本文主要是介绍大数据集群源数据同步之MySql2HIVE增量同步,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 解决方案:
- canal
- 简介
- 工作原理
- canal 工作原理
- canal高可用集群搭建
- 环境准备
- 安装包下载
- 安装部署
- 部署admin
- 部署canal-server
- 说明
- 部署instance
- 测试
- Camus
- 简介
- 部署
- 任务调度
前言
纯干货,一步一步完成MySQL到hive全部详细过程
博主大数据集群:CDH6.3.2
解决方案:
利用阿里开源项目canal+Linkedin 的开源项目 Camus
canal
项目地址:https://github.com/alibaba/canal
说明:本文更新时canal发行版为1.1.6
简介
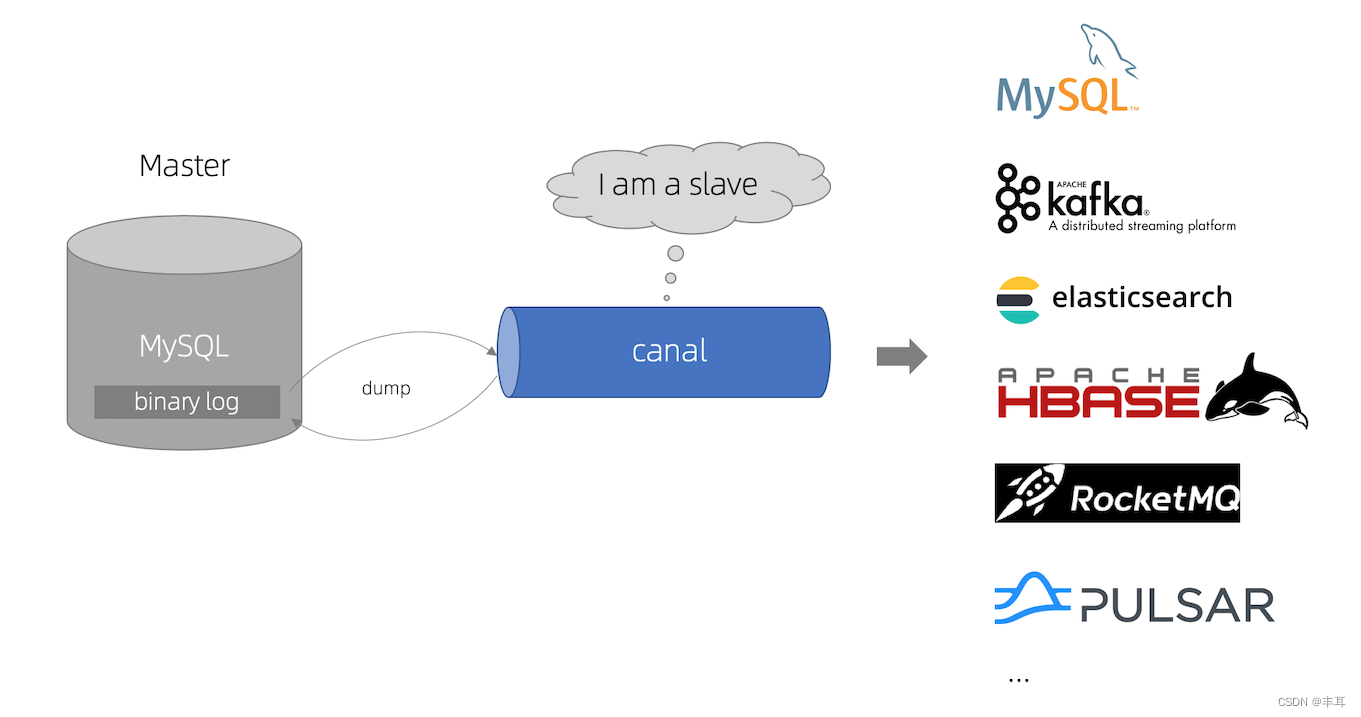
canal [kə’næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
基于日志增量订阅和消费的业务包括
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护(拆分异构索引、倒排索引等)
- 业务 cache 刷新
- 带业务逻辑的增量数据处理
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
工作原理
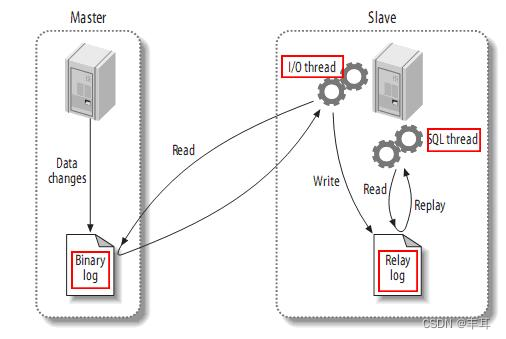
- MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
canal 工作原理
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
canal高可用集群搭建
环境准备
OS:CentOS7
jdk:jdk11【因为涉及授权问题,生产环境可以考虑openjdk】
MySQL:用于存储配置和节点等相关数据
zookeeper
kafka【可选,根据canal官方支持的mq自行配置,此处依据我们现状选择kafka】
关于以上环境依赖,请自行配置,本文默认已有相关环境,不做赘述。
安装包下载
版本地址:https://github.com/alibaba/canal/releases
版主使用的是v1.1.6
考虑到集群的搭建及运维高效性,因此选择admin+server的搭建方式
安装部署
部署admin
1.将下载好的canal.admin-1.1.6.tar.gz上传至服务器适当目录下【此处我是测试环境,因此直接使用root,生产环境建议使用专用账户】
[root@py3build ~]# mkdir -p /opt/canal/admin[root@py3build ~]# tar -zxvf canal.admin-1.1.6.tar.gz -C /opt/canal/admin[root@py3build ~]# cd /opt/canal/admin[root@py3build admin]# ll
total 8
drwxr-xr-x. 2 root root 93 Sep 21 13:53 bin
drwxr-xr-x. 3 root root 156 Sep 21 13:03 conf
drwxr-xr-x. 2 root root 4096 Sep 21 13:03 lib
drwxrwxrwx. 2 root root 23 Sep 21 13:03 logs
2.修改配置
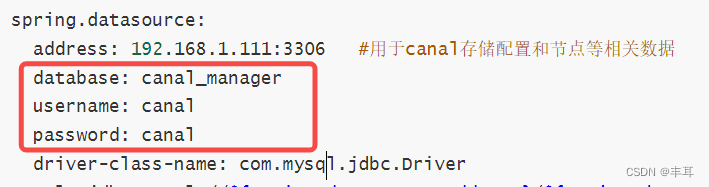
[root@py3build admin]# vim conf/application.ymlserver:port: 8089
spring:jackson:date-format: yyyy-MM-dd HH:mm:sstime-zone: GMT+8spring.datasource:address: 192.168.1.111:3306 #用于canal存储配置和节点等相关数据database: canal_managerusername: canalpassword: canaldriver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=falsehikari:maximum-pool-size: 30minimum-idle: 1canal:adminUser: adminadminPasswd: admin
