本文主要是介绍Reinforcement Learning to Optimize Long-term User Engagement in Recommender Systems,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
强化学习可优化推荐系统中的长期用户参与度
- 摘要
- CCS概念
- 关键词
- ACM参考格式:
- 1 介绍
- 2 相关工作
- 2.1 传统推荐系统
- 2.2 基于强化学习的推荐系统
- 3 问题公式化
- 3.1 提要流建议
- 3.2 提要流的MDP配方
- 3.3用户参与和奖励功能
- 4推荐系统的政策学习
- 4.1 Q网络
- 4.1.1原始行为嵌入层
- 4.1.2分层行为层
- 4.1.3 Q值层
- 4.2 off政策学习任务
- 4.3模拟器学习
- 5模拟研究
- 5.1设置
- 5.2仿真结果
- 6真实世界电子商务数据集的实验
- 6.1数据集
- 6.2评估设置
- 6.3实验结果
- 7结论
摘要
推荐系统在我们的日常生活中起着至关重要的作用。 Feed提要流机制已广泛用于推荐系统,尤其是在移动应用程序上。 提要流设置为用户提供了永无休止的提要中的交互式推荐方式。在这种情况下,良好的推荐系统应更加注意用户的黏性,这远远超出了经典的即时量度,而且通常不是通过长期用户参与度来衡量的。直接优化长期用户参与度并非易事, 因为学习目标通常不适用于传统的有监督的学习方法。 尽管强化学习(RL)自然可以解决使长期奖励最大化的问题,但应用RL来优化长期用户参与度仍然面临挑战:用户行为具有多种建模能力,通常包括即时反馈(例如点击) 和延迟的反馈(例如,停留时间,再次访问); 另外,执行有效的-极化学习仍然不成熟,尤其是在结合自举和函数逼近时。
为了解决这些问题,在本文中,我们引入了RL框架-FeedRec,以优化长期的用户参与度。 FeedRec包含两个组件:1)在分层LSTM中设计的Q网络负责对复杂的用户行为进行建模,以及2)S网络,用于模拟环境,协助Q网络并消除策略收敛的不稳定性学习。 在合成数据和现实世界的大规模数据上的大量实验表明,FeedRec有效地优化了长期的用户参与度,并且其性能优于最新技术。
CCS概念
信息系统→推荐系统; 个性化; •计算理论→顺序决策。
关键词
强化学习;长期用户参与; 推荐系统
ACM参考格式:
邹立新,夏隆,丁卓业,宋嘉兴,刘卫东和尹大为。 2019。强化学习,以优化推荐系统中的长期用户参与度。 在2019年8月4日至8日举行的第25届ACM SIGKDD知识发现和数据挖掘会议(KDD '19)上,美国加利福尼亚州安克雷奇市.ACM,美国纽约州纽约市,共9页.https://doi.org/10.1145 /3292500.3330668
1 介绍
推荐系统通过建议最符合用户需求和偏好的商品(例如产品,新闻,服务)来帮助用户完成信息搜索任务。 在最近的提要流场景中,用户能够不断浏览由无休止提要生成的项目,例如Yahoo News1中的新闻流,Facebook2中的社交流以及Amazon3中的产品流。 具体来说,与产品流交互时,用户可以单击项目并查看项目的详细信息。 同时,由于许多多余或不感兴趣的项目的出现,他还可以跳过没有吸引力的项目并向下滚动,甚至离开推荐系统。 在这种情况下,优化点击不再是唯一的黄金法则。 最大化用户对与提要流的交互的满意度至关重要,这有两个方面:即时参与(例如,点击,购买); 长期参与(例如粘性)通常代表用户希望与流保持更长的时间并反复打开流的愿望[11]。
但是,大多数传统的推荐系统仅专注于优化即时指标(例如,点击率[12],转化率[19])。 随着交互作用的深入发展,一个好的提要流推荐系统不仅应该能够带来更高的点击率,而且还可以使用户积极地与系统交互,这通常是通过长期延迟的指标来衡量的。 延迟指标通常更为复杂,包括在应用程序上的停留时间,页面浏览的深度,两次访问之间的内部时间等等。 不幸的是,由于难以对延迟度量进行建模,直接优化延迟度量非常具有挑战性。 尽管只有少数初步工作[28]开始研究某些长期/延迟指标的优化,但仍需要一种系统化的解决方案来优化总体参与度指标。
