本文主要是介绍《树莓派开发实战(第2版)》——1.3 Figaro简介:一种概率编程语言,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本节书摘来异步社区《概率编程实战》一书中的第1章,第1.3节,作者:【美】Avi Pfeffer(艾维·费弗),更多章节内容可以访问云栖社区“异步社区”公众号查看。
1.3 Figaro简介:一种概率编程语言
在本书中,您将使用一种称为Figaro的概率编程系统。(我用莫扎特的歌剧《费加罗的婚礼》中的角色为其命名。我喜爱莫扎特,并在该剧于波士顿的一次演出中饰演巴尔托洛医生。)本书的主要目标是教授概率编程的原则,在本书中学到的技术应该可以在其他概率编程系统上沿用。附录B简单描述了现有的一些系统。但是,本书还有第二个目标——帮助您获得创建使用概率程序的亲身体验,并提供可以立即使用的工具。因此,许多例子都用Figaro代码实现。
Figaro是从2009年开始开发的一个开源软件,在GitHub上维护。它以Scala库的形式实现。图1-9说明Figaro如何使用Scala实现概率编程系统。该图详细说明了图1-7,后者描述了概率编程系统的主要组成部分。让我们从概率模型开始,在Figaro中,该模型由任意数量的数据结构(称作“元素”)组成。每个元素代表在您的情境中可取任意数量值的一个变量。这些数据结构用Scala实现,您可以用这些数据结构编写Scala程序创建模型。可以通过关于元素值的信息提供证据,也可以指定希望在查询中了解的元素。至于推理算法,您可以选择一个Figaro内建推理算法并应用到模型上,根据证据回答您的查询。推理算法以Scala实现,其调用就是一个Scala函数调用。推理结果是查询元素不同值的概率。
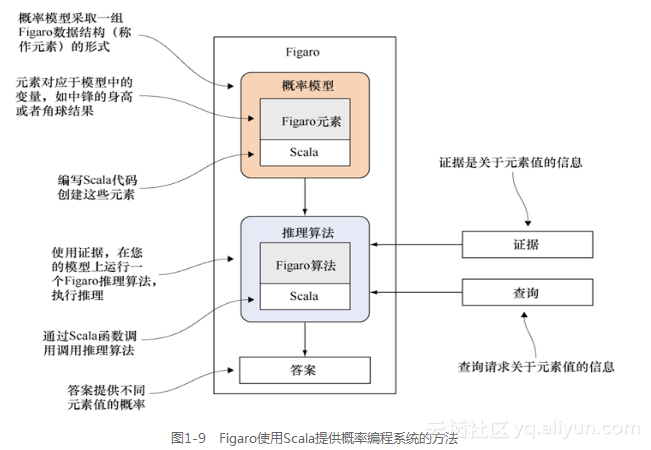
Figaro内嵌于Scala提供了一些重大优势。其中一些来自内嵌于通用宿主语言相对于独立概率语言的优势。其他优势则是因为Scala的良好特性。下面是在通用宿主语言中内嵌概率编程语言的好处。
证据可以用宿主语言的程序得出。例如,您可以编写一个程序读取一个数据文件,以某种方式处理其中的值,并将其作为证据提供给Figaro模型。在独立语言中,这一任务要难得多。
类似地,您可以在一个程序中使用Figaro提供的答案。例如,如果您有一个供足球队经理使用的程序,该程序可以取得进球概率,向经理提出建议。
可以在概率程序中嵌入通用代码。例如,假设您有一个模拟头球在空中飞行轨迹的物理模型,可以在Figaro元素中加入这个模型。
可以使用通用编程技术构建Figaro模型。例如,您可能有一个映射,包含对应于球队中所有球员的Figaro元素,并根据情况中涉及的球员选择对应的元素。
下面是选择Scala作为内嵌概率编程系统的宿主语言的一些理由。
Scala是一个函数式编程语言,因此Figaro也能得到函数式编程的好处。正如我在第2部分中所说明的,函数式编程对概率编程有帮助,许多模型可以自然地以函数式风格编写。
Scala是面向对象的,其优点之一是既是函数式语言,又具有面向对象的特征。Figaro也是面向对象的。正如第2部分中将要说明的,面向对象是表达概率编程中多种设计模式的有用手段。
最后,Figaro还有嵌入Scala之外的一些优势,包括:
Figaro能够表示极其广泛的概率模型。Figaro元素的值可以为任何类型,包括布尔型、整数、双精度数、数组、树、图等。这些元素之间的关系可以由任何函数定义。
Figaro提供了使用其条件和约束规定证据的丰富框架。
Figaro有多种多样的推理算法。
Figaro能够表示和推理随时间变化的动态模型。
Figaro能够在其模型中包含明确决策,并支持最优决策的推断。
由于多种原因,Figaro是学习概率编程的出色语言。
Figaro以Scala库的形式实现,可以用于Java和Scala程序,很容易与应用程序集成。
由于以程序库而非独立语言的形式实现,Figaro提供了宿主编程语言的全部功能,可以用来构建模型。Scala是高级的现代化语言,具有许多有用的程序组织功能,使用Figaro时可以自动获得这些好处。
从所提供算法的范围来看,Figaro 堪称全能。
本书强调使用的技术和实用的示例。只要有可能,我都会解释建模的一般原则,并描述在Figaro中的实现方法。不管您最终使用哪一种概率编程系统,这对您都将大有裨益。并不是所有系统都能轻松地实现本书中的所有技术。例如,现有的面向对象概率编程系统很少。但是有了好的基础,您就可以找出用所选语言表达需求的方法。
使用Scala
因为Figaro是一个Scala库,需要Scala的知识才能使用Figaro。本书是关于概率编程的,所以在本书中不教授Scala的知识。Scala的出色学习资源很多,比如Twitter的Scala School。但是为了防止您对Scala不自信,我在本书中对代码中使用的Scala功能加以说明。即使您还不了解Scala,也能够跟上本书的进度。