配置中的adminUser/adminPasswd是用来和canal-server做链接校验的,后边配置canal-server时会做说明
3.初始化元数据库
[root@py3build admin]# mysql -h192.168.1.111 -uroot -pmysql>source conf/canal_manager.sql
初始化SQL脚本里会默认创建canal_manager的数据库,建议使用root等有超级权限的账号进行初始化
canal_manager.sql默认会在conf目录下,也可以通过链接下载 canal_manager.sql
如果本机没有mysql,需要安装一个mysql客户端
我的mysql是5.7的,所以安装client方式如下:
[root@py3build admin]# rpm -ivh https://repo.mysql.com//mysql57-community-release-el7-11.noarch.rpm [root@py3build admin]# yum search mysql [root@py3build admin]# yum install mysql-community-client.x86_64 -y [root@py3build admin]# [root@py3build admin]#如果报错:
mysql-community-libs-compat-5.7.39-1.el7.x86_64.rpm 的公钥尚未安装失败的软件包是:mysql-community-libs-compat-5.7.39-1.el7.x86_64 GPG 密钥配置为:file:///etc/pki/rpm-gpg/RPM-GPG-KEY-mysql执行一下
root@py3build admin]# rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022 [root@py3build admin]# yum install mysql-community-client.x86_64 -y
4.创建MySQL用户
初始化数据库并没有初见默认链接的用户,我们可以根据自己的需要创建一个用户,对canal_manager有读写权限,对应配置文件中的username和password
5.启动
[root@py3build admin]# sh bin/startup.sh
查看admin日志
[root@py3build admin]# tail logs/admin.log
......
2022-09-21 13:53:50.600 [main] INFO org.apache.coyote.http11.Http11NioProtocol - Starting ProtocolHandler ["http-nio-8089"]
2022-09-21 13:53:50.603 [main] INFO org.apache.tomcat.util.net.NioSelectorPool - Using a shared selector for servlet write/read
2022-09-21 13:53:50.613 [main] INFO o.s.boot.web.embedded.tomcat.TomcatWebServer - Tomcat started on port(s): 8089 (http) with context path ''
2022-09-21 13:53:50.616 [main] INFO com.alibaba.otter.canal.admin.CanalAdminApplication - Started CanalAdminApplication in 3.329 seconds (JVM running for 3.997)
2022-09-21 13:53:51.399 [http-nio-8089-exec-1] INFO o.a.catalina.core.ContainerBase.[Tomcat].[localhost].[/] - Initializing Spring FrameworkServlet 'dispatcherServlet'