直观地讲,强化学习(RL)旨在最大化长期奖励,它可能是一个统一的框架,可以优化即时和长期的用户参与度。 应用RL来优化长期用户参与本身并不是一个简单的问题。 如前所述,长期的用户参与非常复杂(即,以多种行为(例如,停留时间,重新访问)进行衡量),并且需要大量的环境交互来对这种长期行为进行建模并有效地建立推荐代理 。 结果,通过真实的在线系统从头开始构建推荐代理将是非常昂贵的,因为与未成熟推荐代理的大量交互将损害用户体验,甚至使用户烦恼。 一种替代方法是通过使用记录的数据来构建推荐代理,其中,策略学习方法可以减轻反复试验搜索的成本。 不幸的是,当前的方法(包括蒙特卡洛 MonteCarlo(MC)和时空差异(TD))在现实的推荐系统中对完整的政策学习存在局限性:基于MC的方法面临高方差的问题,特别是在现实应用中面临巨大的行动空间(例如数十亿个候选项目)时; 基于TD的方法通过使用自举技术进行估计来提高效率,但是,这又遇到了另一个臭名昭著的问题,称为致命三合会(Deadly Triad)(即,每当结合函数逼近,自举和线性训练时都会出现不稳定和发散的问题[24] )。 不幸的是,采用神经体系结构设计的推荐系统中的最新方法[33,34]不可避免地会遇到整个政策学习中的致命三合会问题。
为了克服上述复杂行为和完整策略学习的问题,我们在这里提出一个基于RL的框架,名为FeedRec,以提高推荐者系统中的长期用户参与度。 具体来说,我们将提要流建议正式化为马尔可夫决策过程(MDP),并设计了一个Q网络来直接优化用户参与度指标。 为了避免整体Q学习中收敛不稳定的问题,我们进一步引入了一个S-Network,用于模拟环境,以辅助策略学习。 在Q-Network中,为了捕获各种通用的用户长期行为的信息,LSTM对一个精细的用户行为链进行了建模,该链由所有粗略的行为组成,例如,单击,跳过,浏览,排序,驻留,重新访问等。 对这种细粒度的用户行为进行建模时,会出现两个问题:特定用户操作的数量极不平衡(即,点击比跳过少得多)[37]; 长期的用户行为更难以表示。 因此,我们进一步将带有时间单元的分层LSTM集成到QNetwork中,以表征细粒度的用户行为。
另一方面,为了有效利用历史记录数据并避免在线QLearning中的致命三合会问题,我们引入了一个称为S-network的环境模型来模拟环境并生成模拟的用户体验,从而协助进行在线政策学习。我们对综合数据集和真实世界的电子商务数据集都进行了广泛的实验。 实验结果表明,该算法在最先进的基线上可以有效地优化长时间的用户参与度。
贡献可以总结如下:
(1)我们提出一种强化学习模型-FeedRec,以直接优化Feed流推荐中的用户参与度(即时和长期用户参与度)。
(2)为了建模多种用户行为,通常包括即时参与(例如,单击和订购)和长期参与(例如,停留时间,重新访问等),提出了具有分层LSTM体系结构的Q网络。
(3)为了确保在政策学习中的融合,设计了一种有效且安全的培训框架。
(4)实验结果表明,我们提出的算法优于最新的基线。
2 相关工作
2.1 传统推荐系统
现有的大多数推荐系统试图平衡即时度量和因素,即推荐的多样性和新颖性。 从即时指标的角度来看,有许多工作致力于改善用户的隐式反馈点击[10、12、27],显式评分[3、17、21]和推荐项目的停留时间[30]。 实际上,已经批评即时度量标准不足以度量和表示用户的真实参与度。 作为补充,已经提出了旨在通过推荐各种项目来提高用户满意度的方法[1、2、4]。 但是,所有这些工作都无法对与用户的迭代交互进行建模。 此外,这些工作都不能直接优化长期用户参与的延迟指标。
2.2 基于强化学习的推荐系统
提出了上下文强盗解决方案来建模与用户的交互并处理在线推荐中臭名昭著的探索/利用困境[8,13,20,26,31]。 一方面,这些背景性强盗设置假设用户的兴趣保持不变或平稳漂移,这在Feed流机制下是无法保持的。 另一方面,虽然吴等 [28]提出优化延迟的访问时间,没有系统的解决方案来优化用户参与的延迟度量。 除了上下文强盗之外,在推荐任务中还提出了一系列基于MDP的模型[5,14,15,23,32,35,39]。 Arnold等。 [5]提出了一种改进的DDPG模型来解决大离散空间的问题。最近,Zhaoetal。结合了页面学习,成对排序技术和强化学习[33,34]。 由于仅考虑即时度量,因此上述方法无法优化用户参与的延迟度量。 在本文中,我们提出了一种基于MDP的系统解决方案,用于跟踪用户的兴趣转移,并直接优化基本指标和用户参与度的延迟指标。
