本文主要是介绍U-Shape Transformer for Underwater Image Enhancement(用于水下图像增强的U型Transformer)总结,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景
现有的水下数据集或多或少存在图像数量少、水下场景少、甚至不是真实场景等缺点,限制了数据驱动的水下图像增强方法的性能。此外,水下图像在不同颜色通道和空间区域的衰减不一致也没有统一的框架。
贡献
1)提出了一种处理 UIE 任务的新型 U 型Transformer,其中基于Transformer设计的通道和空间注意机制能够有效消除色彩伪影和偏色。
2)设计了一种新颖的多色彩空间损失函数,结合了 RGB、LCH 和 LAB 色彩空间特征,进一步提高了输出图像的对比度和饱和度。
3)发布了一个大型数据集,其中包含 4279 幅真实水下图像以及相应的高质量参考图像、语义分割图和介质传输图,这有助于进一步开发 UIE 技术。
LSUI数据集
收集了 8018 幅水下图像,通过主观和客观两轮评估来选择参考图像,以尽可能消除潜在的偏差。
在第一轮中,受多个弱分类器可以组成一个强分类器的集合学习[46]的启发,我们首先使用现有的 18 种最优 UIE 方法相继处理收集到的水下图像,生成一个包含 18 ∗ 8018 幅图像的集合,用于下一步最佳参考数据集的选择。为了减少需要人工选择的图像数量,采用了非参考指标 UIQM 和 UCIQE 对所有生成的图像进行等权重评分。然后,每个原始图像的前三张参考图像组成一个大小为 3∗8018 的集合。考虑到个体差异,我们邀请了 20 名具有图像处理经验的志愿者,根据 UIE 任务中最重要的 5 个判断(对比度、饱和度、色彩校正效果、伪像程度、增强过度或不足程度)对图像进行评分,评分范围为 0-10 分,分数越高表示越满意。将每项得分归一化为 0-1 后,每张参考图片的总分为 100(5 ∗ 20)。在每张原始水下图像中,选择总和值最高的一张参考图像。此外,数据集中剔除了总和值低于 70 的图像。