从概率编程和Figaro中获益并不要求您是一位Scala奇才,在本书中也避免使用一些较为高级和晦涩的特性。但是,增强Scala技能有助于成为更好的Figaro程序员。您甚至会发现,阅读本书也可以提高Scala的技能。
Figaro与Java的对比:构建简单的概率编程系统
为了说明概率编程和Figaro的好处,我将展示以两种方式编写的简单概率应用。首先,我说明用Java(您可能对它很熟悉)编写这种应用的方法。然后,我将展示用Figaro编写的Scala应用。尽管Scala相对Java有一定的优势,但是这不是我要指出的主要差别。关键的思路是,Figaro提供了表示概率模型和用这些模型进行推理的能力,如果没有概率编程,这些能力就不存在。
我们的小应用将作为Figaro的“Hello,World”示例。想象一下,有个人早上起床,查看天气是否晴朗,并根据天气发出问候。每天发出连续两天的问候。而且,第二天的天气取决于第一天:如果第一天是晴天,第二天就更可能是晴天。这些陈述可以由表1-1中的数字量化。
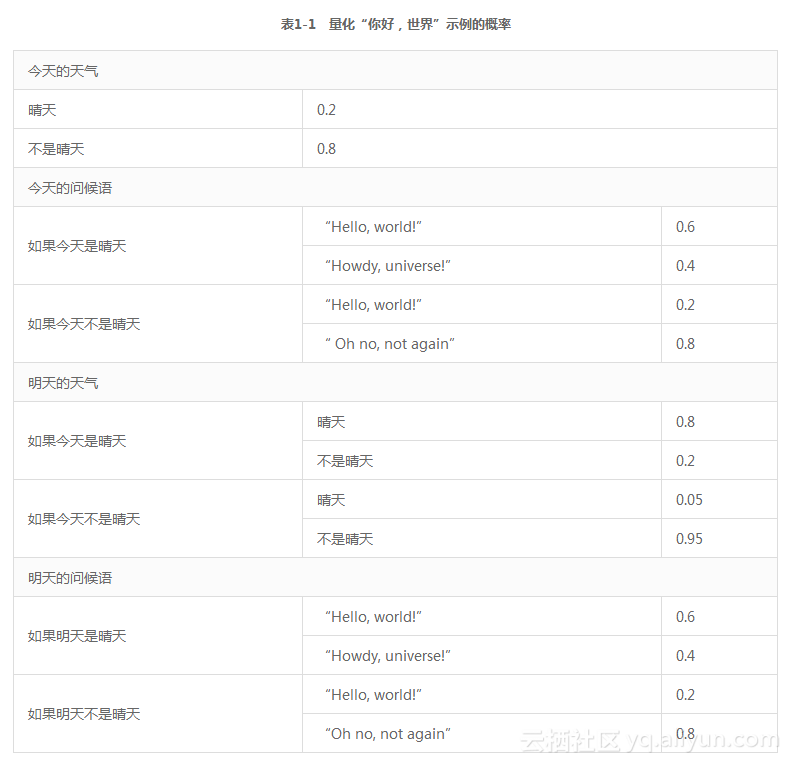
下面几章将明确解释这些数字的含义。现在,我们直观地认为今天是晴天的概率为0.2,也就是说,今天有20%的可能放晴。同样,如果明天是晴天,明天的问候语为“Hello, world!”的概率为0.6,也就是说问候语为“Hello, world!”有60%的可能性,“Howdy, universe!”的可能性为40%。
我们为自己设定了用这个模型执行3种推理任务的目标。在1.1.3小节中您已经知道,用概率模型能够进行3类推理:预测未来,推断导致观测结果的过去事件,从过去事件中学习以更好地预测未来。您将用我们的简单模型完成这三种任务。具体任务如下。
1.预测今天的问候语。
2.如果观测发现今天的问候语是“Hello, world!”,推断今天是不是晴天。
3.从今天对问候语是“Hello, world!”这一观测值的学习,预测明天的问候语。
下面是用Java完成这些任务的方法。
程序清单1-1 用Java实现的Hello World 程序
class HelloWorldJava { ◁——● //定义问候语static String greeting1 = "Hello, world!";static String greeting2 = "Howdy, universe!";static String greeting3 = "Oh no, not again";static Double pSunnyToday = 0.2; ◁——● //指定模型的数值参数static Double pNotSunnyToday = 0.8;static Double pSunnyTomorrowIfSunnyToday = 0.8;static Double pNotSunnyTomorrowIfSunnyToday = 0.2;static Double pSunnyTomorrowIfNotSunnyToday = 0.05;static Double pNotSunnyTomorrowIfNotSunnyToday = 0.95;static Double pGreeting1TodayIfSunnyToday = 0.6;static Double pGreeting2TodayIfSunnyToday = 0.4;static Double pGreeting1TodayIfNotSunnyToday = 0.2;static Double pGreeting3TodayIfNotSunnyToday = 0.8;static Double pGreeting1TomorrowIfSunnyTomorrow = 0.6;static Double pGreeting2TomorrowIfSunnyTomorrow = 0.4;static Double pGreeting1TomorrowIfNotSunnyTomorrow = 0.2;static Double pGreeting3TomorrowIfNotSunnyTomorrow = 0.8;static void predict() { ◁——● //用概率推理规则预测今天的问候语Double pGreeting1Today =pSunnyToday * pGreeting1TodayIfSunnyToday +pNotSunnyToday * pGreeting1TodayIfNotSunnyToday;System.out.println("Today's greeting is " + greeting1 +"with probability " + pGreeting1Today + ".");}static void infer() { ◁——● //按照今天的问候语是“Hello, world!”