3 问题公式化
3.1 提要流建议
在提要流推荐中,推荐系统以离散的时间步长与用户u∈U交互。 在每个时间步长t,代理将其馈入一个项目并接收用户的反馈ft,其中it∈I来自可推荐项目集,而ft∈F是用户对其的反馈/支持,包括单击,购买或跳过 交互过程形成一个序列Xt = {u,(i1,f1,d1),…。 。 。 ,(it,ft,dt)},其中dt作为推荐的停留时间,它表示用户对推荐的偏好。 给定Xt,代理需要为下一个步骤生成it + 1,以最大程度地提高长期用户参与度(例如,总点击次数或浏览深度)。 在这项工作中,我们专注于如何在提要流场景中提高所有项目的预期质量。
3.2 提要流的MDP配方
一个MDP由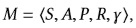 定义,其中S是状态空间,A是动作空间,P:S×A×S→R是转移函数,R:S×A→ R是平均奖励函数,其中r(s,a)是(s,a)的直接优度,而γ∈[0,1]是折现因子。 (静态)策略π:S×A→[0,1]为每个状态s∈S分配行为分布,其中a∈A的概率为π(a | s)。 在提要流推荐中,将
定义,其中S是状态空间,A是动作空间,P:S×A×S→R是转移函数,R:S×A→ R是平均奖励函数,其中r(s,a)是(s,a)的直接优度,而γ∈[0,1]是折现因子。 (静态)策略π:S×A→[0,1]为每个状态s∈S分配行为分布,其中a∈A的概率为π(a | s)。 在提要流推荐中,将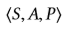 设置如下:
设置如下:
• 状态S是一组状态。 我们将时间步长t的状态设计为浏览序列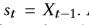 。 开头,s1 = {u}仅包含用户信息。 在时间步长t处,st = st-1⊕{(it-1,ft-1,dt-1)}更新为旧状态st-1,集中了推荐项目,反馈和停留时间(it- 1,ft-1,dt-1)。
。 开头,s1 = {u}仅包含用户信息。 在时间步长t处,st = st-1⊕{(it-1,ft-1,dt-1)}更新为旧状态st-1,集中了推荐项目,反馈和停留时间(it- 1,ft-1,dt-1)。
• 动作A是一组有限的操作。 可用的动作取决于状态,表示为A(s)。 A(s1)用所有召回的项目初始化。 通过从A(st-1)删除推荐项来更新A(st),并且动作at是推荐项it。
• 转换P是转换函数,其中p(st + 1 | st,it)是在st采取动作后看到状态st + 1的概率。 在我们的案例中,不确定性来自用户的反馈 ft w.r.t. it and st。
3.3用户参与和奖励功能
如上所述,与传统建议不同,即时度量(点击,购买等)不是用户参与度/满意度的唯一度量,而长期参与度甚至更重要,这通常以延迟度量来度量,例如浏览深度,用户重新访问和在系统上停留的时间 。 强化学习提供了一种通过奖励功能设计直接优化即时和延迟指标的方法。
奖励函数R:S×A→R可以设计为不同的形式。在此情况下,线性假设每个步骤t的用户参与奖励rt(mt)为以不同指标的加权总和的形式::

其中mt是由不同度量组成的列向量,ω是权重向量。 接下来,我们给出一些奖励函数w.r.t. 即时指标和延迟指标。
即时指标
在即时用户参与中,我们可以进行点击,购买(在电子商务中)等。即时指标的共同特征是这些指标是由当前操作立即触发的。 我们以点击为例,将第t次反馈中的点击次数定义为click mc t的指标,
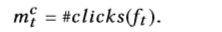
延迟的指标
延迟的指标包括浏览深度,系统停留时间,用户重新访问等。此类指标通常用于衡量长期用户参与度。 延迟的指标是由先前的行为触发的,其中某些行为甚至具有长期依赖性。 我们在此提供了两个用于延迟指标的奖励函数示例:
深度指标
浏览深度是一种特殊的指标,表明由于无限滚动机制,提要流方案与其他类型的推荐有所不同。 在查看了第三个提要之后,如果用户仍留在系统中并向下滚动,则系统应该对该提要进行奖励。 直观地,可以将深度指标 md t定义为:
其中#scans(ft)是第t个反馈中的扫描次数。
返回时间指标
