本文主要是介绍论文解读:Axial-DeepLab: Stand-Alone Axial-Attention forPanoptic Segmentation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文是一个分割任务,但这里的方法不局限于分割,运用到检测、分类都可以。
论文下载
https://www.yuque.com/yuqueyonghupjh9oc/ovceh4/onilw42ux6e9n1ne?singleDoc# 《轴注意力机制》
一个问题
为什么transformer一开始都有CNN:降低H、W,降低self-attention计算规模O(特征点的个数^2,即(H*W)^2)
Stand-Alone Self-Attention 就是不通过CNN下采样,直接使用transformer,但是这样计算量会比较大,如何解决这个问题
摘要
Convolution exploits locality for efficiency at a cost of missing long range context.
卷积时感受野(卷积核)不能太大,要不效率太慢
Self-attention has been adopted to augment CNNs with non-local interactions.
自注意力机制一开始就有全局的视野
创新点1:
In this paper, we attempt to remove this constraint by factorizing 2D self-attention into two 1D self attentions.
这篇文章的核心思想就是:将图2D的self-attention转换成1D规模来增加效率
1Dself-attention:只在一维上的点进行自注意力机制,运算规模O(length^2)
2D的self-attention在二维上的点进行自注意力机制,运算规模O((H*W)^2)
创新点2:
In companion, we also propose a position-sensitive self-attention design.
由于transformer对位置编码不敏感,这里提出一个对位置编码设计
(之后咱们的论文都可以加上这一点,大概率不会比原来差)
介绍
However, it makes modeling long range relations challenging
卷积的感受野是由不断的卷积堆叠起来,对于浅层是具备很小的感受野
Recently, stacking attention layers as stand-alone models without any spatial convolution has been proposed and shown promising results
不使用卷积,不断堆叠transformer层级也能有不错的结果
However, naive attention is computationally expensive, especially on large inputs.
然而,单纯的attention非常吃数据(其实并且对数据也敏感,这是transformer最大的两个问题)
轴注意力机制
In this work, we propose to adopt axial-attention, which not only allows efficient computation, but recovers the large receptive field in stand-alone attention models.
推出一个轴注意力机制,不仅效率高,而且感受野比较大(作者认为感受野还是保存一致了)
In this work, we propose to adopt axial-attention, which not only allows efficient computation, but recovers the large receptive field in stand-alone attention models. The core idea is to factorize 2D attention into two 1D attentions along height- and width-axis sequentially.
在本篇文章中,推出一个轴向注意力机制,他不同于之前的一些降低运算规模(如:swin transformer 为了降低self-attention的计算量,他将h*w的矩形分成几个矩阵(如:4个h/2*w/2)来各自进行self attention,但这样就失去了transformer天生就拥有全局感受野的特点)
这里的意思应该是:一个点与他同行的所有的点做self-attention,之后再跟他同列的所有的点做self-attention,
这样也保持了比较大的全局感受野
举个栗子:对一张图256*256,之前论文是一个点的运算规模256*256,而现在是256(行方向上)+256(列方向上)

