本文主要是介绍torch.nn.batchnorm1d,torch.nn.batchnorm2d,torch.nn.LayerNorm解释:,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
批量归一化是一种加速神经网络训练和提升模型泛化能力的技术。它对每个特征维度进行标准化处理,即调整每个特征的均值和标准差,使得它们的分布更加稳定。
Batch Norm主要是为了让输入在激活函数的敏感区。所以BatchNorm层要加在激活函数前面。
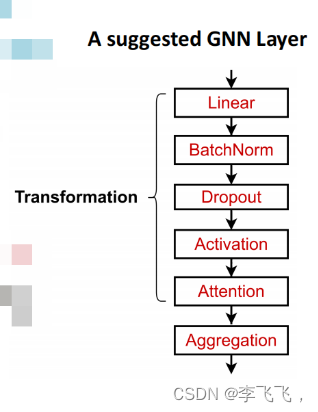
1.torch.nn.batchnorm1d:
(1)归一化处理公式:
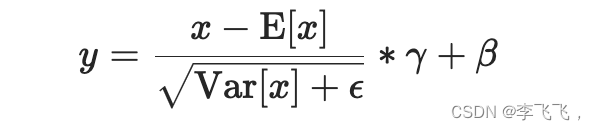
- E(x)表示样本某一维的均值,
- Var(x)表示样本某一维的方差;计算方差的时候使用的是有偏估计,计算方差的时候分母为 N 而不是N − 1 ;
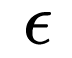 为分母上加的一个值,是为了防止分母为0的情况,让其能正常计算
为分母上加的一个值,是为了防止分母为0的情况,让其能正常计算- r 初始化值为1,
- b 初始化值为0;
(2)参数解释:
torch.nn.BatchNorm1d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)-
num_features – 输入维度,也就是数据的特征维度;就是你需要归一化的那一维的维度。函数的input可以是二维或者三维。当input的维度为(N, C)时,BN将对C维归一化;当input的维度为(N, C, L) 时,归一化的维度同样为C维。
-
eps – 是在分母上加的一个值,是为了防止分母为0的情况,让其能正常计算;
-
momentum – 移动平均的动量值。
-
affine – 一个布尔值,设为True时,BatchNorm层才会学习参数 γ 和 β ,初始值分别是1和0;否则不包含这两个变量,变量名是weight和bias
(3)使用:
二维数据:在列的维度上进行归一化,批量归一化就是对每个特征维度进行标准化处理;使其均值为0,方差为1 ;
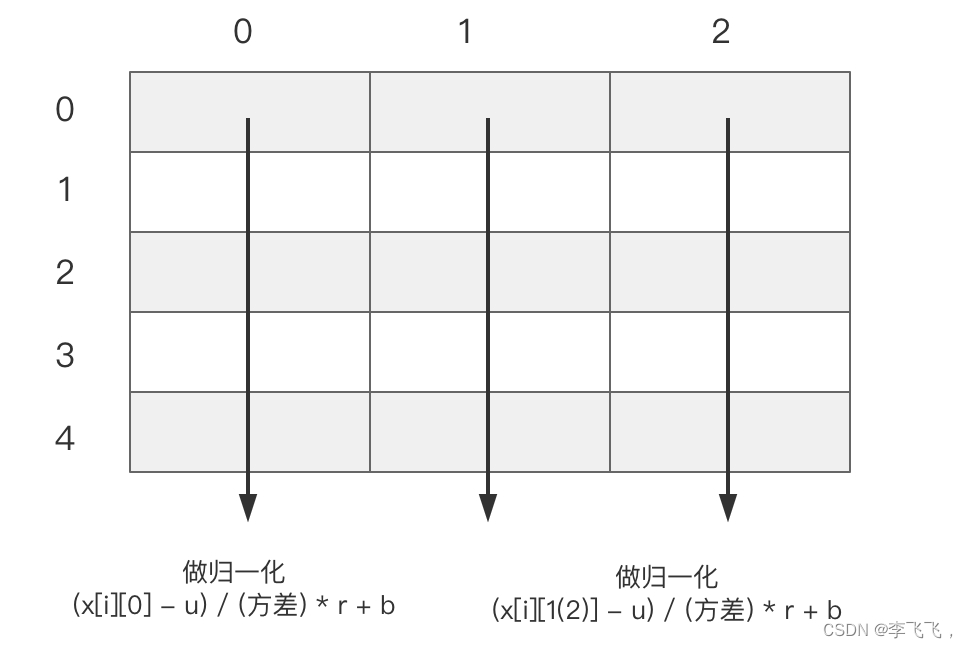
这个5*3的数据表示的是节点数为 5,每个节点的特征维度是 3,我们是对每一列的特征进行处理, 而不是对每一行的数据进行处理;
三维数据:
- 输入数据为(batch,N,feature),构建一个三维立方体,BatchNorm1d在三维数据上相当于在每一个横截面上计算。(注意横截面的数据一起规则化-->就是把这batch个二维数据横着摆放,然后对每一行数据进行归一化处理,使其均值为0,方差为1,处理完后再恢复原状);
- 就是对 N 这一维的数据进行处理;
(4)例子:
第一种,输入数据是二维时:
import torch
import torch.nn as nn
x = torch.tensor([[0, 1, 2],[3, 4, 5],[6, 7, 8]], dtype=torch.float)