当用户对推荐项目感到满意时,将更频繁地使用该系统。 因此,两次访问之间的间隔时间可以反映用户对系统的满意度。 返回时间mr t可设计为时间的倒数:
其中vr表示两次访问之间的时间,而β是超参数。
从上面的示例(单击指标,深度指标和返回时间指标)中,我们可以清楚地看到![mt = [mc t,md t,mr t]⊤](https://img-blog.csdnimg.cn/20200524030539612.png) 。 请注意,在MDP设置中,累积奖励将被最大化,也就是说,将来实际上会优化总浏览深度和访问频率,这通常是长期的用户参与。
。 请注意,在MDP设置中,累积奖励将被最大化,也就是说,将来实际上会优化总浏览深度和访问频率,这通常是长期的用户参与。
4推荐系统的政策学习
为了估算未来的奖励(即未来的用户粘性),建议的预期长期用户参与度将Q值表示为:
其中γ是折现因子,用于平衡当前奖励和未来奖励的重要性。 最优Q *(st,it)具有最优策略可获得的最大预期报酬,应遵循最优Bellman方程[24],
给定Q *,建议选择最大Q *(st,it)。 然而,在具有大量用户和项目的现实世界推荐系统中,估计每个状态-动作对的动作值函数Q *(st,it)是不可行的。因此,使用函数逼近(例如神经网络)来估计动作值函数(即Q ∗(st,it)≈Q(st,it;θq))更加灵活和实用。在实践中,神经网络非常适合跟踪用户对推荐的兴趣[10,12,36]。 在本文中,我们将参数为θq的神经网络函数逼近器称为Q网络。 可以通过最小化均方损失函数来训练Q网络,定义如下:
其中M = {(st,it,rt,st + 1)}是一个大型的重放缓冲区,用于存储过去的提要,并在小批量训练中从中获取样本。 通过相对于θq微分损失函数,我们得出以下梯度: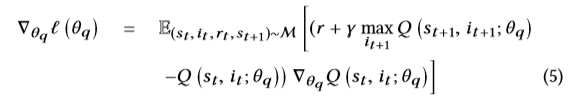
在实践中,通过随机梯度下降来优化损失函数通常在计算上是有效的,而不是在上述梯度中计算出全部期望值。
4.1 Q网络
Q-Network的设计对于性能至关重要。 在长期的用户参与度优化中,用户交互行为是多种多样的(例如,不仅单击,而且还有停留时间,重新访问,跳过等),这使建模变得不容易。 为了有效地优化这种参与,我们必须首先将先前的信息从这种行为中收集到Q-Network中。
4.1.1原始行为嵌入层
该层的目的是获取与长期参与有关的所有原始行为信息,以提取用户的状态以进行进一步优化。 给定观察值 ,我们将ft设为所有可能的用户行为类型,包括单击,购买或跳过,离开等,而dt表示行为的停留时间。 首先将整个{it}集转换为嵌入向量{it}。为了将反馈信息表示为项目嵌入,我们通过将嵌入与投影矩阵相乘来将{it}投影到与反馈相关的空间中,如下所示:
,我们将ft设为所有可能的用户行为类型,包括单击,购买或跳过,离开等,而dt表示行为的停留时间。 首先将整个{it}集转换为嵌入向量{it}。为了将反馈信息表示为项目嵌入,我们通过将嵌入与投影矩阵相乘来将{it}投影到与反馈相关的空间中,如下所示: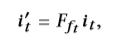
其中Fft∈RH×H是特定反馈的投影矩阵ft。为进一步建模时间信息,在我们的工作中,使用时间LSTM [38]跟踪一段时间内的用户状态,如下所示: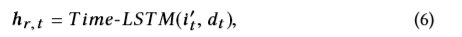
其中,Time-LSTM通过引入一个由dt控制的时间门来模拟停留时间,如下所示:
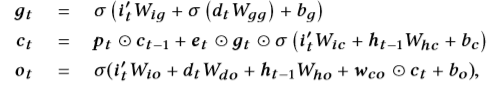
其中ct是存储单元。 gt是影响存储单元和输出门的时间相关门。pt是忘记门。 et是输入门。 ot是输出门,W ∗和b ∗是权重和偏置项。 ⊙是按元素乘积,σ是S型函数。 给定ct和ot,将隐藏状态hr,t建模为
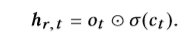
4.1.2分层行为层
为了捕获通用用户行为的信息,所有粗略的行为都会被不加区分地馈入原始的行为嵌入层。 实际上,特定用户操作的数量极不平衡(例如,单击次数少于跳跃次数)。结果,直接利用原始行为嵌入层的输出将导致Q网络从稀疏的用户行为中丢失信息,例如购买信息将被跳过信息掩埋。 此外,每种类型的用户行为都有其自己的特征:单击某项通常代表用户当前的偏好,购买某项可能意味着用户兴趣转移,并且跳过的因果关系有点复杂,这可能是随意浏览 ,中立或烦恼等。