2022-09-21 13:53:51.400 [http-nio-8089-exec-1] INFO org.springframework.web.servlet.DispatcherServlet - FrameworkServlet 'dispatcherServlet': initialization started
2022-09-21 13:53:51.408 [http-nio-8089-exec-1] INFO org.springframework.web.servlet.DispatcherServlet - FrameworkServlet 'dispatcherServlet': initialization completed in 8 ms
此时代表canal-admin已经启动成功,可以通过 http://192.168.1.11:8089 访问,默认密码:admin/123456
6.创建集群
- 1.登录后点击集群管理–>新建集群
- 2.填写集群信息,点击保存
- 3.点击操作–>主配置

- 4.点击载入模板,按照实际情况进行修改
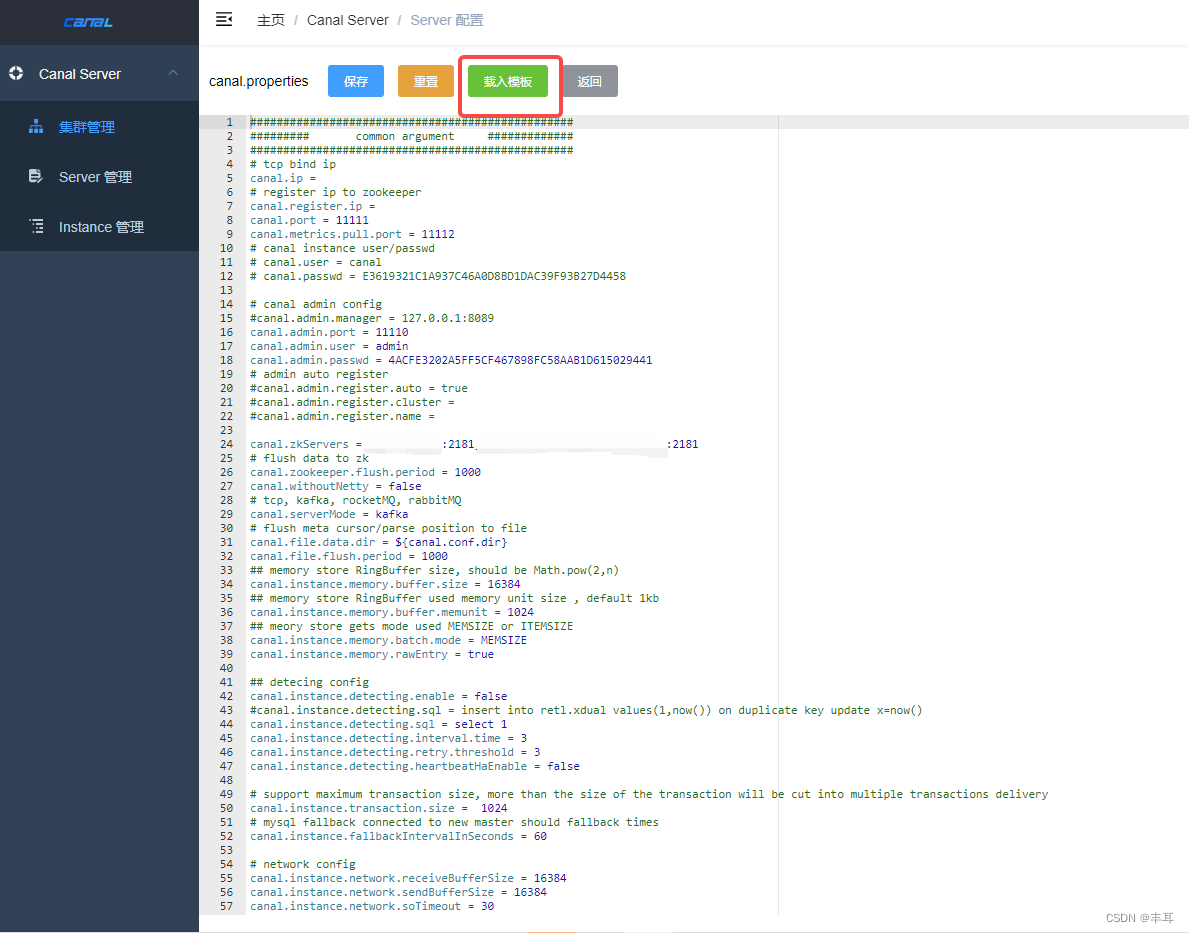
- 我是用的是kafka,所以修改点主要涉及以下几处
(1)canal.zkServers =
(2)kafka.bootstrap.servers =
(3)canal.instance.global.spring.xml = classpath:spring/default-instance.xml
同时因为没有启用kerberos,所以把kafka.kerberos.*进行了注释【可选,不注释掉会报WARN】
#kafka.kerberos.enable = false
#kafka.kerberos.krb5.file = “…/conf/kerberos/krb5.conf”
#kafka.kerberos.jaas.file = “…/conf/kerberos/jaas.conf”
其他参数大家根据自己的需要酌情修改,修改完后点击保存
部署canal-server
1.将下载好的canal.deployer-1.1.6.tar.gz上传至服务器适当目录下【此处我是测试环境,因此直接使用root,生产环境建议使用专用账户】
[root@py3build ~]# mkdir -p /opt/canal/deployer[root@py3build ~]# tar -zxvf canal.deployer-1.1.6.tar.gz -C /opt/canal/deployer[root@py3build ~]# cd /opt/canal/deployer[root@py3build deployer]# ll
total 4
drwxr-xr-x. 2 root root 93 Sep 21 13:56 bin
drwxr-xr-x. 6 root root 149 Sep 21 13:56 conf
drwxr-xr-x. 2 root root 4096 Sep 21 11:30 lib
drwxrwxrwx. 4 root root 45 Sep 21 13:56 logs
drwxrwxrwx. 2 root root 235 Aug 11 10:52 plugin
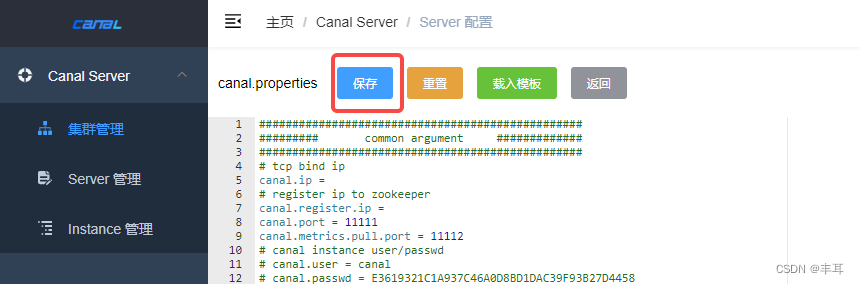
2.修改配置
[root@py3build deployer]# vim conf/canal_local.properties # register ip
canal.register.ip =# canal admin config
canal.admin.manager = 192.168.1.11:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
canal.admin.register.auto = true
canal.admin.register.cluster = test
canal.admin.register.name = mysql-02说明
- 1.面向user/passwd的安全ACL机制
针对canal.admin.passwd,这里默认做了密码加密处理,这里的passwd是一个密文,和canal-admin里application.yml里的密码原文做对应.