这一观测值,运用概率推理原则推断今天的天气Double pSunnyTodayAndGreeting1Today =pSunnyToday * pGreeting1TodayIfSunnyToday;Double pNotSunnyTodayAndGreeting1Today =pNotSunnyToday * pGreeting1TodayIfNotSunnyToday;Double pSunnyTodayGivenGreeting1Today =pSunnyTodayAndGreeting1Today /(pSunnyTodayAndGreeting1Today +pNotSunnyTodayAndGreeting1Today);System.out.println("If today's greeting is " + greeting1 +", today's weather is sunny with probability " +pSunnyTodayGivenGreeting1Today + ".");}static void learnAndPredict() { ◁——● //从今天问候语是“Hello, world!”的观测中学习,运用概率推理原则预测明天的问候语Double pSunnyTodayAndGreeting1Today =pSunnyToday * pGreeting1TodayIfSunnyToday;Double pNotSunnyTodayAndGreeting1Today =pNotSunnyToday * pGreeting1TodayIfNotSunnyToday;Double pSunnyTodayGivenGreeting1Today =pSunnyTodayAndGreeting1Today /(pSunnyTodayAndGreeting1Today +pNotSunnyTodayAndGreeting1Today);Double pNotSunnyTodayGivenGreeting1Today =1 - pSunnyTodayGivenGreeting1Today;Double pSunnyTomorrowGivenGreeting1Today =pSunnyTodayGivenGreeting1Today *pSunnyTomorrowIfSunnyToday +pNotSunnyTodayGivenGreeting1Today *pSunnyTomorrowIfNotSunnyToday;Double pNotSunnyTomorrowGivenGreeting1Today =1 - pSunnyTomorrowGivenGreeting1Today;Double pGreeting1TomorrowGivenGreeting1Today =pSunnyTomorrowGivenGreeting1Today *pGreeting1TomorrowIfSunnyTomorrow +pNotSunnyTomorrowGivenGreeting1Today *pGreeting1TomorrowIfNotSunnyTomorrow;System.out.println("If today's greeting is " + greeting1 +", tomorrow's greeting will be " + greeting1 +" with probability " +pGreeting1TomorrowGivenGreeting1Today);} public static void main(String[] args) { ◁——● //执行所有任务的主方法predict();infer();learnAndPredict();}}```
在此,我不对使用推理规则进行计算的方法做出描述。上述代码使用了3条推理规则:链式法则、全概率公式和贝叶斯法则。这些规则将在第9章中详细解释。现在,我们指出这段代码的两个主要问题。无法定义建模所用的规则
模型定义包含在一个变量名与双精度值的列表中。当我在本节的开始描述模型,在表1-1中展示数值时,模型有许多结构,尽管不算很直观,但也算相对容易理解。变量定义的列表毫无结构。变量的含义埋藏在变量名之中,这一定不是好主意。因此,以这种方式记下模型很难,该过程也很容易出错。以后阅读理解和维护这些代码也很困难。如果需要修改模型(例如,问候语还取决于您睡得好不好),就可能需要重写模型的很大一部分。自行编码推理规则很难且容易出错
上述代码的第二个主要问题是使用概率推理规则回答查询。您必须有关于推理规则的详细知识才能编写这段代码。即使有了这种知识,正确编写代码也很难。测试答案是否正确也很困难,而这只是一个极其简单的例子。对于复杂的应用,以此方式创建推理代码可能不现实。下面看看Scala/Figaro代码。程序清单1-2 用Figaro实现的Hello World 程序import com.cra.figaro.language.{Flip, Select}