在第二轮中,我们邀请志愿者再次对每张参考图片进行投票,选出其存在的问题并确定相应的优化方法,然后使用适当的图像增强方法对其进行处理。接下来,邀请所有志愿者再进行一轮投票,删除半数以上志愿者不满意的图片对。为了提高 LSUI 数据集的实用性,我们还为每幅图像手工标注了分割图,并生成了介质透射图(介质透射图的生成方法)。最终,我们的 LSUI 数据集包含 4279 幅图像以及每幅图像对应的高质量参考图像、语义分割图和介质透射图。
U型Transformer
整体结构:包括一个基于 CMSFFT 和 SGFMT 的生成器和一个鉴别器
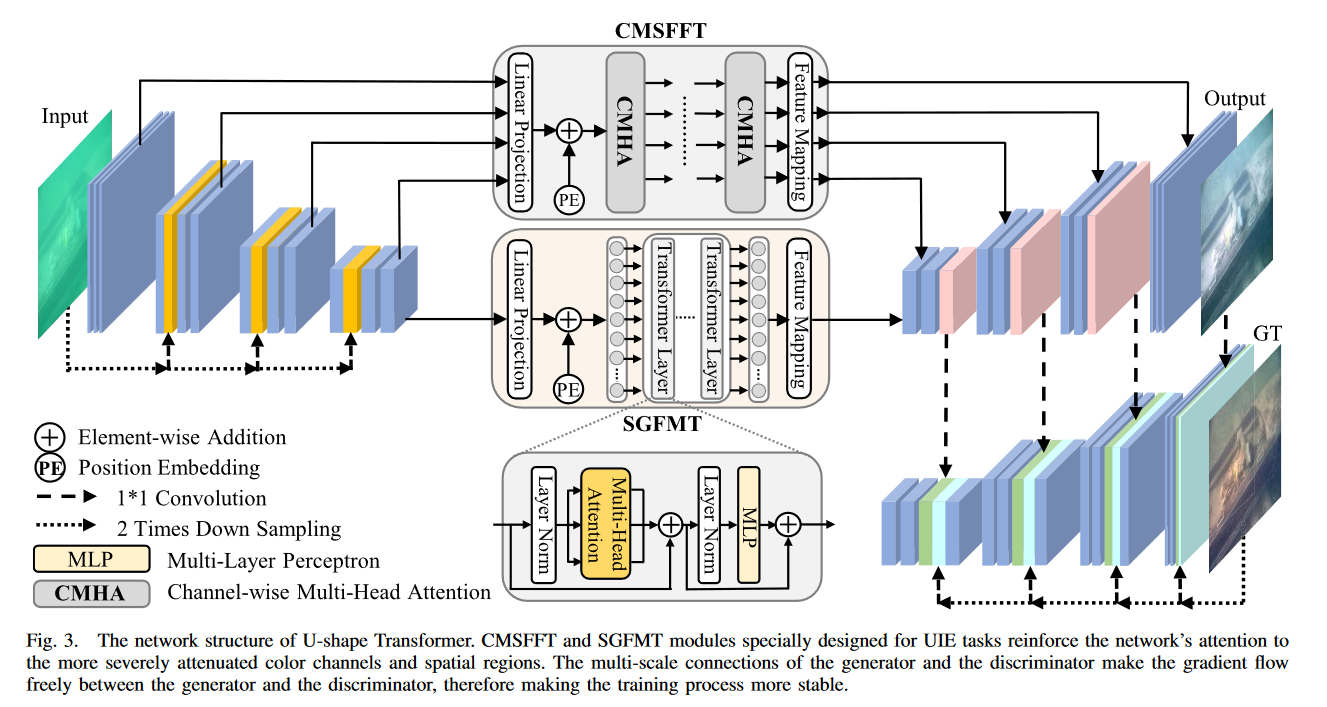
在生成器中,(1) 编码:除直接输入网络外,原始图像将被分别降采样三次。然后经过 1*1 卷积,将三个尺度特征图输入相应的尺度卷积块。四个卷积块的输出是 CMSFFT 和 SGFMT 的输入;(2)解码:经过特征重映射后,SGFMT 的输出被直接发送到第一个卷积块。同时,四个不同尺度的卷积块将接收 CMSFFT 的四个输出。
在鉴别器中,四个卷积块的输入包括:自身上层输出的特征图、解码部分输出的相应大小的特征图,以及使用参考图像降采样到相应大小后通过 1 ∗ 1 卷积生成的特征图。通过所述的多尺度连接,梯度流可以在生成器和判别器之间的多个尺度上自由流动,从而获得稳定的训练过程,丰富生成图像的细节。
SGFMT模块
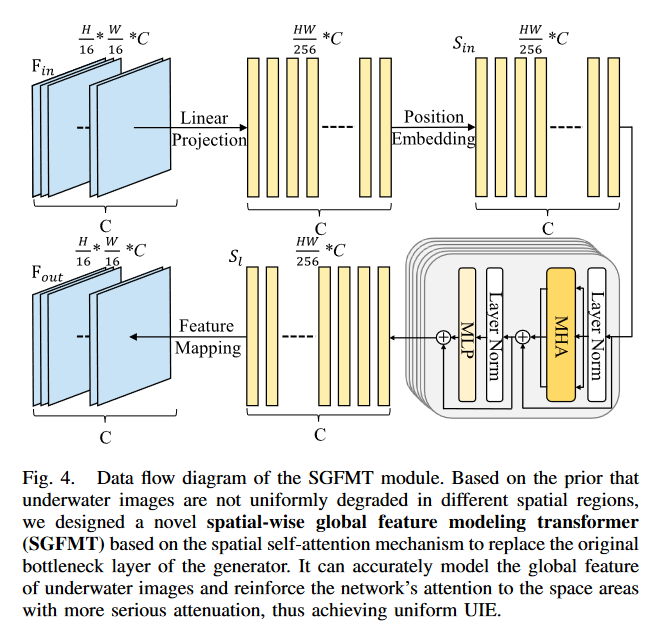
使用SGFMT替换生成器原有的瓶颈层,可以辅助网络对全局信息进行建模,加强网络对严重退化部分的关注。假设输入特征图的大小为。对于预期的变压器一维序列,采用线性投影将二维特征图拉伸为特征序列
。为了保留每个区域的有价值的位置信息,直接合并可学习的位置嵌入,可以表示为
![]()
其中W * Fin表示线性投影操作,PE表示位置嵌入操作。
然后,我们将特征序列 Sin 输入transformer模块,该模块包含 4 个标准transformer层。每个transformer层都包含一个多头注意力模块(MHA)和一个前馈网络(FFN)。前馈网络包括一个归一化层和一个全连接层。transformer块中第 层(