密文的生成方式,请登录mysql,执行如下密文生成sql即可(记得去掉第一个首字母的星号)
select password('admin')+-------------------------------------------+
| password('admin') |
+-------------------------------------------+
| *4ACFE3202A5FF5CF467898FC58AAB1D615029441 |
+-------------------------------------------+# 如果遇到mysql8.0,可以使用select upper(sha1(unhex(sha1('admin'))))
请注意几点:
(1)这个密码方式,同样对于canal.user.passwd有效 (1.1.4新增的,用于控制用户访问canal-server的订阅binlog的ACL机制)
(2)canal.admin.user/canal.admin.passwd,这是一个双向认证,canal-server会以这个密文和canal-admin做请求,同时canal-admin也会以密码原文生成加密串后和canal-server进行admin端口链接,所以这里一定要确保这两个密码内容的一致性
canal admin 的 conf/application.yml 里面定义了账号密码明文 canal.adminUser:canal.adminPasswd
canal server 的 conf/canal_local.properties 里面定义了账号密码密文 canal.admin.user:canal.admin.passwd
双向认证: canal server 向 canal admin 注册的时候会以密码密文做认证, canal admin 对 canal server 做连通性测试的时候也会将密码明文加密之后做认证 (连通性测试失败的时候,canal admin web 会显示对应的 canal server 处于 “断开” 状态)
-
2.canal.admin.register.auto:自动注册的意思,如果没有配置,canal-server 启动后需要自行在 canal-server 上面添加
-
3.canal.admin.register.cluster:这个配置如果不写代表当前的 canal-server 是一个单机节点,如果添加的名字在 canal-admin 上面没有提前注册,canal-server 启动时会报错
-
4.canal.admin.register.name:注册到 canal admin 上server的名字,唯一有意义即可
3.启动
目前conf下会包含canal.properties/canal_local.properties两个文件,考虑历史版本兼容性,默认配置会以canal.properties为主,如果要启动为对接canal-admin模式,可以有两种方式
- 1.指定为local配置文件
sh bin/startup.sh local
- 2.变更默认配置,比如删除canal.properties,重命名canal_local.properties为canal.properties
启动后,我们可以在admin的web界面上看到已经注册的server

使用集群模式注册的server,你会发现点击配置会提示【集群模式Server不允许单独变更配置,请在集群配置变更】
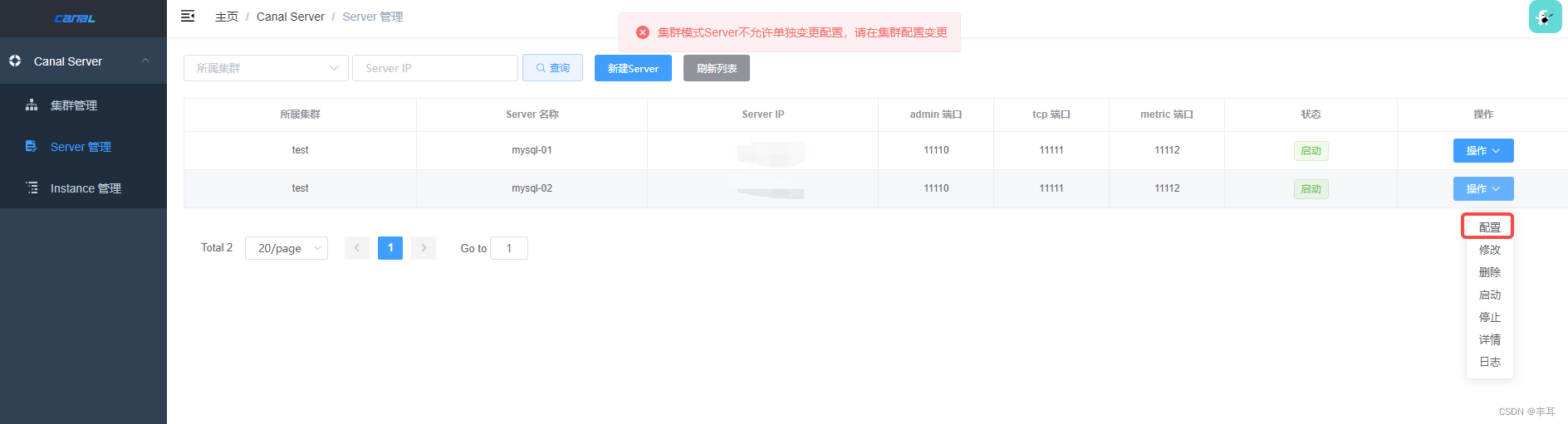
说明集群模式下的server不允许单独修改配置,所有配置统一走集群的主配置。
按照以上步骤可以部署多台server以保证集群的高可用。
部署instance
在上面canal-server和canal-admin都配置完之后,我们就可以创建对应的实例进行数据的操作
1.点击instance管理–>新建Instance–>载入模板
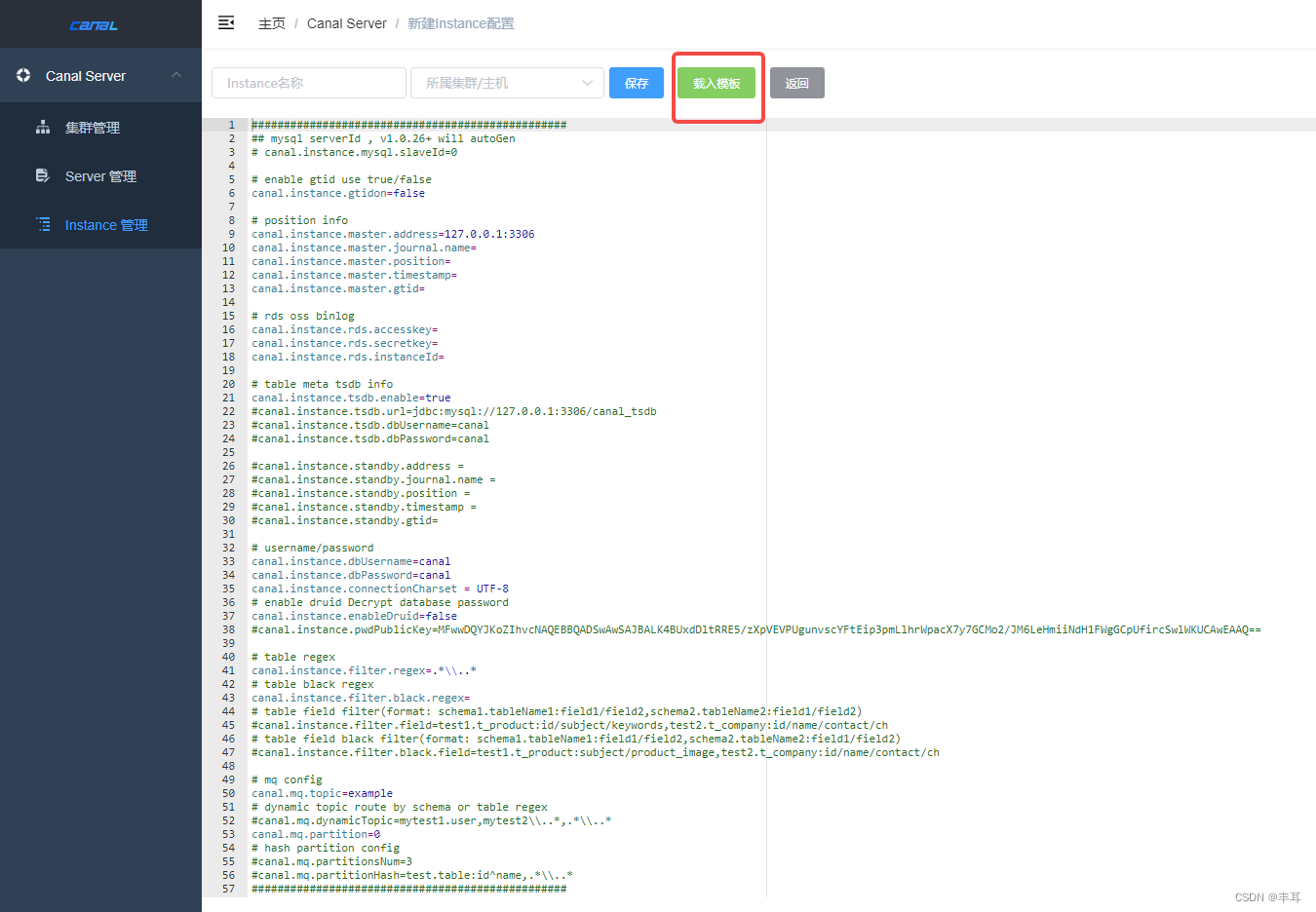
主要需要修改的配置点有【官方原文】:
(1)canal.instance.master.address:需要采集的mysql主库
(2)canal.instance.dbUsername:采集数据库的用户名,给予此用户slave相关权限
(3)canal.instance.dbPassword:采集数数据库密码
(4)canal.instance.filter.regex:要采集的库表,支持正则表达式
(5)canal.mq.topic:推送的kafka的topic名称
(6)canal.mq.dynamicTopic:针对库名或者表名发送动态topic,支持正则表达式
canal.mq.dynamicTopic 表达式说明
canal 1.1.3版本之后, 支持配置格式:schema 或 schema.table,多个配置之间使用逗号或分号分隔
例子1:test\\.test 指定匹配的单表,发送到以test_test为名字的topic上
