本文主要是介绍ES-ELSER 如何在内网中离线导入ES官方的稀疏向量模型(国内网络环境下操作方法),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ES官方训练了稀疏向量模型,用来支持语义检索。(目前该模型只支持英文)
最好是以离线的方式安装。在线的方式,在国内下载也麻烦,下载速度也慢。还不如用离线的方式。对于一般的生产环境,基本上也是网络隔离的。离线下载安装的方式最简单。
参考官方安装文档:ELSER – Elastic Learned Sparse EncodeR | Machine Learning in the Elastic Stack [8.11] | Elastic
下载模型
直接把链接放在浏览器上,就可以去下载。(我用官方提供的地址,根本没有找到模型文件)
这里注意,es官方提供了两个版本。
v1
https://ml-models.elastic.co/elser_model_1.metadata.json
https://ml-models.elastic.co/elser_model_1.pt
https://ml-models.elastic.co/elser_model_1.vocab.json
V2
https://ml-models.elastic.co/elser_model_2.metadata.json
https://ml-models.elastic.co/elser_model_2.pt
https://ml-models.elastic.co/elser_model_2.vocab.json
上传模型到es节点
然后在config目录下,新建一个model目录,把上边下载的模型,都都放进去
models里边

然后修改es的配置文件
以下内容不用做任何修改(直接复制粘贴到elasticsearch.yml 配置文件中即可。不用修改)
xpack.ml.model_repository: file://${path.home}/config/models/
重启es节点
先把每一个节点都重启。
应用部署模型
点击左上角,在table页中选择
machine learning > model managemant > trained models
然后在kibana的机器学习界面,找到模型管理,点击下载。
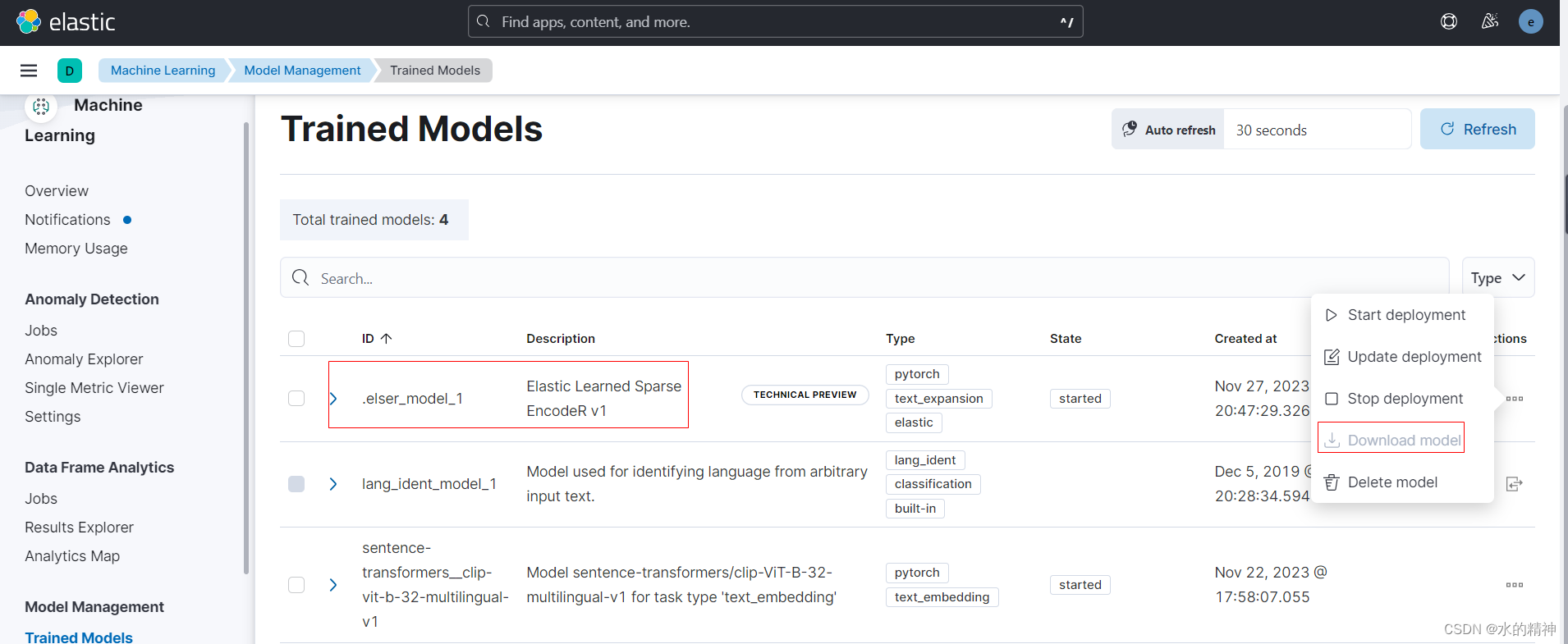
我这里已经点击过下载了,这里需要一点时间下载。等待下载完成,再部署模型。这里其实是把准备好的模型,导入到集群中
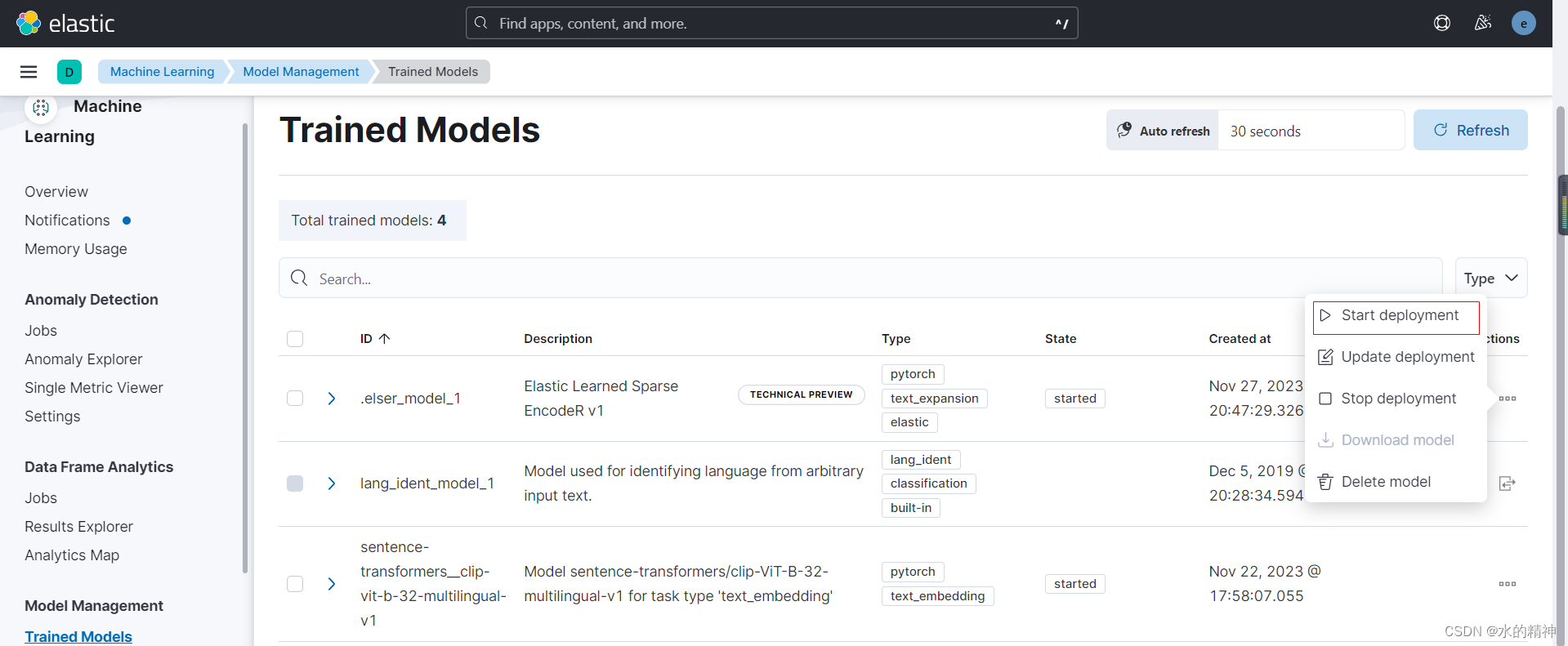
选择部署模型
这里,早到elser_model_1 然后选择start deployment
ELSER 使用文档
Tutorial: semantic search with ELSER | Elasticsearch Guide [8.11] | Elastic
这篇关于ES-ELSER 如何在内网中离线导入ES官方的稀疏向量模型(国内网络环境下操作方法)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









