本文主要是介绍使用极限网关助力 ES 集群无缝升级、迁移上/下云,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在工作中大家可能会遇到以下这些场景:
- 自建 ES 集群需要平滑迁移到 XX 云;
- 从 XX 云将 ES 集群迁移到自建机房;
- ES 集群进行跨版本升级,同时保留回退能力;
这些场景往往都还有个共同的需求:迁移过程要保证业务的最小停机时间。
幸运的是,在这三个场景中,我们都能使用极限网关来帮助我们进行更丝滑的迁移或升级。下面,我们以迁移 ES 集群上云为例,介绍下整个工作过程。
- 自建版本: 5.4.2
- 云上版本: 5.6.16
- Gateway 和 Console 建议用最新版本
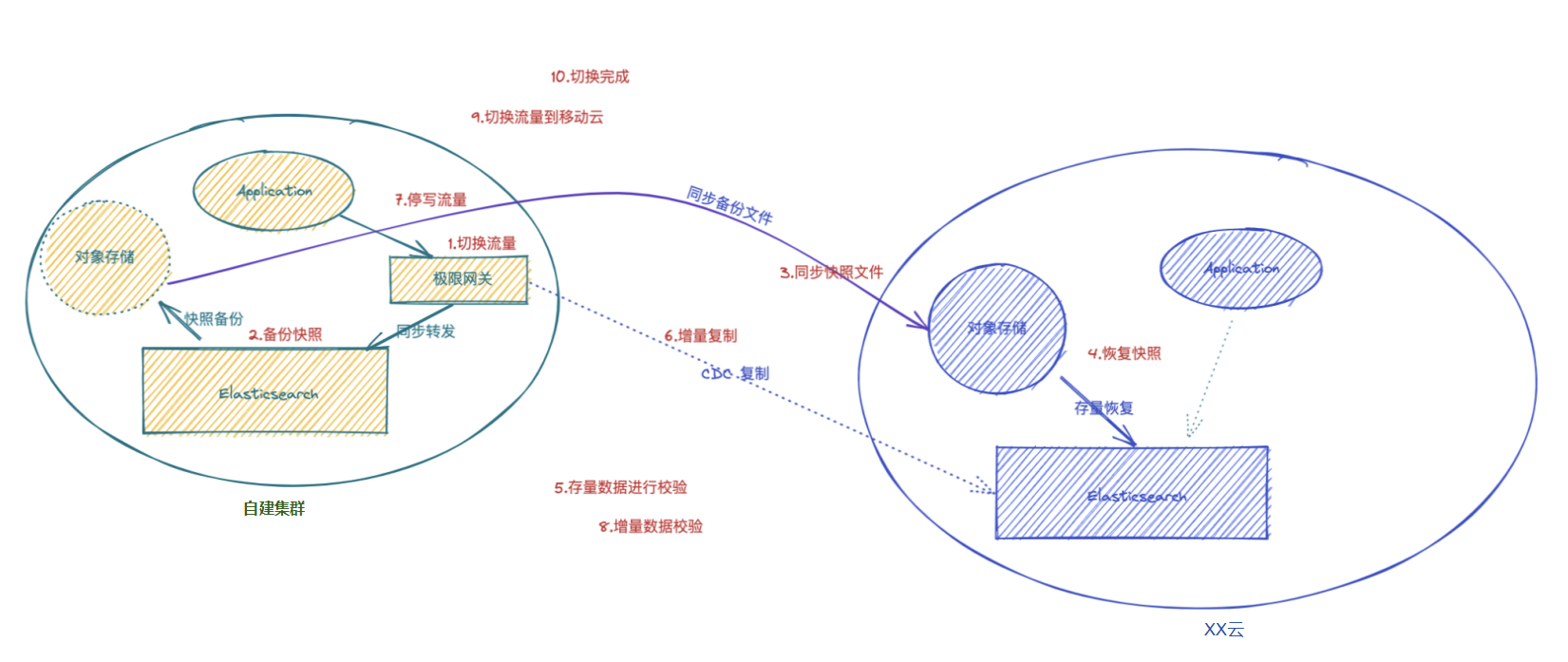
迁移架构
通过将应用端流量走网关的方式,请求同步转发给自建 ES,网关记录所有的写入请求,并确保顺序在 XX 云 ES 上重放请求,两侧集群的各种故障都妥善进行了处理,从而实现透明的集群双写,实现安全无缝的数据迁移。