例子2:.*\\..* 匹配所有表,则每个表都会发送到各自表名的topic上
例子3:test 指定匹配对应的库,一个库的所有表都会发送到库名的topic上
例子4:test\\..* 指定匹配的表达式,针对匹配的表会发送到各自表名的topic上
例子5:test,test1\\.test1,指定多个表达式,会将test库的表都发送到test的topic上,test1\\.test1的表发送到对应的test1_test1 topic上,其余的表发送到默认的canal.mq.topic值
为满足更大的灵活性,允许对匹配条件的规则指定发送的topic名字,配置格式:topicName:schema 或 topicName:schema.table
例子1: test:test\\.test 指定匹配的单表,发送到以test为名字的topic上
例子2: test:.*\\..* 匹配所有表,因为有指定topic,则每个表都会发送到test的topic下
例子3: test:test 指定匹配对应的库,一个库的所有表都会发送到test的topic下
例子4:testA:test\\..* 指定匹配的表达式,针对匹配的表会发送到testA的topic下
例子5:test0:test,test1:test1\\.test1,指定多个表达式,会将test库的表都发送到test0的topic下,test1\\.test1的表发送到对应的test1的topic下,其余的表发送到默认的canal.mq.topic值
大家可以结合自己的业务需求,设置匹配规则,建议MQ开启自动创建topic的能力
正常情况下我们一般选择使用canal.mq.dynamicTopic,而将canal.mq.topic注释掉
之后填写Instance名称,并选择相应集群,点击保存
2.启动
在操作中点击启动,状态变更为【启动】后。点击操作–>日志,刷新查看日志是否有报错
测试
- 修改监听的表数据,然后查看kafka
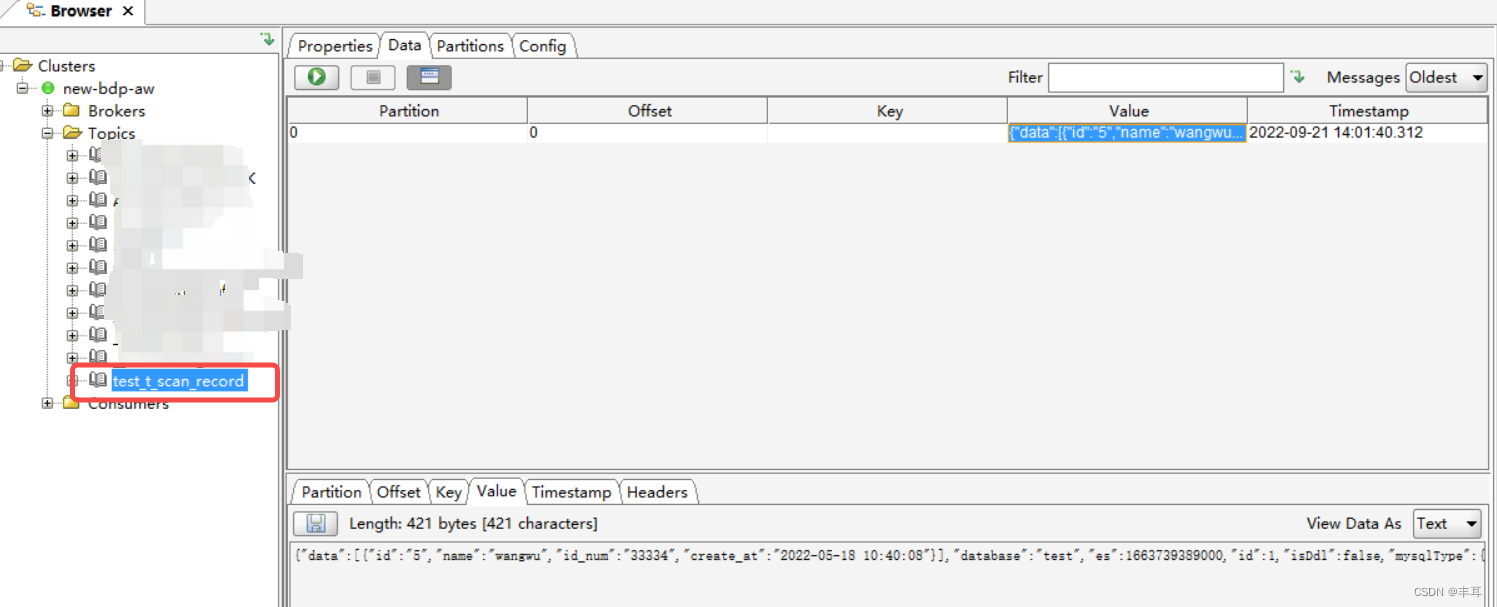
可以看到自动创建了【库_表明】的一个topic,并且里边有一条我们更改表数据产生的binlog数据 - 验证高可用
我们集群中有两台服务器,分别是mysql-01、mysql-02

我们可以看到当前instence挂载的所属主机是mysql-01

我们手动停止mysql-01

查看instance,也停了

然后再刷新一下,发现instance自动启动并挂载到mysql-02下了

Camus
项目地址:https://github.com/confluentinc/camus
项目说明:原版Camus是linkedIn开源的,但是后来合并到gobblin中了,gobblin功能相对强大一些,而我们因为只需要从kafka写hdfs这一个功能,所以就选择了Camus,这个版本是Confluent维护的镜像版本,虽然现在也不更新了,但是维护的时间比原版长。
简介
Camus的简介大家去看GitHub的官方介绍吧,毕竟全英文,没那么高的水平全翻译过来
部署
1.从GitHub上获取源代码,pom里的版本没把握的话(需要仔细研究源代码)就不用动了,我的CDH6.3.2集群使用正常
2.自定义binlog落地方式【可选】
因为canal写入kafka的binlog比较复杂,可能并不完全是我们希望的数据格式,因此可以进行一下二次开发,在HDFS落盘的时候直接写我们希望的格式,以下代码来自网络,因本人是运维工程师,不擅长java,因此有擅长java的兄弟可以自行开发或改编
将Camus源码clone到本地后,在com.linkedin.camus.etl.kafka.common下新建一个自定义的CanalBinlogRecordWriterProvider,代码如下
源代码如下:
package com.linkedin.camus.etl.kafka.common;import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.fastjson.parser.Feature;
import com.linkedin.camus.coders.CamusWrapper;
import com.linkedin.camus.etl.IEtlKey;
import com.linkedin.camus.etl.RecordWriterProvider;
import com.linkedin.camus.etl.kafka.mapred.EtlMultiOutputFormat;
import lombok.extern.slf4j.Slf4j;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.DefaultCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.io.compress.SnappyCodec;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.ReflectionUtils;import java.io.DataOutputStream;
