本文主要是介绍对抗神经网络 CGAN实战详解 完整数据代码可直接运行,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
代码视频讲解:
中文核心项目:对抗神经网络 CGAN实战详解 完整代码数据可直接运行_哔哩哔哩_bilibili
运行图:

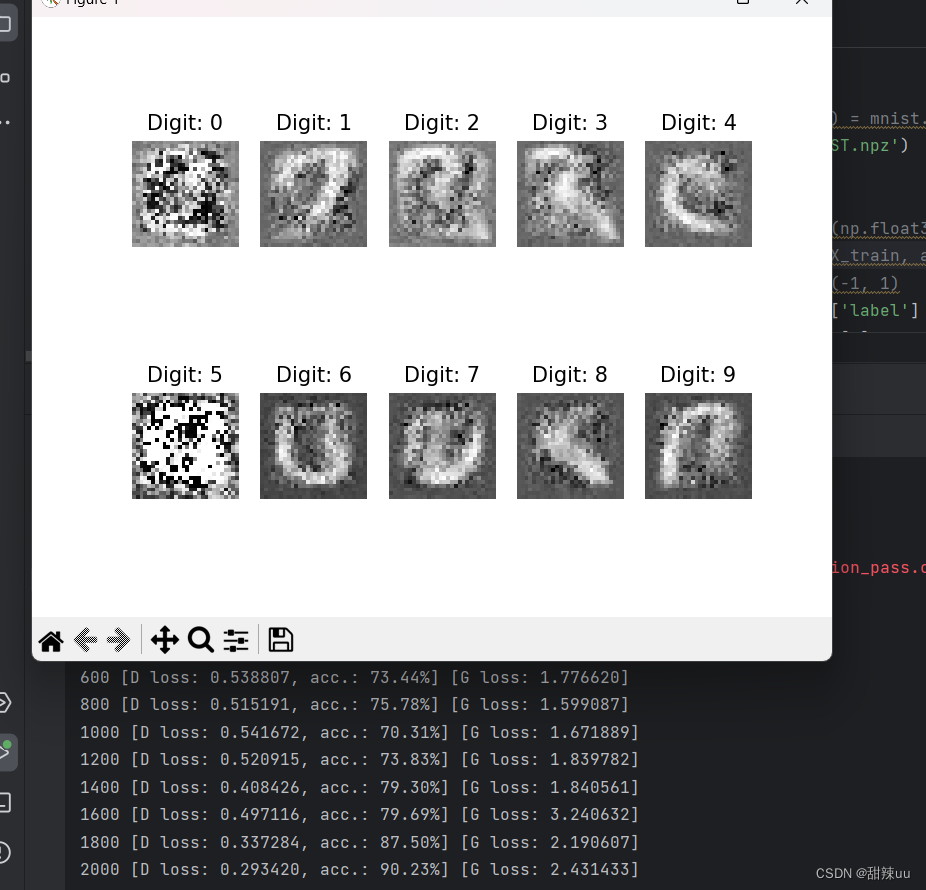
完整代码:
from keras.layers import Input, Dense, Reshape, Flatten, Dropout, multiply
from keras.layers import BatchNormalization, Activation, Embedding, ZeroPadding2D
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import UpSampling2D, Conv2D
# 我们可以在上面的库中使用其他GAN进行实验,WGAN效果会比CGAN好一些
from keras.models import Sequential, Model
from tensorflow.keras.optimizers import Adam
import matplo这篇关于对抗神经网络 CGAN实战详解 完整数据代码可直接运行的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






