本文主要是介绍6.1810: Operating System Engineering <Lab2 syscall: System calls>,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
课程链接:6.1810 / Fall 2023
一、本节任务

二、要点
操作系统要满足三要素:并发、隔离、交互(multiplexing, isolation, and interaction)。
宏内核(monolithic kernel):是操作系统核心架构的一种,此架构的特性是整个核心程序都是以核心空间(Kernel Space)的身份及监管者模式(Supervisor Mode)来运行。宏内核中各个部分通信十分容易,缺点就是一旦操作系统某个部分出问题,整个内核都可能直接崩溃。
为了减少内核中出现错误的风险,操作系统设计者减少在 Supervisor Mode 下运行的操作系统代码,并在用户模式运行大部分操作系统模块。这种内核组织被称为微内核(microkernel)。
IPC(inter-process communication):进程间通信

xv6使用硬件实现的页表(page table)来给每个进程提供自己的地址空间。riscv页表把虚拟地址(riscv指令操作的地址)转换成物理地址(cpu发送到主存储器的地址)。
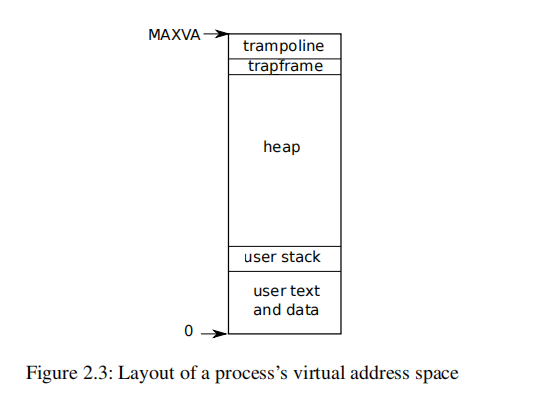
xv6为每个进程的地址空间维护一个单独的地址空间,包括从虚拟地址零开始的进程的用户内存。首先是指令,然后是全局变量,然后是堆栈,最后是一个“堆”区域(对于malloc),进程可以根据需要进行扩展。
在结构体 struct proc(kernel/proc.h)中保存了进程的各种状态。一个进程最重要的内核状态包括它的页表,它的内核栈,和它的运行状态。
每个进程有两个栈:用户栈和内核栈,当进程执行用户指令时,只会使用用户栈,此时内核栈是空的;当进程进入内核空间时(系统调用或中断),内核代码(如系统函数 sys_open())在进程的内核栈里面执行。当进程在内核态时,它的用户栈仍然包含之前保存的数据,内核栈是独立的,所以即使进程破坏了其用户堆栈,内核也可以执行。
在 riscv 中,进程可以通过 ecall 指令来进行系统调用,ecall 指令会提高硬件的特权级别,并且跳转到内核定义的入口点。入口点上的代码会切换到一个内核堆栈,并执行实现系统调用的内核代码。当系统调用完成,内核会切回用户栈并且通过 sret 指令返回用户空间,sret 指令降低硬件的特权级别,并且返回到用户进行系统调用的下一条指令继续执行。
总之,进程有两个设计思想:一个是地址空间,给每个进程都拥有自己的内存空间的错觉,另一个是线程,给每个进程都拥有自己的 CPU 的错觉。
xv6 如何启动
当机器上电,它会运行一个存储在只读内存中的引导程序(boot loader),引导程序会把 xv6 内核搬运到内存中,然后,在机器模式下,cpu 执行 xv6 的 _entry(kernel/entry.S),在开始时,riscv 会禁用分页硬件,虚拟地址直接映射到物理地址。
引导程序会把 xv6 内核搬运到内存物理地址 0x80000000 处,因为 0x0 到 0x80000000 之间包含 I/O 设备。
在 entry.S 中,会先初始化对应 cpu hart 的栈指针,然后跳转到 start(kernel/start.c)处执行。
在 start() 中,先将 mstatus 寄存器的 MPP(Previous Privilege mode)位设置成 Supervisor,然后将 mepc 寄存器设置为 main(kernel/main.c)函数的地址。这样的话在使用 mret 指令就可以将特权级别切换为 Supervisor,并且跳转到 main() 处执行。最后 start 中还会配置时钟中断,配置 machine-mode 的 mtvec寄存器。
在 main() 中,初始化许多设备和子系统后,将会调用 userinit(kernel/proc.c)来创建第一个进程。