import java.io.IOException;
import java.util.Map;@Slf4j
public class CanalBinlogRecordWriterProvider implements RecordWriterProvider {protected String recordDelimiter = null;public static final String ETL_OUTPUT_RECORD_DELIMITER = "etl.output.record.delimiter";public static final String DEFAULT_RECORD_DELIMITER = "\n";private boolean isCompressed = false;private CompressionCodec codec = null;private String extension = "";public CanalBinlogRecordWriterProvider(TaskAttemptContext context) {Configuration conf = context.getConfiguration();if (recordDelimiter == null) {recordDelimiter = conf.get(ETL_OUTPUT_RECORD_DELIMITER, DEFAULT_RECORD_DELIMITER);}isCompressed = FileOutputFormat.getCompressOutput(context);if (isCompressed) {Class<? extends CompressionCodec> codecClass = null;if ("snappy".equals(EtlMultiOutputFormat.getEtlOutputCodec(context))) {codecClass = SnappyCodec.class;} else if ("gzip".equals((EtlMultiOutputFormat.getEtlOutputCodec(context)))) {codecClass = GzipCodec.class;} else {codecClass = DefaultCodec.class;}codec = ReflectionUtils.newInstance(codecClass, conf);extension = codec.getDefaultExtension();}}static class CanalBinlogRecordWriter extends RecordWriter<IEtlKey, CamusWrapper> {private DataOutputStream outputStream;private String fieldDelimiter;private String rowDelimiter;public CanalBinlogRecordWriter(DataOutputStream outputStream, String fieldDelimiter, String rowDelimiter) {this.outputStream = outputStream;this.fieldDelimiter = fieldDelimiter;this.rowDelimiter = rowDelimiter;}@Overridepublic void write(IEtlKey key, CamusWrapper value) throws IOException, InterruptedException {log.info("IEtlKey key:"+key.toString()+" CamusWrapper value: " + value.toString());if (value == null) {return;}String recordStr = (String) value.getRecord();JSONObject record = JSON.parseObject(recordStr, Feature.OrderedField);if (record.getString("isDdl").equals("true")) {return;}log.info("record:" + record.toJSONString());JSONArray data = record.getJSONArray("data");if (data != null && data.size() > 0){for (int i = 0; i < data.size(); i++) {JSONObject obj = data.getJSONObject(i);if (obj != null) {StringBuilder fieldsBuilder = new