本文主要是介绍Python爬虫--爬取淘宝热卖demo,最后保存数据到excel,根据输入开始页码结束页码爬取,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
注1:只是用来简单练习,无频繁且恶意请求。
注2:此爬虫使用urllib库完成,因页面返回数据为json,需要找到对应的js。基础爬取,无需登录及验证码输入
1、百度搜索淘宝,点击进入
2、按F12 打开网络(network),查找到对应包含页面数据的js,可点击预览和响应查看返回的数据格式,检查返回的数据是否与页面一致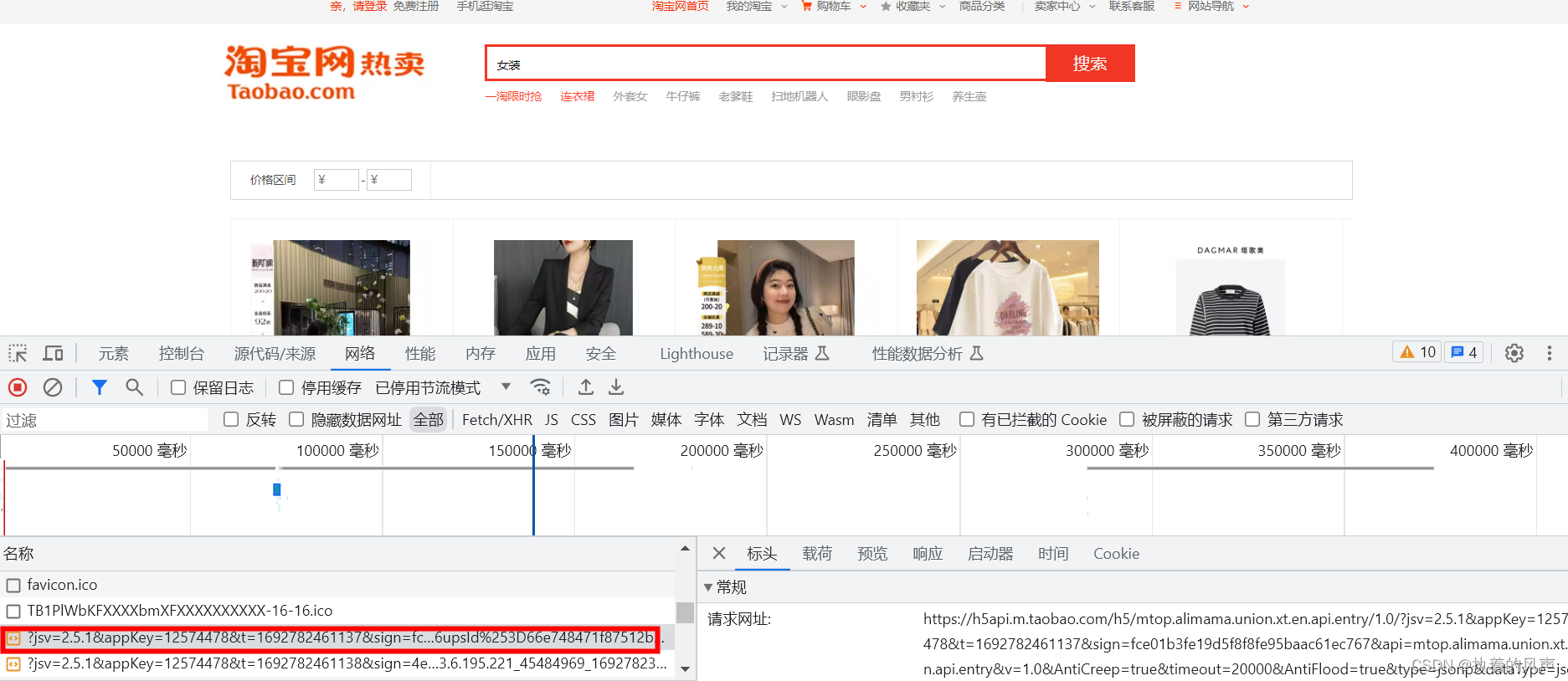
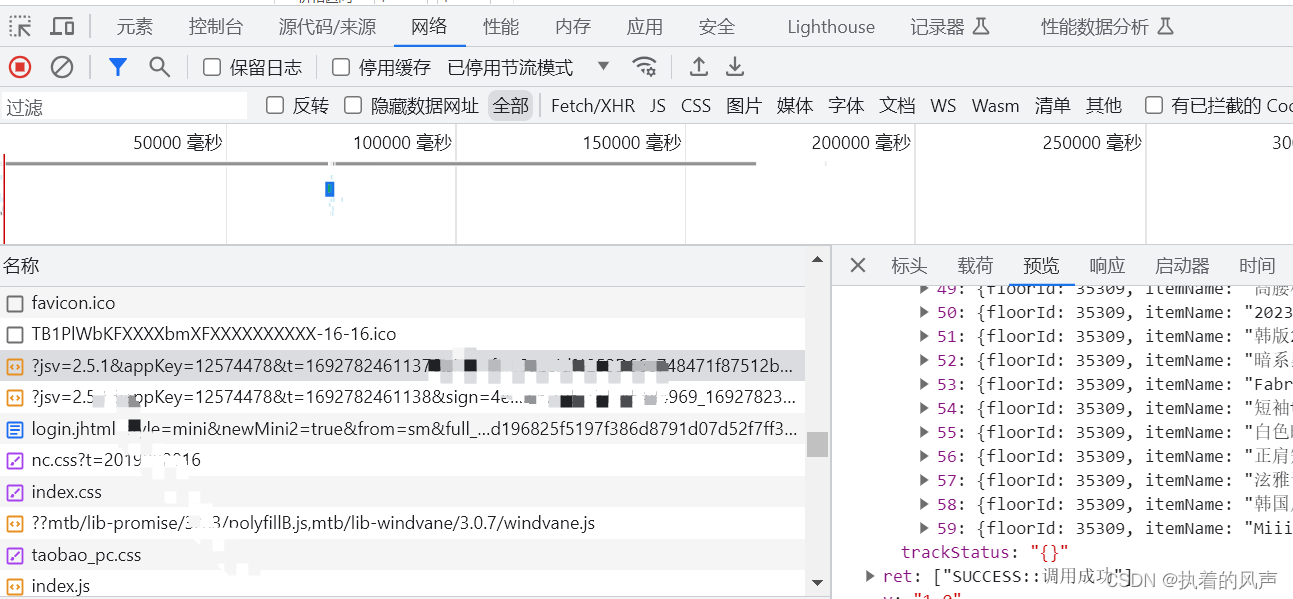
3、爬取数据需要提取url、User-Agent、Cookie。需要复制到代码中,时间太久Cookie会失效,出现令牌过期,只需要获取新的url和Cookie就行。
4、代码开发,运行后输入起始和结束页码,可爬取数据到excel。一共有
import urllib.request
import urllib.parse
import json
from openpyxl import Workbook
import requests# 每次执行需要更新url链接
url = 'https://h5api.m.taobao.com/h5/mtop.alimama.union.xt.en.api.entry/1.0/?jsv=2.5.1&appKey=12574478&t=1692782461137&sign=fce01b3fe19d5f8f8fe95baac61ec767&api=mtop.alimama.union.xt.en.api.entry&v=1.0&AntiCreep=true&timeout=20000&AntiFlood=true&type=jsonp&dataType=jsonp&callback=mtopjsonp2&data=%7B%22pNum%22%3A0%2C%22pSize%22%3A%2260%22%2C%22refpid%22%3A%22mm_26632258_3504122_32538762%22%2C%22variableMap%22%3A%22%7B%5C%22q%5C%22%3A%5C%22%E5%A5%B3%E8%A3%85%5C%22%2C%5C%22navigator%5C%22%3Afalse%2C%5C%22clk1%5C%22%3A%5C%2266e748471f87512b93bc1480b876e19d%5C%22%2C%5C%22recoveryId%5C%22%3A%5C%22201_33.6.195.221_45484969_1692782387677%5C%22%7D%22%2C%22qieId%22%3A%2236308%22%2C%22spm%22%3A%22a2e0b.20350158.31919782%22%2C%22app_pvid%22%3A%22201_33.6.195.221_45484969_1692782