在 userinit() 中,创建的进程代码为 initcode 里面的内容(user/initcode.S),在 initcode 中会请求 exec() 系统调用创建 init(user/init.c)进程,在 init.c 中会先创建 fd 0、1、2,然后 fork() 一个子进程来执行 shell,至此,整个系统启动完成。
三种IO
BIO(阻塞IO):线程发起IO请求,不管内核是否准备好IO操作,从发起请求起,线程一直阻塞,直到操作完成。
NIO(非阻塞IO):线程发起IO请求,立即返回;内核在做好IO操作的准备之后,通过调用注册的回调函数通知线程做IO操作,线程开始阻塞,直到操作完成。
AIO(异步非阻塞IO):线程发起IO请求,立即返回;内存做好IO操作的准备之后,做IO操作,直到操作完成或者失败,通过调用注册的回调函数通知线程做IO操作完成或者失败。
同步与异步
这两个概念与消息的通知机制有关。
同步:所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不返回。比如,调用readfrom系统调用时,必须等待IO操作完成才返回。
异步:当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者。比如:调用aio_read系统调用时,不必等IO操作完成就直接返回,调用结果通过信号来通知调用者。
阻塞和非阻塞
阻塞与非阻塞与等待消息通知时的状态有关。
阻塞:阻塞是指调用结果返回前,进程会被挂起,直到调用结束得到结果再唤醒进程。
非阻塞:非阻塞指在不能立刻获得返回结果之前,不会阻塞进程,进程可以立即返回,并且设置相应的 erron。
三、Lab:System calls
切换到 syscall 分支:
git fetch
git checkout syscall
make clean3.1 Using gdb
该部分主要教你怎么使用 gdb 来调试 xv6。
第一步
准备两个 shell 窗口。
第二步
在一个 shell 窗口内,运行如下指令(在 xv6 仓库里面运行):
make qemu-gdb运行后最下方会出现 tcp::26000 的字样,记住这个端口号 26000。

第三步
在另外一个 shell 运行如下命令(也要在 xv6 仓库里面运行):
gdb-multiarch然后在 gdb 命令窗口输入如下命令:
target remote localhost:26000接下来就可以开始调试了,使用 file 命令可以指定调试的文件:
file kernel/kernel使用 b 命令设置断点:
b syscall使用 c 让程序执行,直到断点处停下:
使用 layout src/asm 查看程序当前位置的源码或者汇编:
layout src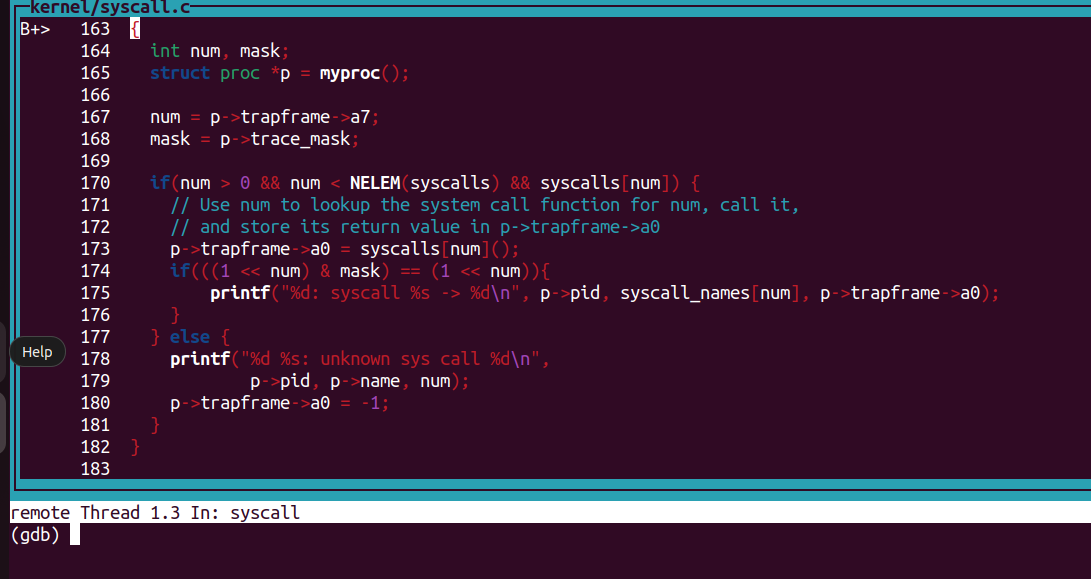
使用 backtrace 打印函数栈,如下,可以看到我们设置断点的 syscall() 在栈顶,usertrap() 则在其下,说明在 usertrap() 函数里面调用了 syscall():

使用 n 命令单步执行,跨过 struct proc *p = myproc() 这一行后,然后执行如下命令查看 p 指针指向的内容:
p /x *p
3.2 System call tracing (moderate)
这部分要实现 trace 命令,该命令能够追踪某条命令所执行的系统调用,并且打印出来,入参是一个 mask,指定要追踪哪些系统调用。
首先在 user/user.h 中定义系统调用,该文件中的定义是提供给用户调用的:
// user/user.h
int trace(int);其对应实现在 usys.S 中,在执行 make 后,usys.S 会由 usys.pl 脚本生成,这个汇编函数首先将系统调用号 SYS_trace 放入寄存器 a7 中,然后执行 ecall 指令请求系统调用:
.global trace
trace:li a7, SYS_traceecallret
执行 ecall 指令后,系统会进入内核态,此时即可执行真正的系统函数,先到 syscall.h 中定义 trace 的系统调用号:
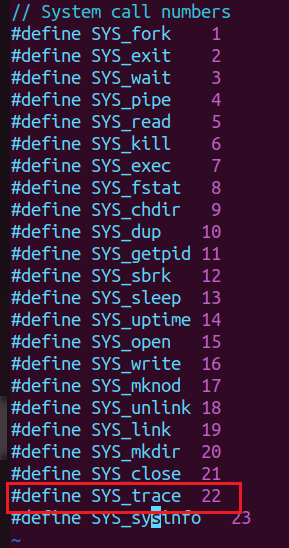