StringBuilder();fieldsBuilder.append(record.getLong("id"));fieldsBuilder.append(fieldDelimiter);fieldsBuilder.append(record.getLong("es"));fieldsBuilder.append(fieldDelimiter);fieldsBuilder.append(record.getLong("ts"));fieldsBuilder.append(fieldDelimiter);fieldsBuilder.append(record.getString("type"));for (Map.Entry<String, Object> entry : obj.entrySet()) {fieldsBuilder.append(fieldDelimiter);fieldsBuilder.append(entry.getValue());}fieldsBuilder.append(rowDelimiter);outputStream.write(fieldsBuilder.toString().getBytes());log.info("fieldsBuilder.toString()" + fieldsBuilder.toString());}}}}@Overridepublic void close(TaskAttemptContext context) throws IOException, InterruptedException {outputStream.close();}}@Overridepublic String getFilenameExtension() {return "";}@Overridepublic RecordWriter<IEtlKey, CamusWrapper> getDataRecordWriter(TaskAttemptContext context,String fileName,CamusWrapper data,FileOutputCommitter committer) throws IOException, InterruptedException {Configuration conf = context.getConfiguration();String rowDelimiter = conf.get("etl.output.record.delimiter", "\n");Path path = new Path(committer.getWorkPath(), EtlMultiOutputFormat.getUniqueFile(context, fileName, getFilenameExtension()));FileSystem fs = path.getFileSystem(conf);FSDataOutputStream outputStream = fs.create(path, false);return new CanalBinlogRecordWriter(outputStream, "\t", rowDelimiter);}
}
说给不太懂java的兄弟:
- 如果你以前没用过com.alibaba,这些代码可能会报错,主要原因就是他引用了import com.alibaba.fastjson等,解决方法:
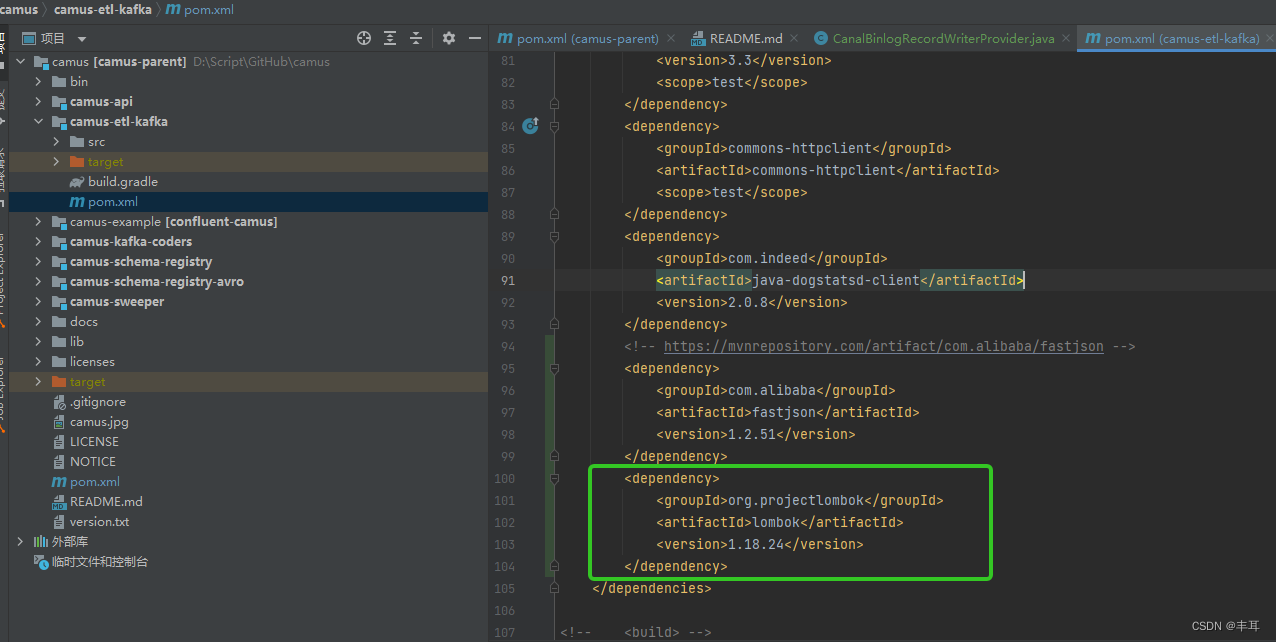
在camus-etl-kafka下的pom.xml文件中添加如下内容
<!-- https://mvnrepository.com/artifact/com.alibaba/fastjson -->
<dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.51</version>
</dependency>
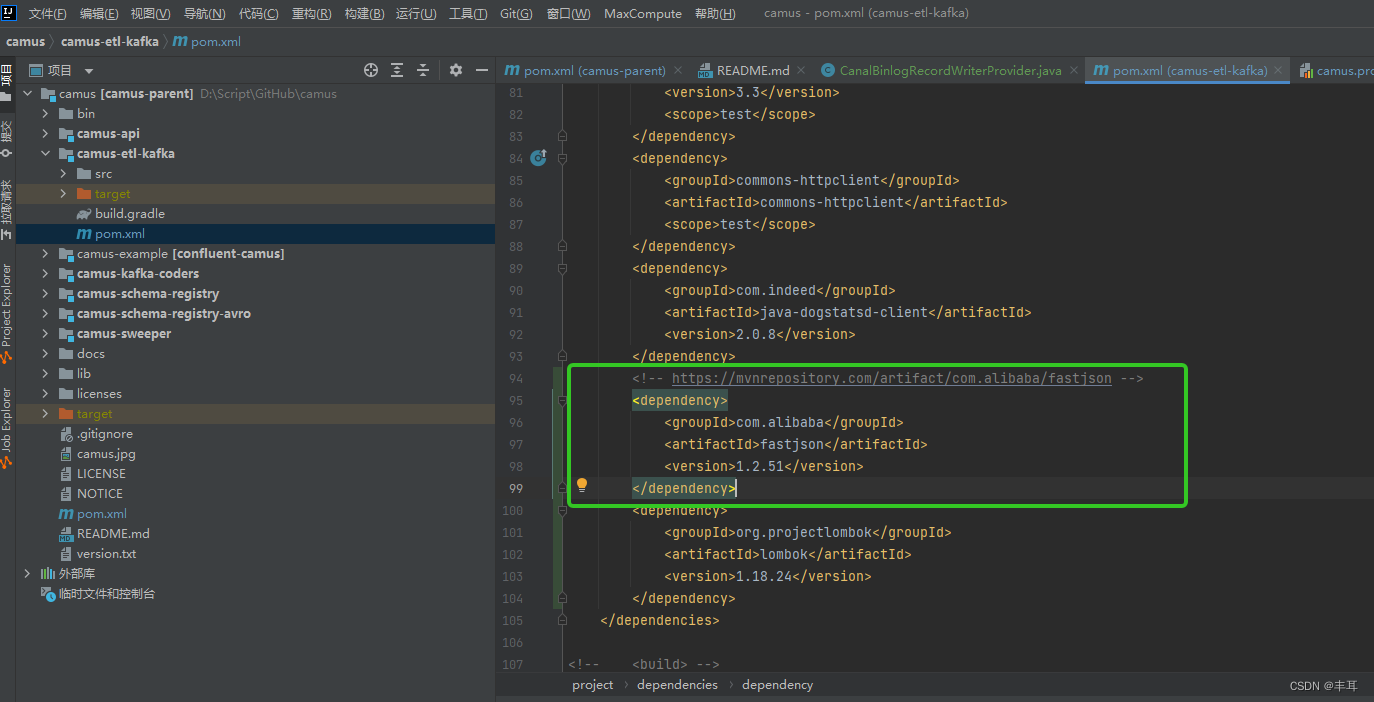
之后别忘了点击一下【加载maven变更】
- 如果还有报”lombok“相关的错误,就把下边这段也加上,当然版本可以自己控制,我用的这个配置生产环境运行正常
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.24</version></dependency>
3.执行编译命令
mvn clean package -DskipTests
记住,在没有hadoop环境中编译一定要加上-DskipTests,否则单元测试失败你编译不通过
正常情况下只要你的maven仓库拉取没问题,一般能编译成功
4.将整个camus文件夹全部打包压缩,上传服务器
记住,是整个项目打包,因为我不太懂java,所以就这么干了,要是有东java的兄弟也可以指教一下怎么操作。
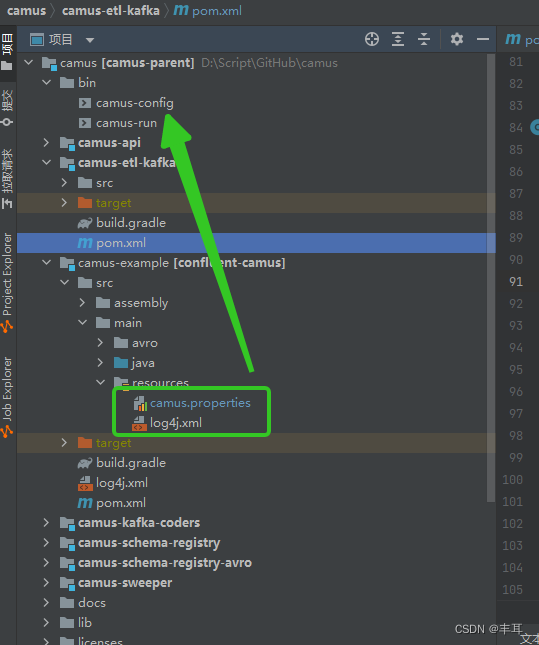
5.配置部署
