.norm(dim=1) + eps)def pearson_correlation(a, b, eps=1e-8):return cosine_similarity(a - a.mean(1).unsqueeze(1),b - b.mean(1).unsqueeze(1), eps)def inter_class_relation(soft_student_outputs, soft_teacher_outputs):return 1 - pearson_correlation(soft_student_outputs, soft_teacher_outputs).mean()def intra_class_relation(soft_student_outputs, soft_teacher_outputs):return inter_class_relation(soft_student_outputs.transpose(0, 1), soft_teacher_outputs.transpose(0, 1))class DIST(nn.Module):def __init__(self, beta=1.0, gamma=1.0, temp=1.0):super(DIST, self).__init__()self.beta = betaself.gamma = gammaself.temp = tempdef forward(self, student_preds, teacher_preds, **kwargs):soft_student_outputs = (student_preds / self.temp).softmax(dim=1)soft_teacher_outputs = (teacher_preds / self.temp).softmax(dim=1)inter_loss = self.temp ** 2 * inter_class_relation(soft_student_outputs, soft_teacher_outputs)intra_loss = self.temp ** 2 * intra_class_relation(soft_student_outputs, soft_teacher_outputs)kd_loss = self.beta * inter_loss + self.gamma * intra_lossreturn kd_lossKLDiv (2015年的原始方法)
import torch.nn as nn
import torch.nn.functional as F# loss = alpha * hard_loss + (1-alpha) * kd_loss,此处是单单的kd_loss
class KLDiv(nn.Module):def __init__(self, temp=1.0):super(KLDiv, self).__init__()self.temp = tempdef forward(self, student_preds, teacher_preds, **kwargs):soft_student_outputs = F.log_softmax(student_preds / self.temp, dim=1)soft_teacher_outputs = F.softmax(teacher_preds / self.temp, dim=1)kd_loss = F.kl_div(soft_student_outputs, soft_teacher_outputs, reduction="none").sum(1).mean()kd_loss *= self.temp ** 2return kd_lossdkd (Decoupled KD(CVPR 2022) )
Borui Zhao,Quan Cui,Renjie Song,Yiyu Qiu,and Jiajun Liang.Decoupled knowledge distillation.InIEEE/CVF Conference on Computer Vision and Pattern Recognition,2022.
import torch
import torch.nn as nn
import torch.nn.functional as Fdef dkd_loss(logits_student, logits_teacher, target, alpha, beta, temperature):gt_mask = _get_gt_mask(logits_student, target)other_mask = _get_other_mask(logits_student, target)pred_student = F.softmax(logits_student / temperature, dim=1)pred_teacher = F.softmax(logits_teacher / temperature, dim=1)pred_student = cat_mask(pred_student, gt_mask, other_mask)pred_teacher = cat_mask(pred_teacher, gt_mask, other_mask)log_pred_student = torch.log(pred_student)tckd_loss = (F.kl_div(log_pred_student, pred_teacher, reduction='batchmean')* (temperature ** 2))pred_teacher_part2 = F.softmax(logits_teacher / temperature - 1000.0 * gt_mask, dim=1)log_pred_student_part2 = F.log_softmax(logits_student / temperature - 1000.0 * gt_mask, dim=1)nckd_loss = (F.kl_div(log_pred_student_part2, pred_teacher_part2, reduction='batchmean')* (temperature ** 2))return alpha * tckd_loss + beta * nckd_lossdef _get_gt_mask(logits, target):target = target.reshape(-1)mask = torch.zeros_like(logits).scatter_(1, target.unsqueeze(1), 1).bool()return maskdef _get_other_mask(logits, target):target = target.reshape(-1)mask = torch.ones_like(logits).scatter_(1, target.unsqueeze(1), 0).bool()return maskdef cat_mask(t, mask1, mask2):t1 = (t * mask1).sum(dim=1, keepdims=True)t2 = (t * mask2).sum(1, keepdims=True)rt = torch.cat([t1, t2], dim=1)return rtclass DKD(nn.Module):def __init__(self, alpha=1., beta=2., temperature=1.):super(DKD, self).__init__()self.alpha = alphaself.beta = betaself.temperature = temperaturedef forward(self, z_s, z_t, **kwargs):target = kwargs['target']if len(target.shape) == 2: # mixup / smoothingtarget = target.max(1)[1]kd_loss = dkd_loss(z_s, z_t, target, self.alpha, self.beta, self.temperature)return kd_loss利用教师模型的中间表示(基于提示的方法)
该类方法损失函数为:
![[ L_{hint} = D_{hint}(T_s(F_s), T_t(F_t)) ]](https://img-blog.csdnimg.cn/direct/8e98c5f6c2af427893aa0caeea96e537.png)
ReviewKD (CVPR2021)
论文:
Pengguang Chen,Shu Liu,Hengshuang Zhao,and Jiaya Jia.Distilling knowledge via knowledge review.In IEEE/CVF Conference on Computer Vision and Pattern Recognition,2021.
代码:
https://github.com/dvlab-research/ReviewKD
Adriana Romero,Nicolas Ballas,Samira Ebrahimi Kahou,Antoine Chassang,Carlo Gatta,and YoshuaBengio.Fitnets:Hints for thin deep nets.arXiv preprint arXiv:1412.6550,2014.
Yonglong Tian,Dilip Krishnan,and Phillip Isola.Contrastive representation distillation.In IEEE/CVFInternational Conference on Learning Representations,2020.
Baoyun Peng,Xiao Jin,Jiaheng Liu,Dongsheng Li,Yichao Wu,Yu Liu,Shunfeng Zhou,and ZhaoningZhang.Correlation congruence for knowledge distillation.In International Conference on ComputerVision,2019.
关于知识蒸馏损失函数的文章
FitNet(ICLR 2015)、Attention(ICLR 2017)、Relational KD(CVPR 2019)、ICKD (ICCV 2021)、Decoupled KD(CVPR 2022) 、ReviewKD(CVPR 2021)等方法的介绍:
https://zhuanlan.zhihu.com/p/603748226?utm_id=0
待更新
这篇关于知识蒸馏的蒸馏损失方法代码总结(包括:基于logits的方法:KLDiv,dist,dkd等,基于中间层提示的方法:)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