387677%22%2C%22ctm%22%3A%22spm-url%3A%3Bpage_url%3Ahttps%253A%252F%252Fuland.taobao.com%252Fsem%252Ftbsearch%253Frefpid%253Dmm_26632258_3504122_32538762%2526keyword%253D%2525E5%2525A5%2525B3%2525E8%2525A3%252585%2526clk1%253D66e748471f87512b93bc1480b876e19d%2526upsId%253D66e748471f87512b93bc1480b876e19d%22%7D'# 每次执行需要更新Cookie
headers = {'Accept': '*/*','Accept-Language': 'zh-CN,zh;q=0.9','Cookie': 'cna=9DDNHGpPM2ECAdy/+SB5Imuh; sgcookie=E100y1MQnOLh3GZjTTAhxLVpTIlGh6XjQ55Rd3uUULEgG8iWzIDBkLrFyYqya0BGFi8lGDdjymCkrVBZxDT%2FQsbFu6qLcbFjFtEeIzTNWNfL62P5WMM%2BGf8zWYtBBp3q0k1p; tracknick=%5Cu90ED%5Cu627F%5Cu4F1F121; _cc_=W5iHLLyFfA%3D%3D; miid=1276003676469059777; thw=cn; xlly_s=1; cookie2=1feddccc877898b591336ee4fbb9b751; t=79d4f86c3e94354f5ed0bdfaedf6836d; _tb_token_=e31ef63101153; _m_h5_tk=cb1ef594977752c83bbd6e05436a54a4_1692791111005; _m_h5_tk_enc=72d9fa8720b86c7617c9ccc98ecb11b6; _samesite_flag_=true; tfstk=d52wAOZNqOBZk1NtYbM44Gl3CVkthYQ7s-gjmoqmfV0ifrM4gz3BhGH1Mxzq8r3s1A063-u3qip1X1hmuPHiM5gj5qk4DzSCPT67XlHxIa_5FzKFGYyvV_D3MlEtHxxBo_N3Xm8Wp1s1EJAMe6cdrog3CPK3OhdJQVJDnRXx_4o2GKJqEccanlXwaEnhoXyY_EAqsDnEPMSUXEl5Z; l=fBQtyIAeN-LQ43djBOfZFurza77TtIRfguPzaNbMi9fPOk5p5lhhW1tSbEL9CnGVes9eR3-WjmOpBuTGVyIVV4wH6b293OEZ3dhyN3pR.; isg=BHl5FbT0OY0IV-VYzd5kdG3OiOVThm04z3SfZ5uuvKAfIpi049VnCKQ0pCbUmgVw','Referer': 