我自己的一些想法(关于为什么感受野保持不变,不保真):
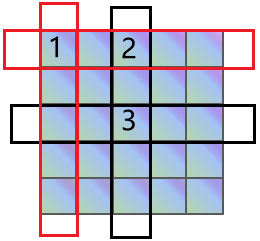
点3可以通过这种方式来接收到点1的特征:
1:点2通过行方向的轴注意力机制,获取到了点1的特征,因此点2里面包含了点1的特征:
2:点3通过列方向的轴注意力机制,获取到了点2的特征,而点2包含了点1的特征,因此点3可以获取到点1的特征
这类似于图的神经网络,通过不断的传递,一个点能够获得其他所有点的特征。
对于transformer的论文,一般都在这两个方向设计:
self-attention如何设计、位置编码如何设计
方法
原来transformer的不足
However, self-attention is extremely expensive to compute (O(h^2*w^2)) when the spatial dimension of the input is large, restricting its use to only high levels of a CNN (i.e., downsampled feature maps) or small images. Another drawback is that the global pooling does not exploit positional information, which is critical to capture spatial structures or shapes in vision tasks.
一方面,self-attention的计算规模是O(h^2*w^2);另外一方面,加入了池化之后位置信息也变得不敏感了
结构设计
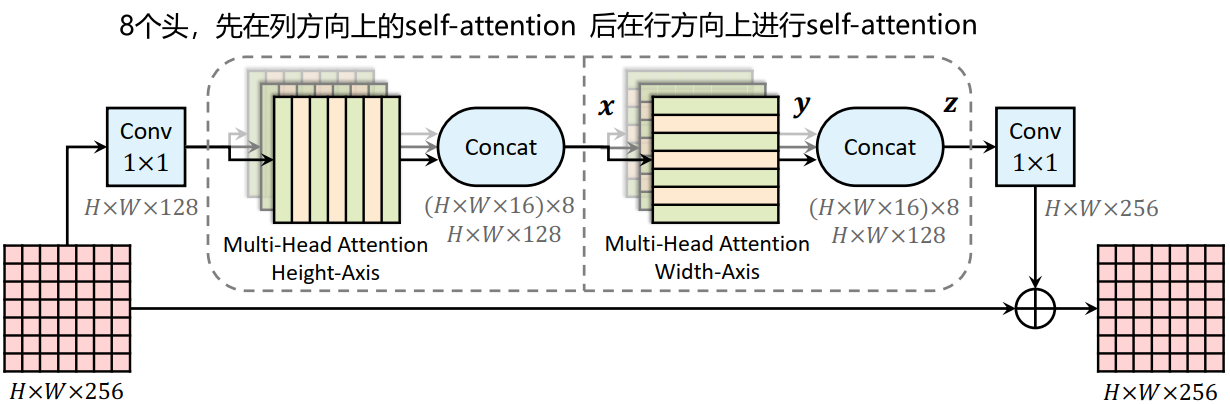
位置编码
想解决的问题
以前的位置编码并没有考虑到某个向量的重要性,比如说在NLP中,说一句:我今天想吃饺子;此时我想强调“吃”这个词,但是位置编码(包括正余弦编码)是无差别的对待该句话的每个词的;
下面引入可学习的位置编码,使得位置能够对每个Q/K差异化对待
原来的self-attention


现在的self-attention
仅Q加上位置编码
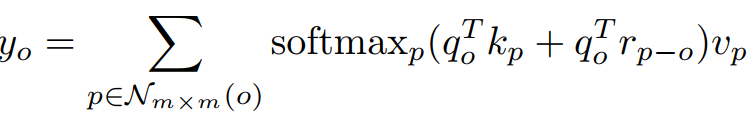
Q、K、V都加上位置编码
rq为作用在Q上可学习的位置编码,rk为作用在K上可学习的位置编码
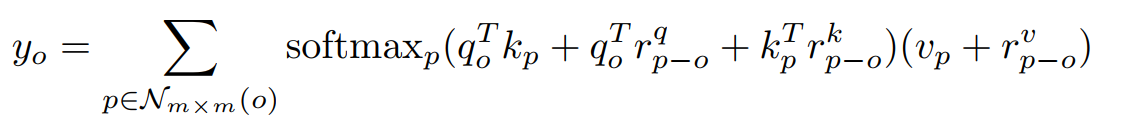
对应流程图
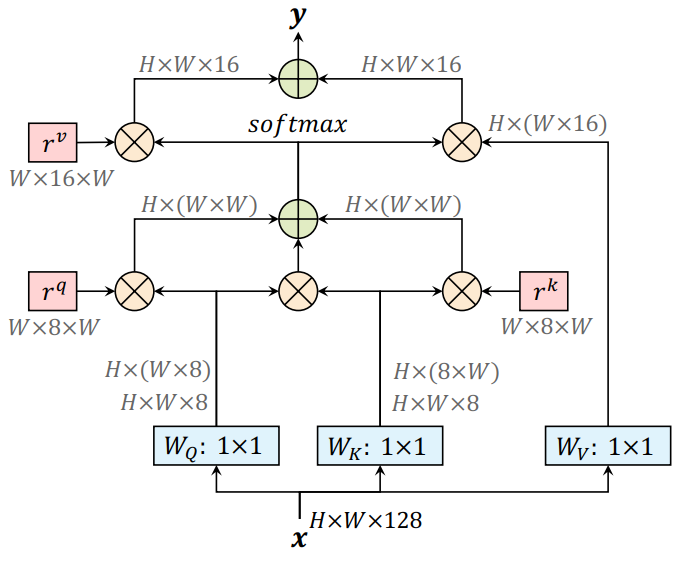

对该部分流程解释一下:这里应该是
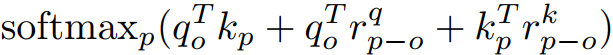
分别与rv和Wv
做矩阵乘法之后,得到
![]()
乘上
![]()
以及
![]()
乘上
![]()
,之后再把两者作加法
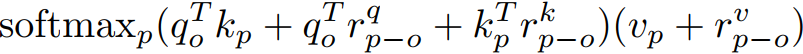
这篇关于论文解读:Axial-DeepLab: Stand-Alone Axial-Attention forPanoptic Segmentation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