业务端如果已经部署在云上,可以使用云上的 SLB 服务来访问网关,确保后端网关的高可用,如果业务端和极限网关还在企业内网,可以使用极限网关自带的 4 层浮动 IP 来确保网关的 高可用 。
执行步骤
部署 INFINI Gateway
为了保证数据的无缝透明迁移,通过网关来进行双写。
-
系统调优
-
安装 INFINI Gateway
-
修改网关配置
在此 下载 网关双写配置,默认网关会加载配置文件 gateway.yml 。如果要指定其他配置文件使用 -config 选项。
配置文件内容较多,下面仅展示必要部分。
#primaryPRIMARY_ENDPOINT: http://192.168.56.3:7171PRIMARY_USERNAME: elasticPRIMARY_PASSWORD: passwordPRIMARY_MAX_QPS_PER_NODE: 10000PRIMARY_MAX_BYTES_PER_NODE: 104857600 #100MB/sPRIMARY_MAX_CONNECTION_PER_NODE: 200PRIMARY_DISCOVERY_ENABLED: falsePRIMARY_DISCOVERY_REFRESH_ENABLED: false#backupBACKUP_ENDPOINT: http://192.168.56.3:9200BACKUP_USERNAME: adminBACKUP_PASSWORD: adminBACKUP_MAX_QPS_PER_NODE: 10000BACKUP_MAX_BYTES_PER_NODE: 104857600 #100MB/sBACKUP_MAX_CONNECTION_PER_NODE: 200BACKUP_DISCOVERY_ENABLED: falseBACKUP_DISCOVERY_REFRESH_ENABLED: false
PRIMARY_ENDPOINT:配置主集群地址和端口
PRIMARY_USERNAME、PRIMARY_PASSWORD: 访问主集群的用户信息
BACKUP_ENDPOINT:配置备集群地址和端口
BACKUP_USERNAME、BACKUP_PASSWORD: 访问备集群的用户信息
- 启动网关
启动网关并指定刚刚创建的配置,如下:
./gateway-linux-amd64 -config replication_via-disk.yml.yml
部署 INFINI Console
为了方便在多个集群之间快速切换,管理网关消费任务、查看队列等。使用 INFINI Console 来进行管理。
-
下载安装
-
启动服务
./console-linux-amd64 -service install
./console-linux-amd64 -service start -
注册资源
将 ES 集群、极限网关都注册到 Console 中。- 注册 ES 集群:方便切换集群,执行命令。除了新旧集群外,将网关也在此注册一次,方便验证网关功能。
- 注册 Gateway:管理网关任务、队列。
测试 INFINI Gateway
为了验证网关是否正常工作,我们通过 INFINI Console 来快速验证一下。
首先通过走网关的接口来创建一个索引,并写入一个文档,如下:

查看 5.4.2 集群的数据情况,如下:

查看集群 5.6.16 的数据情况,如下:

数据一致,说明网关配置都正常,验证结束。
调整网关的消费策略
因为我们需要在全量数据迁移之后,才能进行增量数据的追加,在全量数据迁移完成之前,我们应该暂停增量数据的消费。修改网关配置里面 Pipeline consume-queue_backup-bulk_request_ingestion-to-backup的参数 auto_start为 false,表示不自动启动该任务,具体配置方法如下:

修改完配置之后,需要重新启动网关。
由于之前已经注册了网关,待全量迁移完成之后,可以通过后台的 Task 管理来进行后续的任务启动、停止,如下:

切换流量
接下来,将业务正常写的流量切换到网关,也就是需要把之前指向 ES 5.4.2 的地址指向网关的地址,如果 5.4.2 集群开启了身份验证,业务端代码同样需要传递身份信息,和 5.4.2 之前的用法保持不变。

切换流量到网关之后,用户的请求还是以同步的方式正常访问自建集群,网关记录到的请求会按顺序记录到 MQ 里面,但是消费是暂停状态。
如果业务端代码使用的 ES 的 SDK 支持 Sniff,并且业务代码开启了 Sniff,那么应该关闭 Sniff,避免业务端通过 Sniff 直接链接到后端的 ES 节点,所有的流量现在应该都只通过网关来进行访问。
全量数据迁移
在流量迁移到网关之后,我们开始对自建 Elasticsearch 集群的数据进行全量迁移到 XX 云 Elasticsearch 集群。

全量迁移已有的数据的方式有很多种:
- 通过快照的方式进行恢复
- 使用 INFINI Console 进行数据迁移
增量数据迁移
在全量导入的过程中,可能存在数据的增量修改,不过这部分请求都已经完整记录下来了,我们只需要开启网关的消费任务即可将积压的请求应用到云端的 ES 集群。

示例操作如下:

通过观察队列是否消费完成来判断增量数据是否做完,如下:

执行数据比对
由于集群内部的数据可能比较多,我们需要进行一个完整的比对才能确保数据的完整性,可以通过 INFINI Console 的数据比对 工具来进行。
切换集群
如果验证完之后,两个集群的数据已经完全一致了,可以将程序切换到新集群,或者将网关的配置里面的主备进行互换,仍旧写两个集群,先写云端集群,再写自建集群。

双集群在线运行一段时间,待业务完全验证之后,再安全下线老集群,如遇到问题,也可以随时回切到老集群。
小结
通过使用极限网关,自建 ES 集群可以安全无缝的迁移上云,在迁移的过程中,两套集群通过网关进行了解耦,两套集群的版本也可以不一样,在迁移的过程中还能实现版本的无缝升级。
工作流程图
这篇关于使用极限网关助力 ES 集群无缝升级、迁移上/下云的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