print(x)
print(x.shape) # x的形状为(3,3)
m = nn.BatchNorm1d(3) # num_features的值必须为形状的最后一数3
y = m(x)
print(y)
# 输出的结果是
tensor([[0., 1., 2.],[3., 4., 5.],[6., 7., 8.]])
torch.Size([3, 3])
tensor([[-1.2247, -1.2247, -1.2247],[ 0.0000, 0.0000, 0.0000],[ 1.2247, 1.2247, 1.2247]], grad_fn=<NativeBatchNormBackward0>)说明就是: BatchNorm就是取出每一列的数做归一化

第二种,输入数据是三维时:
x = torch.tensor([[[0, 1, 2],[3, 4, 5]],[[6, 7, 8],[9, 10, 11]]], dtype=torch.float)
print(x)
print(x.shape) # x的形状为(2,2,3)
m = nn.BatchNorm1d(2) # num_features的值必须第二维度的数值,即通道数2
y = m(x)
print(y)
# 输出的结果是
tensor([[[ 0., 1., 2.],[ 3., 4., 5.]],[[ 6., 7., 8.],[ 9., 10., 11.]]])
torch.Size([2, 2, 3])
tensor([[[-1.2865, -0.9649, -0.6433],[-1.2865, -0.9649, -0.6433]],[[ 0.6433, 0.9649, 1.2865],[ 0.6433, 0.9649, 1.2865]]], grad_fn=<NativeBatchNormBackward0>)
2.torch.nn.LayerNorm
二维输入:
首先考虑最简单的情形,也就是形状为 (N,C) 的二维输入,这里的N指的是样本的个数,C指的是特征的维度。这种输入下的BatchNorm和LayerNorm其实很好理解,不妨假设N=2,C=3,此时的输入可以表示如下,每一行代表一个样本的特征向量:
、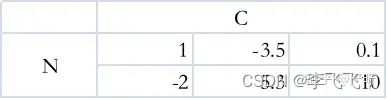
BatchNorm1d就是取出每一列的2个数做归一化:
LayerNorm就是取出每一行的3个数做归一化:
3.torch.nn.batchnorm2d
处理的是四维的数据,我们暂时不用管;
可以参考:nn.BatchNorm讲解,nn.BatchNorm1d, nn.BatchNorm2d代码演示-CSDN博客
本文参考内容有:
详解torch.nn.BatchNorm1d的具体计算过程 - 知乎 (zhihu.com)
对比pytorch中的BatchNorm和LayerNorm层 - 知乎
这篇关于torch.nn.batchnorm1d,torch.nn.batchnorm2d,torch.nn.LayerNorm解释:的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