∈ [1, 2, ...,
])的输出可以通过以下方式计算:
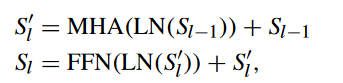
LN 表示归一化层,表示变换块中第
层的输出序列。最后一个变换块的输出特征序列为
∈
,经过特征重映射后还原为
的特征图。
CMSFFT模块
为加强网络对衰减较严重的彩色通道的关注,它由三部分组成。
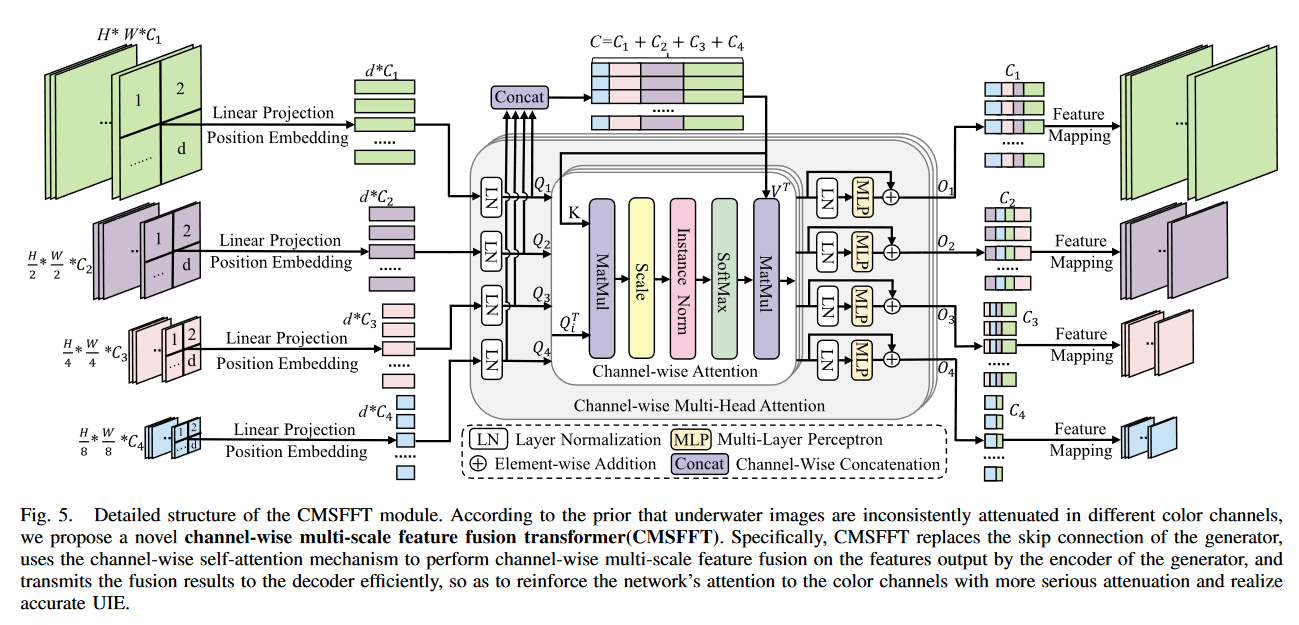
1)多尺度特征编码
输入是具有不同尺度的特征图,相关滤波器大小为
,步长为
的卷积核(i=0,1,2,3),对不同尺度的特征图进行线性投影。本文将P设为32。得到四个特征序列
,
,这四个卷积核将特征图划分为相同数量的块,而通道 Ci(i = 1、2、3、4)的数量保持不变。可以得到四个查询向量
,
,
可由
![]() 其中
其中 ,
和
表示可学习权重参数S由
通过信道维度串联生成,其中
,分别设置为64,128,256,512。
2)通道多头注意力(CMHA)
CMHA模块有六个输入,分别是,
,
,通道注意力
的输出可由下式获得
![]() 其中 IN 表示实例归一化操作。这种关注操作可引导网络关注图像质量下降更严重的通道。与批归一化(BN)不同,IN 应用于整批图像,而不是单个图像。
其中 IN 表示实例归一化操作。这种关注操作可引导网络关注图像质量下降更严重的通道。与批归一化(BN)不同,IN 应用于整批图像,而不是单个图像。
第 i 层 CMHA 的输出可以表示为:![]()
其中N表示头部的数量,本文设置为4。
3)前馈神经网络(FFN)
FFN 输出可表示为:![]() 其中
其中,MLP 表示多层感知器。公式中的运算需要依次重复
次(本作品中为
=4),以建立
层变换器。
最后,对四个不同的输出特征序列 进行特征重映射,将其重组为四个特征图
,它们是发生器解码部分卷积块的输入。
损失函数
设计了一个结合 RGB、LAB 和 LCH 色彩空间的多色彩空间损失函数来训练我们的网络。首先将 RGB 空间的图像转换为 LAB 和 LCH 空间,然后读取: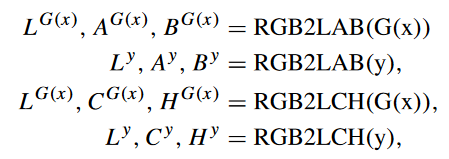