然后在 syscall.c 中加入 trace:
然后到 sysproc.c 定义系统函数 sys_trace():
uint64
sys_trace()
{int mask;argint(0, &mask);myproc()->trace_mask = mask;if(((1 << SYS_trace) & mask) == (1 << SYS_trace)){printf("%d: syscall trace -> 0\n", myproc()->pid);}return 0;
}
最后修改 syscall.c 的 syscall() 函数即可:
void
syscall(void)
{int num, mask;struct proc *p = myproc();num = p->trapframe->a7;mask = p->trace_mask;if(num > 0 && num < NELEM(syscalls) && syscalls[num]) {// Use num to lookup the system call function for num, call it,// and store its return value in p->trapframe->a0p->trapframe->a0 = syscalls[num]();if(((1 << num) & mask) == (1 << num)){printf("%d: syscall %s -> %d\n", p->pid, syscall_names[num], p->trapframe->a0);}} else {printf("%d %s: unknown sys call %d\n",p->pid, p->name, num);p->trapframe->a0 = -1;}
}
3.3Sysinfo (moderate)
这部分也要实现一个系统调用,可以返回一个结构体给用户,结构体里面包含了正在使用的进程个数,以及当前的空闲内存,这部分主要注意的地方就是内核空间的内存用户是访问不了的,所以需要使用 copyout 函数将用户空间的结构体拷贝到用户空间上,然后把结构体在用户空间上的地址返回即可。
系统调用的添加和上面一样。系统函数在 sysfile.c 里面声明:
uint64
sys_sysinfo(void)
{uint64 si_p; // user pointer to struct sysinfostruct sysinfo si;struct proc *p = myproc();argaddr(0, &si_p);si.freemem = get_free_memory();si.nproc = get_nproc();if(copyout(p->pagetable, si_p, (char *)&si, sizeof(si)) < 0)return -1;return 0;
}
获取正在使用的进程个数:
/* get the number of processes whose state is not UNUSED */
uint64 get_nproc(void)
{struct proc *p;uint64 num = 0;for(p = proc; p < proc + NPROC; p++){if(p->state != UNUSED){num++;}}return num;
}获取空闲内存:
/* collect the amount of free memory */
uint64
get_free_memory(void)
{struct run *r;uint64 num = 0;acquire(&kmem.lock);r = kmem.freelist;while(r){num++;r = r->next;}release(&kmem.lock);return num * PGSIZE;
}
这篇关于6.1810: Operating System Engineering <Lab2 syscall: System calls>的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