为了更好地表示用户状态,如图1所示,我们建议在原始行为嵌入层中添加一个分层的行为层,使用不同的LSTM管道分别跟踪主要的用户行为(例如单击,跳过,购买),如下所示: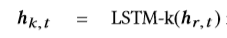
如果ft是第k个行为,
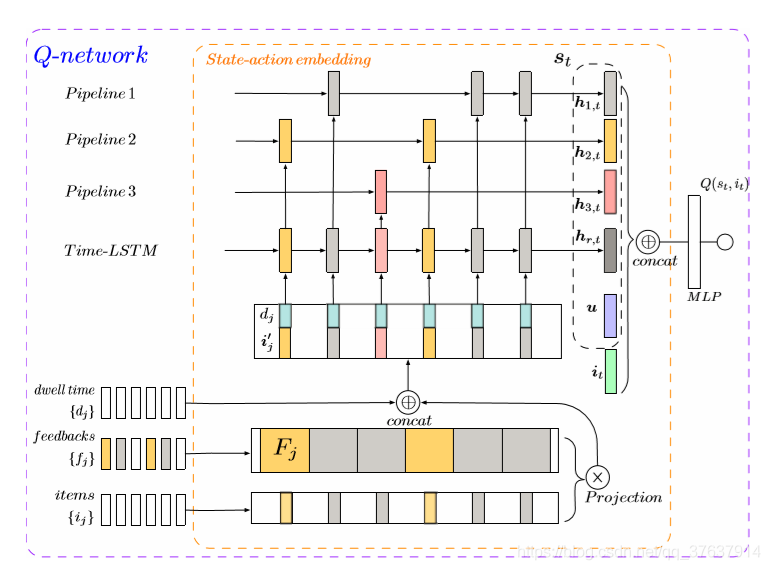
图1:Q-Network的体系结构。
其中相应的LSTM层捕获了不同的用户行为(例如,第k个行为),以避免强烈的行为优势并捕获特定特征。 最后,状态动作嵌入是通过将不同用户的行为层和用户配置文件串联在一起形成的: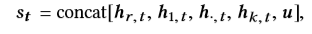
其中u是特定用户的嵌入向量。
4.1.3 Q值层
MLP通过密集状态嵌入和项目嵌入的输入来完成Q值的近似如下: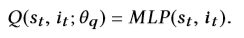
θq的值通过SGD用公式(5)计算的梯度进行更新。
4.2 off政策学习任务
使用建议的基于Q-Learning的框架,我们可以在学习稳定的推荐策略之前通过Trialand错误搜索在模型中训练参数。 但是,由于部署不令人满意的策略的成本和风险,几乎不可能在线培训策略。 另一种方法是在部署之前使用日志记录数据D训练合理的策略,并由日志记录策略πb进行收集。 不幸的是,方程(4)中的Q-Learning框架受到致命试验问题的困扰[24],每当结合函数逼近,自举和线性训练时,就会出现不稳定和发散的问题。
为了避免整体Q学习中的不稳定和差异性问题,我们进一步引入了一个用户模拟器(称为SNetwork),它可以模拟环境并协助策略学习。具体来说,在每轮推荐中,S-Network需要根据真实的用户反馈生成用户的响应ft,停留时间dt,重新访问的时间vr和二进制变量lt(指示用户是否离开平台)。 如图2所示,使用多头神经网络S-Network S(θs)可以完成模拟用户反馈的生成。 状态动作嵌入与Q-Network在相同的体系结构中进行设计,但是具有单独的参数。 层(st,it)在所有任务之间共享,而其他层(图2中(st,it之上))是特定于任务的。
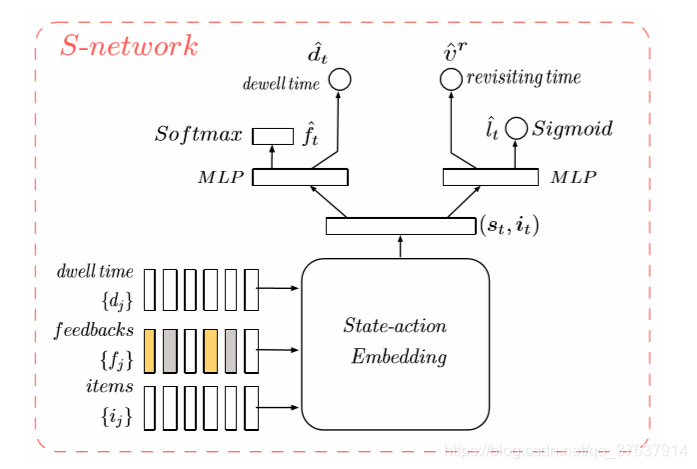
图2:S网络的体系结构。
由于停留时间和用户的反馈是会话的内部行为,因此对ˆf t和ˆ dt的预测计算如下: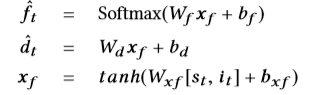
其中,w *和b *是权重和偏差项。[st,it]是状态动作特征的集中。重新生成时间并离开平台(会话间行为)的生成如下
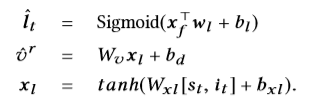
4.3模拟器学习
在此过程中,S(st,it;θs)使用D中的已记录数据通过微型批处理SGD进行精炼。由于已通过记录策略πb收集了已记录数据,因此直接使用此类已记录数据构建模拟器会导致 选择基础。 为了使登录策略πb[22]的影响失衡,将重要性加权损失最小化如下:
算法1:对FeedRec进行优化训练。


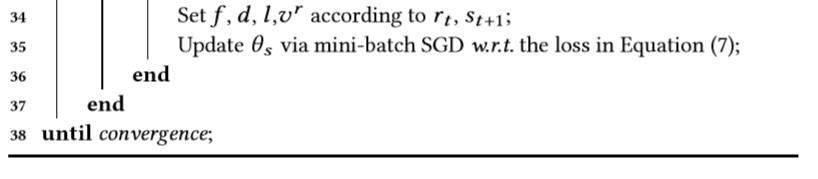
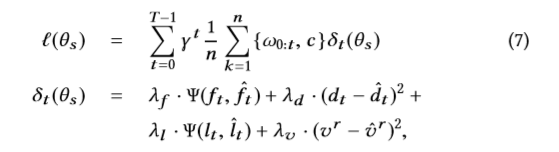
其中,n是记录的数据中的轨迹总数。 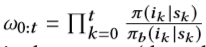
是减小π与πb之间差异的重要性比(从Q网络派生的策略,例如ϵ-greedy),Ψ( ·,·)是交叉熵损失函数,c是避免太大的重要性比的超参数。δt(θs)是一个结合了两个分类损失和两个回归损失的多任务损失函数,λ∗是控制不同任务重要性的超参数 。
由于从Q网络派生的π随着θq的更新而不断变化,以保持对中间策略的适应性,因此S网络也根据π进行更新以获得定制的最优精度 。最后,我们实现了交互式训练过程,如算法1所示,在其中指定了每次迭代中它们发生的顺序。
5模拟研究
我们通过模拟直接优化用户参与度指标,展示了FeedRec满足用户兴趣的能力。 我们使用综合数据集,以便我们了解最大限度地提高用户参与度的“基本事实”机制,并可以轻松地检查算法是否确实可以学习使延迟的用户参与度最大化的最佳策略。