'https://uland.taobao.com/','Sec-Ch-Ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Google Chrome";v="116"','Sec-Ch-Ua-Mobile': '?0','Sec-Ch-Ua-Platform': '"Windows"','Sec-Fetch-Dest': 'script','Sec-Fetch-Mode': 'no-cors','Sec-Fetch-Site': 'same-site','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'
}# 包装url, headers
request = urllib.request.Request(url=url, headers=headers)
# 发送请求
response = urllib.request.urlopen(request)
# 读取结果
content = response.read().decode('utf-8')# 去掉结果数据中前面的mtopjsonp2(
a = content.replace("mtopjsonp2(", "")
# 去掉结果数据结尾的)
b = a.replace(")", "")# 此处废弃,只是用来把数据保存在项目本地
# with open('taobao.json', 'w', encoding='utf-8') as fp:
# fp.write(b)
# print('本地文件保存成功')# 把json数据转为python对象
json_b = json.loads(b)if __name__ == '__main__':start_page = int(input("开始页码:"))end_page = int(input("结束页码:"))data_list = []for i in range(start_page, end_page+1):# 解析json,拿到需要的数据data = json_b['data']['recommend']['resultList'][i]# 把字典数据保存在列表中data_list.append(data)# 创建一个空excelwb = Workbook()# 选择当前工作表ws = wb.active# 写入表头ws.append(['ID', '商品名称', '商品ID', '店铺名称'])# 遍历列表for data in data_list:ws.append([data['floorId'], data['itemName'], data['itemId'], data['shopTitle']])wb.save('taobao.xlsx')print('结果保存成功')
5、运行展示

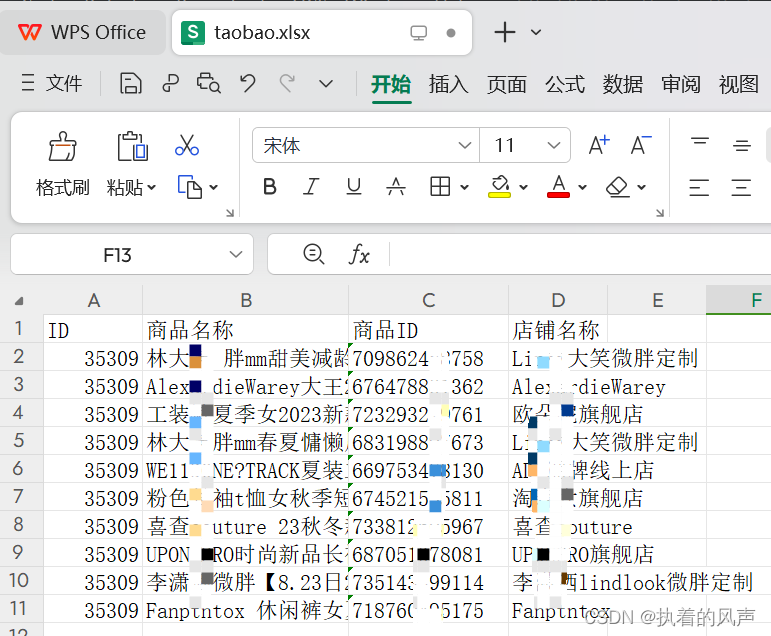
6、生成的excel自动保存在本地项目中
这篇关于Python爬虫--爬取淘宝热卖demo,最后保存数据到excel,根据输入开始页码结束页码爬取的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