x、y 和 G(x) 分别代表原始输入、参考图像和生成器输出的清晰图像。
LAB 和 LCH 空间的损耗函数公式: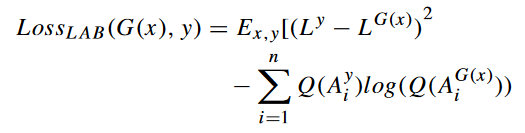

其中 Q 代表量化算子。在不同的色彩空间中对某一通道进行量化的目的是计算增强图像与参考图像在该通道上的交叉熵损失。
RGB 色彩空间的 L2 损失 和感知损失
,以及
和
是生成器的四个损失函数。
此外,还引入了标准的 GAN 损失函数,用于最小化生成图片与参考图片之间的损失,其写法为:![]()
其中 D 代表判别器。D 的目标是最大化 (G,D),以准确区分生成的图像和参考图像。而生成器 G 的目标是最小化生成图像和参考图像之间的损失。
最终的损失函数表示为: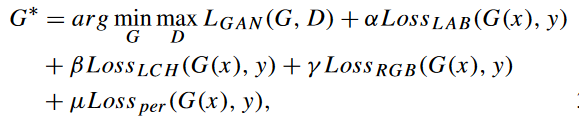
α、β、γ、μ 为超参数,分别设为 0.001、1、0.1、100。
实施细节
数据集
训练集:LSUI 数据集中被随机分的 Train-L(4500 张图像), UIEB数据集中 的 800 对水下图像Train-U 和 1,250 张合成水下图像; EUVP 数据集中包含的成对训练图像的Train-E 。
测试集:(1)全参考测试数据集:Test-L400(400 张图像)和Test-U90(UIEB中剩余的90对);(2)非参考测试数据集:Test-U60(UIEB 中的 60 幅非参考图像)和 SQUID(16 幅图像)。
评估指标
对于包含参考图像的测试数据集,我们使用 PSNR 和 SSIM 指标进行了全参考评估。
对于非参考测试数据集中的图像,采用了非参考评价指标 UCIQE 和 UIQM,其中 UCIQE 或 UIQM 分数越高,表明人类视觉感知越好。引入了一个 "感知分数(PS)"表示。PS 的范围为 1-5,分数越高,表示图像质量越高。此外,我们还采用了 NIQE,其数值越低,表示视觉质量越高。
色彩空间选择
使用由单一色彩空间损失函数和其他损失函数组成的混合损失函数来训练 U 型Transformer。我们使用 Train-L 训练网络,然后分别在 Test-L400 和 Test-U90 数据集上测试并计算 PSNR。结果如表 I 所示。