5.1设置
形式上,我们生成M个用户和N个项目,每个项目与广告维度主题参数向量ϑ∈Rd相关联。 对于M个用户 和N个项目
和N个项目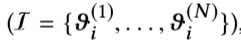 , 主题向量初始化为
, 主题向量初始化为
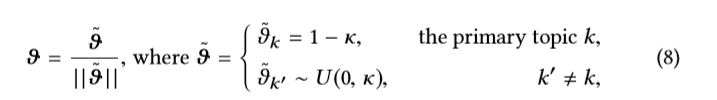
在非主要主题上,控制权会引起人们极大的关注。 具体来说,我们将用户向量和项目向量的维数设置为10。一旦项目向量ϑi初始化,它在仿真中将保持不变。 在每个时间步骤t,代理将I中的一项ϑi馈给一个用户ϑu。 用户检查提要并基于“满意度”给出反馈,例如单击/跳过,离开/停留(深度度量)和重新访问(返回时间度量)。 具体来说,点击的概率由余弦相似度确定为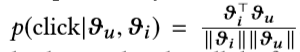
对于请假/逗留或再次访问,这些反馈与所有提要有关。 在仿真中,我们假设这些反馈是由推荐列表的平均熵决定的,因为许多现有的作品[1、2、4]都认为多样性能够提高用户对推荐结果的满意度。 同样,分集也是延迟指标[29,39],它可以验证FeedRec是否可以优化延迟指标。
5.2仿真结果
现有的一些作品[1、2、4]假定多样性能够提高用户对推荐结果的满意度。 实际上,这是一种优化用户参与度的间接方法,多样性在这里起到了实现这一目标的重要作用。 现在,我们验证提出的FeedRec框架具有通过不同形式的多样性直接优化用户参与度的能力。 为了生成仿真数据,我们遵循流行的分集假设[1、2、4]。 这些作品试图增强多样性以实现更好的用户参与度。 但是,不清楚多样性将在多大程度上导致最佳的用户参与度。 因此,追求多样性可能不会导致用户满意度的提高。
我们假设用户参与度与推荐列表多样性之间存在两种关系。
1)线性风格。在线性关系中,较高的熵带来更大的满足感,即较高的熵吸引用户浏览更多项目并更频繁地使用系统。用户在检查馈送项目后留在系统中的概率设置为:
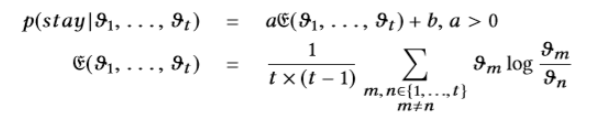
其中 是推荐项列表,
是推荐项列表,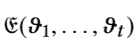 是项的平均熵。 a和b用于缩放范围(0,1)。 两次访问的间隔天数设置为:
是项的平均熵。 a和b用于缩放范围(0,1)。 两次访问的间隔天数设置为: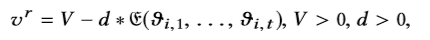
其中V和d是使vvr为正的常数。
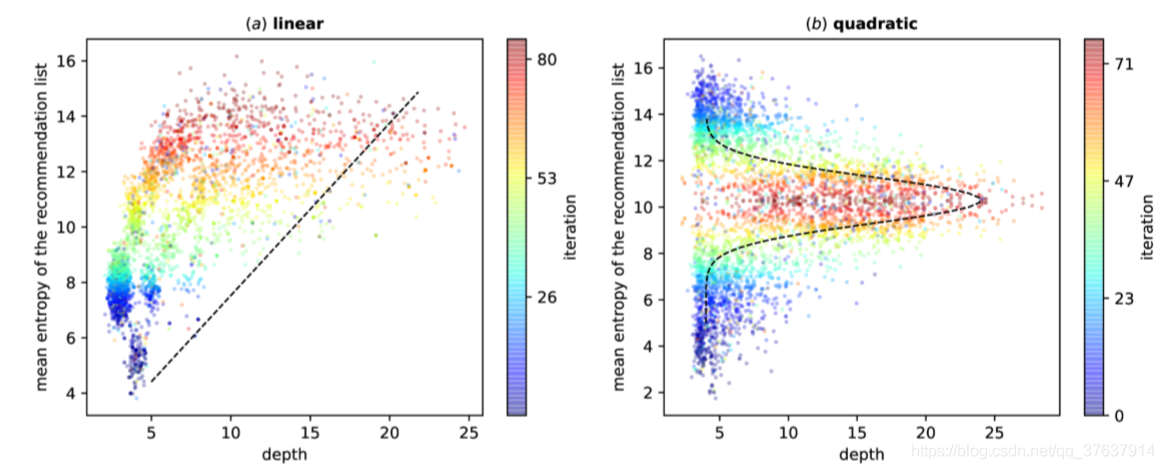
图3:用户兴趣和浏览深度的不同分布。虚线表示向下滚动和熵的分布((a)中为线性,(b)中为二次)。 彩色条以训练短语显示交互迭代,从蓝色到红色。 所有用户的平均浏览深度显示为点。
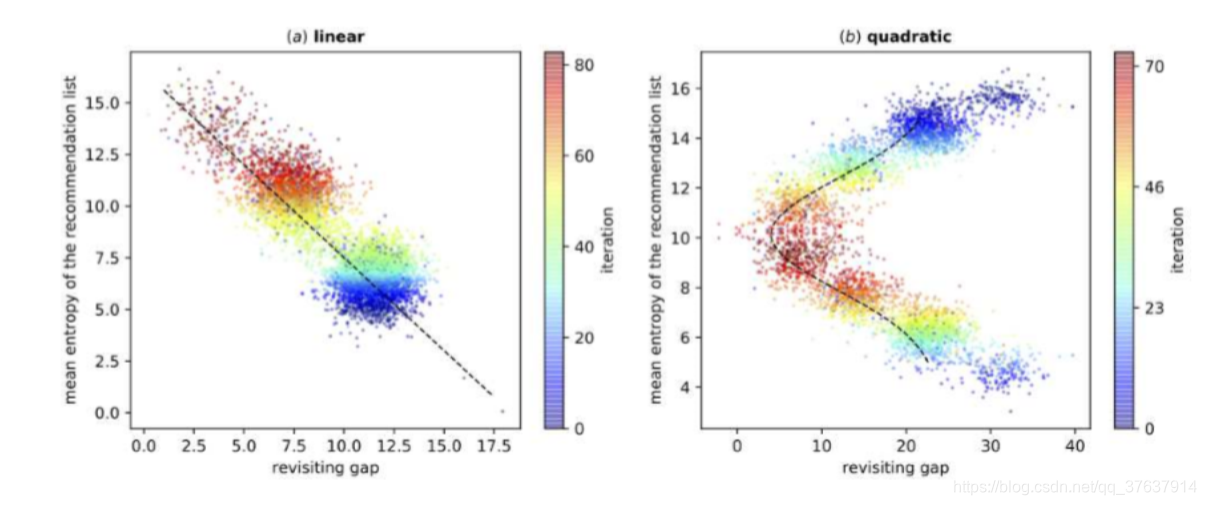
图4:用户兴趣的不同分布以及两次访问之间的间隔天数。 虚线表示返回时间和熵的分布((a)中为线性,(b)中为二次)。 颜色栏以蓝色表示训练短语中的交互迭代。 所有用户的平均返回时间显示为点。
2)二次风格。 在二次关系中,适度的熵使最佳满足。 用户在检查馈送项目后留在系统中的概率设置为:
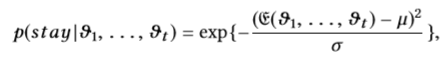
其中µ和σ是常数。 同样,两次访问的间隔天数设置为:
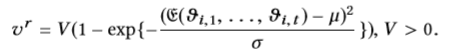
按照“用户”与系统代理之间的上述交互过程,我们生成了1,000个用户,5,000个项目和200万个情节进行培训。
我们在此报告平均浏览深度和返回时间 每个训练步骤的线性或二次关系是不同的,蓝色点位于较早的训练步骤,红色点位于较晚的训练步骤。
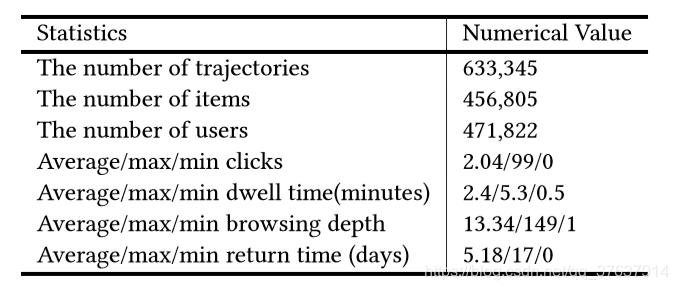
表1:数据集摘要统计。
从图3和图4的结果可以看出,无论是什么多样性假设,FeedRec都可以通过直接优化延迟指标来收敛到最佳多样性。 在图3(以及图4)的(a)中,FeedRec公开了推荐列表和浏览深度(以及返回时间)的熵分布是线性的。 随着互动次数的增加,用户的满意度逐渐提高,因此浏览了更多项目(两次访问之间的内部时间更短)。 在(b)中,用户参与度在特定的熵中最高,熵的较高或较低会引起用户的不满。 因此,推荐列表的适度熵将吸引用户浏览更多项目并更频繁地使用推荐系统。 结果表明,FeedRec能够在用户参与度和推荐列表的熵之间确定不同的分布类型。