import com.cra.figaro.library.compound.If
import com.cra.figaro.algorithm.factored.VariableElimination ◁——● //导入Figaro结构
object HelloWorld {
val sunnyToday = Flip(0.2)
val greetingToday = If(sunnyToday,
Select(0.6 -> "Hello, world!", 0.4 -> "Howdy, universe!"), ◁——● //定义模型Select(0.2 -> "Hello, world!", 0.8 -> "Oh no, not again"))val sunnyTomorrow = If(sunnyToday, Flip(0.8), Flip(0.05))
val greetingTomorrow = If(sunnyTomorrow,
Select(0.6 -> "Hello, world!", 0.4 -> "Howdy, universe!"),Select(0.2 -> "Hello, world!", 0.8 -> "Oh no, not again"))
def predict() { ◁——● //用推理算法预测今天的问候语
val result = VariableElimination.probability(greetingToday,"Hello, world!")
println("Today’s greeting is \"Hello, world!\" " +"with probability " + result + ".") ◁——● //根据今天的问候语是“Hello,world!”这一事实,使用推理算法推理今天的天气}
def infer() {greetingToday.observe("Hello, world!")val result = VariableElimination.probability(sunnyToday, true)println("If today's greeting is \"Hello, world!\", today’s " +"weather is sunny with probability " + result + ".")
}def learnAndPredict() { ◁——● //从对今天的问候语是“Hello,world!”这一观察中学习,用推理算法预测明天的问候语greetingToday.observe("Hello, world!")val result = VariableElimination.probability(greetingTomorrow,"Hello, world!")println("If today's greeting is \"Hello, world!\", " +"tomorrow's greeting will be \"Hello, world!\" " +"with probability " + result + ".")
}def main(args: Array[String]) { ◁——● //执行所有任务的主方法predict()infer()learnAndPredict()
}}`
我将等到下一章才详细解释这段代码。现在,我希望指出,它解决了Java代码的两个问题。首先,模型定义准确描述了对应于表1-1的模型结构。您定义了4个变量:sunnyToday、greetingToday、sunnyTomorrow和greetingTomorrow,它们都对应于表1-1。例如,greetingToday的定义如下:
val greetingToday = If(sunnyToday,Select(0.6 -> "Hello, world!", 0.4 -> "Howdy, universe!"),Select(0.2 -> "Hello, world!", 0.8 -> "Oh no, not again"))```
这段代码说明,如果今天是晴天,则问候语为“Hello,world!”的概率为0.6,“Howdy, universe!”的概率是0.4。如果今天不是晴天,问候语为“Hello,world!”的概率为0.2,“Oh no, not again”的概率为0.8。这正是表1-1对今天问候语的规定。因为代码明确地描述了模型,构造、阅读和维护就容易得多了。如果需要更改模型(例如,添加sleepQuality变量),可以用模块化的方式完成。
这篇关于《树莓派开发实战(第2版)》——1.3 Figaro简介:一种概率编程语言的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