数据集评估
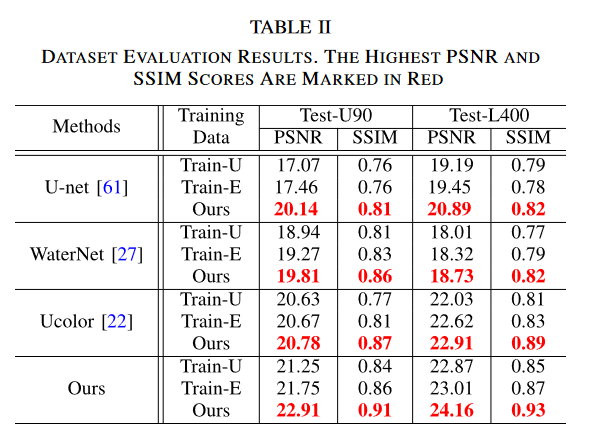
全参考评估

无参考评估

与其他图像修复网络相比
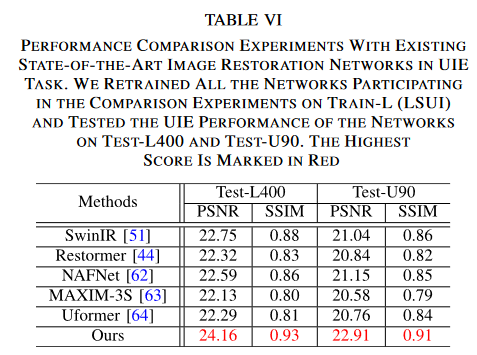
色彩修复性能评估
为了证明此 UIE 色彩校正方法的鲁棒性和准确性,我们在 Color-Checker7 数据集上比较了 10 种 UIE 方法的色彩校正能力。Color-Checker7 数据集包含用不同相机从浅水池拍摄的 7 幅水下图像。每张图像中还拍摄了色彩检查器。

消融实验
在 Test-L400 和 Test-U90 上进行了一系列消融研究。我们考虑了四个因素,包括 CMSFFT、SGFMT、多尺度梯度流机制(MSG)和多色空间损失函数(MCSL)。在消融研究中,我们还添加了一个基于 UNet 的网络,名为 UNet++ [67],其中包含更多参数。
总结
这项实验发布了一个大规模水下图像(LSUI)数据集,其中包含真实世界的水下图像,与现有的水下数据集相比,具有更丰富的水下场景(水域类型、光照条件和目标类别),并生成相应的清晰图像作为对比参考。同时也提供了每张原始水下图像的语义分割图和介质传输图。此外,提出了一种 U 型Transformer网络,以实现最先进的 UIE 性能。该网络的 CMSFFT 和 SGFMT 模块可以解决水下图像在不同颜色通道和空间区域的不一致衰减问题,而这在现有方法中是没有考虑到的。大量实验验证了该网络去除色彩伪影和偏色的卓越能力。结合多色彩空间损失函数,输出图像的对比度和饱和度得到了进一步提高。然而,由于所收集到的复杂场景的图像还有所欠缺,如深海低照度场景。因此,在今后的工作中引入其他通用增强技术,如弱光增强技术。
这篇关于U-Shape Transformer for Underwater Image Enhancement(用于水下图像增强的U型Transformer)总结的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