6真实世界电子商务数据集的实验
6.1数据集
我们在2018年7月从一个电子商务平台收集了17天用户的访问日志。 每个访问日志都包含:时间戳记,用户ID u,用户配置文件(up∈R20),推荐项id it,行为策略对项πb(it | st)的排名得分,以及用户的反馈ft,停留时间dt。 由于数据集的稀疏性,我们使用预先训练的向量来初始化项目的嵌入(i∈R20),这是通过使用skip-gram [16]对用户的点击流进行建模来学习的。 用户的嵌入u随用户的配置文件初始化。 返回的差距计算为连续用户访问的间隔天数。 表1显示了数据集的统计信息。
6.2评估设置
线上A / B测试
要根据实际情况对RL方法进行评估,一种直接的方法是通过在线A / Btest评估学习到的策略,但是这样做可能会非常昂贵,并且可能会损害用户体验。 由[6,7]建议,使用特定的O-policy估算器NCIS [25]来评估不同推荐者的绩效。 NCIS的逐步变式定义为
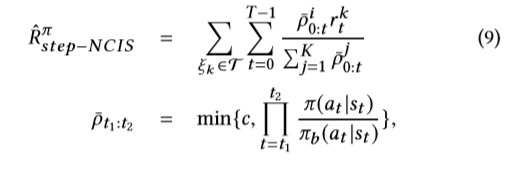
其中ρt1:t2是重要性比率的最大上限,T = {ξk}是用于评估的轨迹ξk的集合,K是总测试轨迹。 等式(9)的分子是上限重要性加权奖励,分母是归一化因子。 通过不同的指标设置rt,我们可以从不同的角度评估策略。 为了使实验结果可靠可靠,我们将前15天的记录作为训练样本,最后2天作为测试数据,将测试数据隔离。 训练样本用于策略学习。 测试数据用于策略评估。 为了确保较小的方差并控制偏差,我们在实验中将c设置为5。
指标
在方程式(9)中设置不同的用户参与度指标的奖励,我们可以估算出一套全面的评估指标。 正式地,这些指标定义如下:
•每个会话的平均点击次数:用户访问期间的平均累计点击次数。
•每个会话的平均深度:用户与推荐代理交互的平均浏览深度。
•平均返回时间:用户连续访问到特定时间点之间的平均回访天数。
基线
我们将模型与最新的基准进行比较,包括基于监督学习的方法和基于强化学习的方法。
•FM:分解机[21]是一个强大的分解模型,可以通过分解机库(libFM)4轻松实现。
•NCF:基于神经网络的协作过滤[9]用神经体系结构替换了分解模型中的内部乘积,以支持数据的任意功能。
•GRU4Rec:这是一种代表性的方法,它利用RNN来学习推荐系统中客户和商品的动态表示[10]。
•NARM:这是具有RNN模型的基于个人轨迹的最新方法建议[12]。 它使用注意力机制确定下一次购买轨迹中过去购买的相关性。
•DQN:深度Q网络[18]将Q学习与深度神经网络相结合。 我们使用与FeedRec相同的函数逼近,并使用记录的数据集通过朴素的Q学习训练神经网络。
•DEER:DEER [34]是一种基于DQN的方法,通过成对训练来最大化用户的点击量,该方法考虑了用户的负面行为。
•DDPG-KNN:使用KNN的深度确定性策略梯度[5]是用于处理大型操作空间的DDPG的离散版本,已在[33]中部署用于Pagewise推荐。
•** FeedRec**:为了验证不同组件的效果,对退化的模型进行了以下实验:1)SNetwork完全基于我们提出的S-Network,它根据下一个可能单击的项目的排名提出建议。 2)FeedRec(C),FeedRec(D),FeedRec(R)和FeedRec(All)是我们提出的以不同指标作为奖励的方法。具体来说,他们分别将点击次数,深度,返回时间以及即时指标和延迟指标的加权总和用作奖励函数。
表2:JD数据集上不同代理的性能比较。
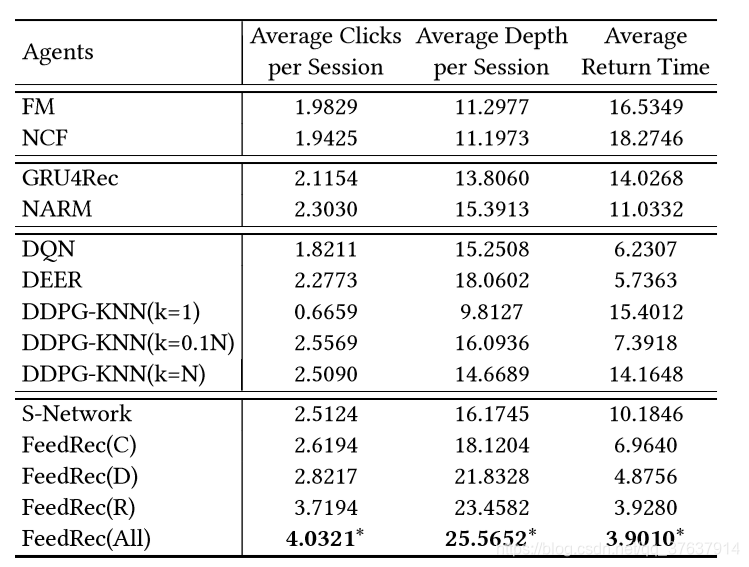
“ *”表示在最佳基准上有统计学上的显着改善(即,p <0.01的双向t检验)。
实验设置
不同度量的权重ω设置为[1.0,0.005,0.005]⊤。 对于Q-Network和S-Network,LSTM的隐藏单位均设置为50。 所有基线模型共享神经网络的相同层和隐藏节点配置。 Q学习的缓冲区大小设置为10,000,批处理大小设置为256。ϵ贪婪总是用于学习中的探索,但随着训练时间的增加而减少。 剪裁重要性采样的值c设置为5。我们设置折现因子γ= 0.9。 网络使用SGD进行训练,学习率为0.005。 我们使用Tensor flow(张量流)使用Nvidia GTX 1080 ti GPU卡来实现管线和训练有素的网络。 通过平均5次重复运行获得所有实验。
