本文主要是介绍理解拉格朗日乘子法(Lagrange Multiplier) 和KKT条件,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
转自(http://blog.csdn.net/xianlingmao/article/details/7919597)
在求取有约束条件的优化问题时,拉格朗日乘子法(Lagrange Multiplier) 和KKT条件是非常重要的两个求取方法,对于等式约束的优化问题,可以应用拉格朗日乘子法去求取最优值;如果含有不等式约束,可以应用KKT条件去求取。当然,这两个方法求得的结果只是必要条件,只有当是凸函数的情况下,才能保证是充分必要条件。KKT条件是拉格朗日乘子法的泛化。之前学习的时候,只知道直接应用两个方法,但是却不知道为什么拉格朗日乘子法(Lagrange Multiplier) 和KKT条件能够起作用,为什么要这样去求取最优值呢?
本文将首先把什么是拉格朗日乘子法(Lagrange Multiplier) 和KKT条件叙述一下;然后开始分别谈谈为什么要这样求最优值。
一. 拉格朗日乘子法(Lagrange Multiplier) 和KKT条件
通常我们需要求解的最优化问题有如下几类:
(i) 无约束优化问题,可以写为:
min f(x);
(ii) 有等式约束的优化问题,可以写为:
min f(x),
s.t. h_i(x) = 0; i =1, ..., n
(iii) 有不等式约束的优化问题,可以写为:
min f(x),
s.t. g_i(x) <= 0; i =1, ..., n
h_j(x) = 0; j =1, ..., m
对于第(i)类的优化问题,常常使用的方法就是Fermat定理,即使用求取f(x)的导数,然后令其为零,可以求得候选最优值,再在这些候选值中验证;如果是凸函数,可以保证是最优解。
对于第(ii)类的优化问题,常常使用的方法就是拉格朗日乘子法(Lagrange Multiplier) ,即把等式约束h_i(x)用一个系数与f(x)写为一个式子,称为拉格朗日函数,而系数称为拉格朗日乘子。通过拉格朗日函数对各个变量求导,令其为零,可以求得候选值集合,然后验证求得最优值。
对于第(iii)类的优化问题,常常使用的方法就是KKT条件。同样地,我们把所有的等式、不等式约束与f(x)写为一个式子,也叫拉格朗日函数,系数也称拉格朗日乘子,通过一些条件,可以求出最优值的必要条件,这个条件称为KKT条件。
(a) 拉格朗日乘子法(Lagrange Multiplier)
对于等式约束,我们可以通过一个拉格朗日系数a 把等式约束和目标函数组合成为一个式子L(a, x) = f(x) + a*h(x), 这里把a和h(x)视为向量形式,a是横向量,h(x)为列向量,之所以这么写,完全是因为csdn很难写数学公式,只能将就了.....。
然后求取最优值,可以通过对L(a,x)对各个参数求导取零,联立等式进行求取,这个在高等数学里面有讲,但是没有讲为什么这么做就可以,在后面,将简要介绍其思想。
(b) KKT条件
对于含有不等式约束的优化问题,如何求取最优值呢?常用的方法是KKT条件,同样地,把所有的不等式约束、等式约束和目标函数全部写为一个式子L(a, b, x)= f(x) + a*g(x)+b*h(x),KKT条件是说最优值必须满足以下条件:
1. L(a, b, x)对x求导为零;
2. h(x) =0;
3. a*g(x) = 0;
求取这三个等式之后就能得到候选最优值。其中第三个式子非常有趣,因为g(x)<=0,如果要满足这个等式,必须a=0或者g(x)=0. 这是SVM的很多重要性质的来源,如支持向量的概念。
二. 为什么拉格朗日乘子法(Lagrange Multiplier) 和KKT条件能够得到最优值?
为什么要这么求能得到最优值?先说拉格朗日乘子法,设想我们的目标函数z = f(x), x是向量, z取不同的值,相当于可以投影在x构成的平面(曲面)上,即成为等高线,如下图,目标函数是f(x, y),这里x是标量,虚线是等高线,现在假设我们的约束g(x)=0,x是向量,在x构成的平面或者曲面上是一条曲线,假设g(x)与等高线相交,交点就是同时满足等式约束条件和目标函数的可行域的值,但肯定不是最优值,因为相交意味着肯定还存在其它的等高线在该条等高线的内部或者外部,使得新的等高线与目标函数的交点的值更大或者更小,只有到等高线与目标函数的曲线相切的时候,可能取得最优值,如下图所示,即等高线和目标函数的曲线在该点的法向量必须有相同方向,所以最优值必须满足:f(x)的梯度 = a* g(x)的梯度,a是常数,表示左右两边同向。这个等式就是L(a,x)对参数求导的结果。(上述描述,我不知道描述清楚没,如果与我物理位置很近的话,直接找我,我当面讲好理解一些,注:下图来自wiki)。
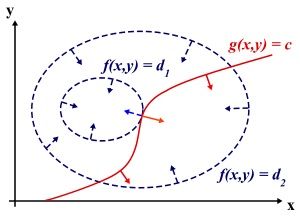
而KKT条件是满足强对偶条件的优化问题的必要条件,可以这样理解:我们要求min f(x), L(a, b, x) = f(x) + a*g(x) + b*h(x),a>=0,我们可以把f(x)写为:max_{a,b} L(a,b,x),为什么呢?因为h(x)=0, g(x)<=0,现在是取L(a,b,x)的最大值,a*g(x)是<=0,所以L(a,b,x)只有在a*g(x) = 0的情况下才能取得最大值,否则,就不满足约束条件,因此max_{a,b} L(a,b,x)在满足约束条件的情况下就是f(x),因此我们的目标函数可以写为 min_x max_{a,b} L(a,b,x)。如果用对偶表达式: max_{a,b} min_x L(a,b,x),由于我们的优化是满足强对偶的(强对偶就是说对偶式子的最优值是等于原问题的最优值的),所以在取得最优值x0的条件下,它满足 f(x0) = max_{a,b} min_x L(a,b,x) = min_x max_{a,b} L(a,b,x) =f(x0),我们来看看中间两个式子发生了什么事情:
f(x0) = max_{a,b} min_x L(a,b,x) = max_{a,b} min_x f(x) + a*g(x) + b*h(x) = max_{a,b} f(x0)+a*g(x0)+b*h(x0) = f(x0)
可以看到上述加黑的地方本质上是说 min_x f(x) + a*g(x) + b*h(x) 在x0取得了最小值,用fermat定理,即是说对于函数 f(x) + a*g(x) + b*h(x),求取导数要等于零,即
f(x)的梯度+a*g(x)的梯度+ b*h(x)的梯度 = 0
这就是kkt条件中第一个条件:L(a, b, x)对x求导为零。
而之前说明过,a*g(x) = 0,这时kkt条件的第3个条件,当然已知的条件h(x)=0必须被满足,所有上述说明,满足强对偶条件的优化问题的最优值都必须满足KKT条件,即上述说明的三个条件。可以把KKT条件视为是拉格朗日乘子法的泛化。
这篇关于理解拉格朗日乘子法(Lagrange Multiplier) 和KKT条件的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