上传至服务器后,解压缩,然后将camus/camus-example/src/main/resource/ 目录下的两个文件【log4j.xml】、【camus.properties】复制到camus/bin/ 目录下
6.修改配置
因为也是初次使用,所以这里放一个网上整理的
# Kafka brokers kafka的ip
kafka.brokers=xxx.xx.xx.xxx:9092,xxx.xx.xx.xxx:9092,xxx.xx.xx.xxx:9092
# job名称
camus.job.name=binlog-fetch
# Kafka数据落地到HDFS的位置。Camus会按照topic名自动创建子目录
etl.destination.path=/usr/local/camus/exec/topic
# HDFS上用来保存当前Camus job执行信息的位置,如offset、错误日志等
# base.path是基础路径,其它路径要在base.path之下
etl.execution.base.path=/usr/local/camus/exec
# HDFS上保存Camus job执行历史的位置
etl.execution.history.path=/usr/local/camus/exec/history
# 即core-site.xml中的fs.defaultFS参数
fs.default.name=hdfs://hadoop-master:9000
# Kafka消息解码器,默认有JsonStringMessageDecoder和KafkaAvroMessageDecoder
# Canal的Binlog是JSON格式的。当然我们也可以自定义解码器
camus.message.decoder.class=com.linkedin.camus.etl.kafka.coders.JsonStringMessageDecoder
# 落地到HDFS时的写入器,默认支持Avro、SequenceFile和字符串
# 这里我们采用一个自定义的WriterProvider,代码在后面
# etl.record.writer.provider.class=com.linkedin.camus.etl.kafka.coders.JsonStringMessageDecoder
etl.record.writer.provider.class=com.linkedin.camus.etl.kafka.common.CanalBinlogRecordWriterProvider
# JSON消息中的时间戳字段,用来做分区的
# 注意这里采用Binlog的业务时间,而不是日志时间
camus.message.timestamp.field=es
# 时间戳字段的格式
camus.message.timestamp.format=unix_milliseconds
# 时间分区的类型和格式,默认支持小时、天,也可以自定义时间
etl.partitioner.class=com.linkedin.camus.etl.kafka.partitioner.TimeBasedPartitioner
etl.destination.path.topic.sub.dirformat='pt_hour'=YYYYMMddHH
# 拉取过程中MR job的mapper数
mapred.map.tasks=20
# 按照时间戳字段,一次性拉取多少个小时的数据过后就停止,-1为不限制
kafka.max.pull.hrs=-1
# 时间戳早于多少天的数据会被抛弃而不入库
kafka.max.historical.days=3
# 每个mapper的最长执行分钟数,-1为不限制
kafka.max.pull.minutes.per.task=-1
# Kafka topic白名单和黑名单,白名单必填
kafka.blacklist.topics=oms_orders_orders,oms_orders_order_detail
kafka.whitelist.topics=
kafka.client.name=camus
# 设定输出数据的压缩方式,支持deflate、gzip和snappy
mapred.output.compress=false
# etl.output.codec=gzip
# etl.deflate.level=6
# 设定时区,以及一个时间分区的单位
etl.default.timezone=Asia/Shanghai
etl.output.file.time.partition.mins=607.运行
在camus/bin目录下执行:
./camus-run -P camus.properties
示例:
kafka中的数据:
落到hdfs上的数据

只需要将数据load到相应的hive表中,就可以直接处理了
任务调度
调度任务各个公司根据自己的需要进行调整就行,crontab、oozie、airflow等等,在此不做赘述
这篇关于大数据集群源数据同步之MySql2HIVE增量同步的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