6.3实验结果
与基准的比较
我们将FeedRec与最先进的方法进行了比较。 表2显示了真实世界数据集上三个指标的所有方法的结果。从结果中,我们可以看到FeedRec在所有指标上的表现均优于所有基线方法。 我们对方法在所有基线上的改进进行了显着性测试(ttest)。 “ *”表示p值<0.01的明显差异。 结果表明,就所有评估措施而言,改进是显着的。
权重ω的影响
权重ω控制奖励功能中不同用户参与度的相对重要性。 我们研究了权重ω的影响。 图5的(a)和(b)示出了ω w.r.t 深度指标和返回时间指标的参数灵敏度。 在图5中, 随着深度和返回时间度量标准ω权重的增加,用户浏览更多项目并更频繁地重新访问该应用程序(蓝线)。 同时,在(a)和(b)中,当ω设置为0.005时,该模型在累积点击次数指标(橙色线)中均达到最佳结果。 这些指标的权重过大将压倒奖励点击的重要性,这表明深度和返回时间权重的适中值确实可以提高累积点击的效果。
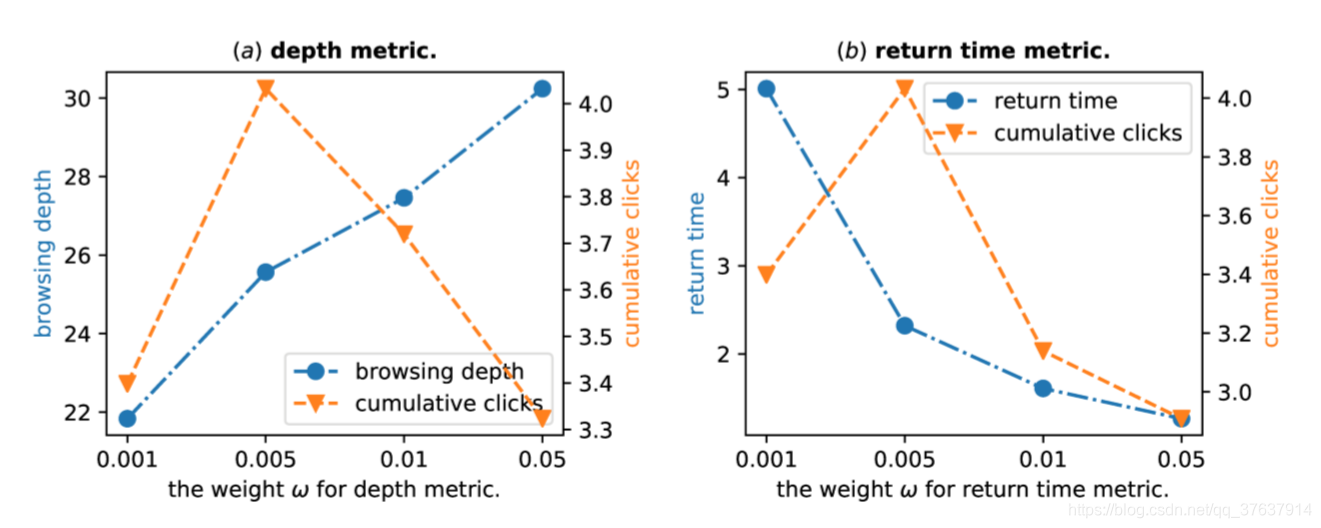
图5:ω对性能的影响。
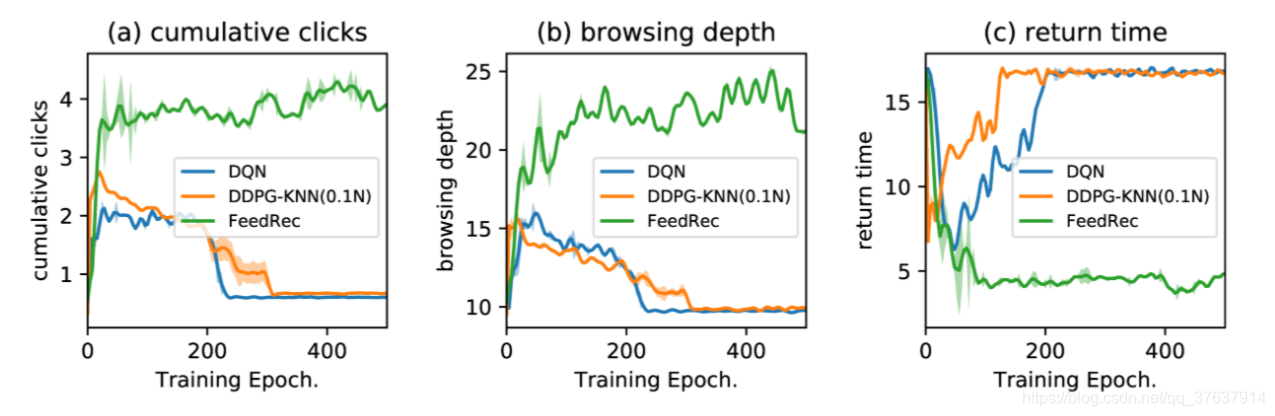
图6:精益学习下FeedRec与基线之间的比较。
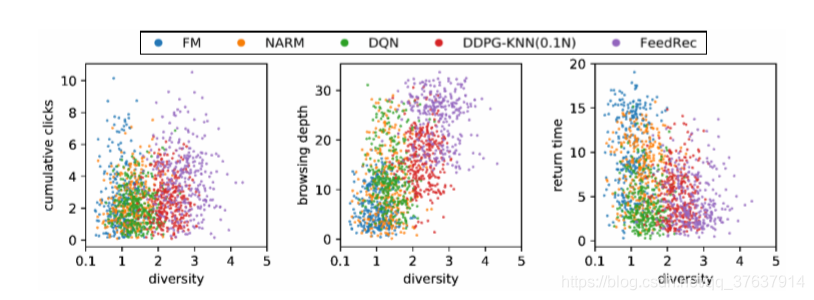
图7:用户参与度与多样性之间的关系。
S网络的效果。
臭名昭著的致命三合会问题带来了大多数国家政策学习方法甚至稳定的Q学习的不稳定和分歧的危险。 为了检验我们提出的交互式训练框架的优势,我们在相同配置下将我们提出的模型FeedRec与DQN,DDPG-KNN进行了比较。 在图6中,我们显示了不同的指标与训练迭代之间的关系。 我们发现DQN,DDPG-KNN在大约40次迭代中达到了性能峰值,并且随着迭代次数的增加(橙色线和蓝色线),性能迅速下降。 相反,FeedRec可以在这三个指标上获得更好的性能,并且在最高值(绿线)下性能稳定。 这些观察表明,FeedRec可以通过避免推荐政策的政策学习中的致命三重问题来保持稳定和适用。
用户参与度与多样性之间的关系
一些现有的作品[1、2、4]假定用户参与度和多样性是相关的,并且旨在通过增加多样性来增加用户参与度。 实际上,这是一种优化用户参与度的间接方法,并且该假设尚未得到验证。 在这里,我们进行了实验,以查看直接优化用户参与度的FeedRec是否具有改善推荐多样性的能力。 对于每个策略,我们对300个状态/动作对进行采样,重要性对比率ρ> 0.01(等式(9)中ρ的较大值表示该策略更喜欢此类动作),并绘制这些状态/动作对,如图所示 在图7中,水平轴指示推荐项之间的差异,垂直轴指示用户参与的不同类型(例如,浏览深度,返回时间)。我们可以看到,通过直接优化用户参与度而学习到的FeedRec政策有利于推荐更多不同的商品。 结果证明,用户满意度的优化可以增加推荐的多样性,增强多样性也是提高用户满意度的一种手段。
7结论
在推荐系统中,尤其是在提要流设置中,优化长期用户参与至关重要。 尽管RL自然可以解决使长期奖励最大化的问题,但在优化长期用户参与度方面应用RL仍然存在一些挑战:难以建模各种用户反馈(例如,点击,停留时间,重新访问等)以及在推荐系统中进行有效的政策学习。 为了解决这些问题,在这项工作中,我们引入了一个基于RL的框架FeedRec,以优化长期的用户参与度。 首先,FeedRec利用分层RNN对复杂的用户行为进行建模,称为Q网络。 然后,为了避免策略学习收敛的不稳定,设计了一个S网络来模拟环境并辅助Q网络。 在合成数据集和现实世界电子商务数据集上的大量实验已经证明了FeedRec对提要流推荐的有效性。
这篇关于Reinforcement Learning to Optimize Long-term User Engagement in Recommender Systems的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





